AMD @ SC15: Boltzmann Initiative Announced - C++ and CUDA Compilers for AMD GPUs
by Ryan Smith on November 16, 2015 8:00 AM EST
The second in our major SC15 announcements comes from AMD, who is taking to the show to focus on the HPC capabilities of their FirePro S line of server cards. Of all of the pre-briefings we’ve sat in on in the past two weeks AMD’s announcement today is by far the most significant. And it’s only fitting then that this happens when SC is taking place in AMD’s backyard: Austin, Texas.
So what has AMD so excited for SC15? In short the company is about to embark on a massive overhaul of their HPC software plans. Dubbed the Boltzmann Initiative – after father of statistical mechanics Ludwig Boltzmann – AMD will be undertaking a much needed redevelopment effort of their HPC software ecosystem in order to close the gap with NVIDIA and offer an environment competitive (and compatible!) with CUDA. So with that in mind, let’s jump right in.

Headless Linux & HSA-based GPU Environment
Perhaps the cornerstone of the Boltzmann Initiative is with AMD’s drivers, which are being improved and overhauled to support AMD’s other plans. The company will be building a dedicated 64-bit Linux driver specifically for headless operation under Linux. It’s only been in the last year that AMD has really focused on headless Linux operation – prior to that headless OpenCL execution was a bit of a hack – and with the new driver AMD completes what they’ve started.

But more importantly than that, the headless Linux driver will be implementing an HSA extended environment, which will bring with it many of the advantages of the Heterogeneous System Architecture to AMD’s FirePro discrete GPUs. This environment, which AMD is calling HSA+, builds off of the formal HSA standard by adding extensions specifically to support HSA with discrete GPUs. The extensions themselves are going to be non-standard – the HSA Foundation has been focused on truly integrated devices ala APUs, and it doesn’t sound like these extensions will be accepted upstream into mainstream HSA any time soon – but AMD will be releasing the extensions as an open source project in the future.
The purpose of extending HSA to dGPUs, besides meeting earlier promises, is to bring as many of the benefits of the HSA execution model to dGPUs as is practical. For AMD this means being able to put HSA CPUs and dGPUs into a single unified address space – closing a gap with NVIDIA since CUDA 6 – which can significantly simplify programming for applications which are actively executing work on both the CPU and the GPU. Using the HSA model along with this driver also allows AMD to address other needs such as bringing down dispatch latency and improving support/performance for large clusters where fabrics such as InfiniBand are being used to link together the nodes in a cluster. Combined with the basic abilities of the new driver, AMD is in essence laying some much-needed groundwork to offer a cluster feature set more on-par with the competition.
Heterogeneous Compute Compiler – Diverging From OpenCL, Going C++
The second part of the Boltzmann Imitative is AMD’s new compiler for HPC, the Heterogeneous Compute Compiler. Built on top of work the company has already done for their HSA compiler, the HCC will be the first of AMD’s two efforts to address the programming needs of the HPC user base, who by and large has passed on AMD’s GPUs in part for a lackluster HPC software environment.
As a bit of background here before going any further, one of the earliest advantages for NVIDIA and CUDA was supporting C++ and other high-level programming languages at a time when OpenCL could only support a C-like syntax, and programming for OpenCL was decidedly at a lower level. AMD meanwhile continued to back OpenCL, in part in order to support an open ecosystem, and while OpenCL made great strides with the provisional release of OpenCL 2.1 and OpenCL C++ kernel language this year, in a sense the damage has been done. OpenCL sees minimal use in the HPC space, and further complicating matters is the fact that not all of the major vendors support OpenCL 2.x. AMD for their part is polite enough not to name names, but at this point the laggard is well known to be NVIDIA, who only supports up to OpenCL 1.2 (and seems to be in no rush to support anything newer).

As a result of these developments AMD is altering their software strategy, as it’s clear that the company can no longer just bank on OpenCL for their HPC software API needs. I hesitate to say that AMD is backing away from OpenCL at all, as in our briefings AMD made it clear that they intend to continue to support OpenCL, and based on their attitude and presentation this doesn’t appear to be a hollow corporate boilerplate promise in order to avoid rocking the boat. But there’s a realization that even if OpenCL delivers everything AMD ever wanted, it’s hard to leverage OpenCL when support for the API is fragmented and when aspects of OpenCL C++ are still too low level, so AMD will simultaneously be working on their own API and environment.
This environment will be built around the Heterogeneous Compute Compiler. In some ways AMD’s answer to CUDA, the HCC is a single C/C++/OpenMP compiler for both the CPU and the GPU. Like so many recent compiler projects, AMD will be leveraging parts of Clang and LLVM to handle the compilation, along with portions of HSA as previously described to serve as the runtime environment.
The purpose of the HCC will be to allow developers to write CPU and/or GPU code using a single compiler, in a single language, inside a single source file. The end result is something that resembles Microsoft’s C++ AMP, with developers simply making parallel calls within a C++ program as they see fit. Perhaps most importantly for AMD and their prospective HPC audience, HCC means that a separate source file for GPU kernels is not needed, a limitation that continues to exist right up to OpenCL++.

An Example of HCC Code (Source)
Overall HCC will expose parallelism in two ways. The first of which is through explicit syntax for parallel operations, ala-C++ AMP, with developers calling parallel-capable functions such as parallel_for_each to explicitly setup segments of code that can be run in parallel and how that interacts with the rest of the program, with this functionality built around C++ lambda code. The second method, at an even higher level, will be to leverage the forthcoming Parallel STL (Standard Template Library), which is slated to come with C++ 17. The Parallel STIL will contain a number of parallelized standard functions for GPU/accelerator execution, making things even simpler for developers as they no longer need to explicitly account for and control certain aspects of parallel execution, and can use the STL functions as a base for modification/extension.
Ultimately HCC is intended to modernize GPU programming for AMD GPUs and to bring some much-desired features to the environment. Along with the immediate addition of basic parallelism and standard parallel functions, the HCC will also include some other features specifically for improving performance on GPUs and other accelerators. This includes support for pre-fetching data, asynchronous compute kernels, and even scratchpad memories (i.e. the AMD LDS Local Data Share). Between these features, AMD is hopeful that they can offer the kind of programming environment that HPC users have wanted, an environment that is more welcoming to new HPC programmers, and an environment that is more welcoming to seasoned CUDA programmers as well.
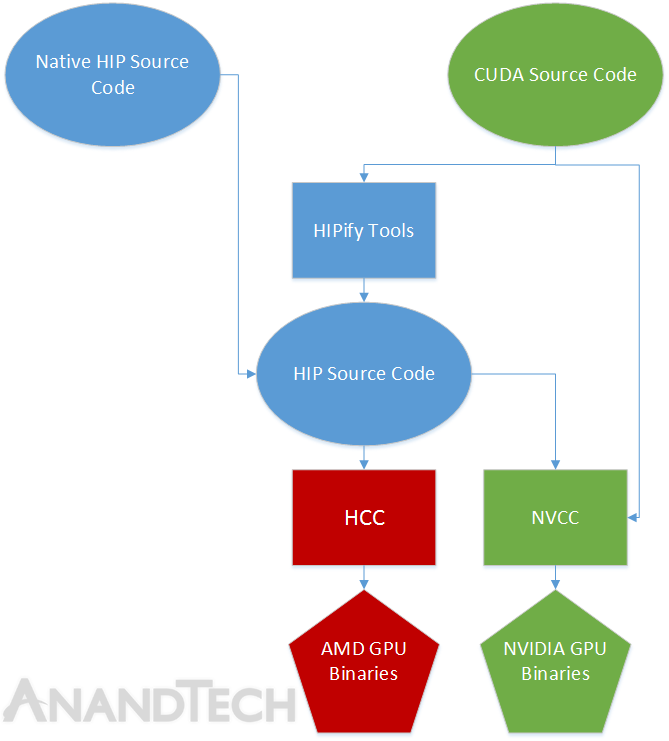
Heterogeneous-compute Interface for Portability (HIP) – CUDA Compilation For AMD GPUs
Last but certainly not least in the Boltzmann Initiative is AMD’s effort to fully extend a bridge into the world of CUDA developers. With HCC to bring AMD’s programming environment more on par with what CUDA developers expect, AMD realizes that just being as good as NVIDIA won’t always be good enough, that developers accustomed to the syntax of CUDA won’t want to change, and that CUDA won’t be going anywhere anytime soon. The solution to that problem is the Heterogeneous-compute Interface for Portability, otherwise known as HIP, which gives CUDA developers the tools they need to easily move over to AMD GPUs.

Through HIP AMD will bridge the gap between HCC and CUDA by giving developers a CUDA-like syntax – the various HIP API commands – allowing developers to program for AMD GPUs in a CUDA-like fashion. Meanwhile HIP will also including a toolset (the HIPify Tools) that further simplifies porting by automatically converting CUDA code to HIP code. And finally, once code is HIP – be it natively written that way or converted – it can then be compiled to either NVIDIA or AMD GPUs through NVCC (using a HIP header file to add HIP support) or HCC respectively.
To be clear here, HIP is not a means for AMD GPUs to run compiled CUDA programs. CUDA is and remains an NVIDIA technology. But HIP is the means for source-to-source translation, so that developers will have a far easier time targeting AMD GPUs. Given that the HPC market is one where developers are typically writing all of their own code here anyhow and tweaking it for the specific architecture it’s meant to run on, a source-to-source translation covers most of AMD’s needs right there, and retains AMD’s ability to compile CUDA code from a high level where they can better optimize that code for their GPUs.
Now there are some unknowns here, including whether AMD can keep HIP up to date with CUDA feature additions, but more importantly there’s a question of just what NVIDIA’s reaction will be. CUDA is NVIDIA’s, through and through, and it does make one wonder whether NVIDIA would try to sue AMD for implementing the CUDA API without NVIDIA’s permission, particularly in light of the latest developments in the Oracle vs. Google case on the Java API. AMD for their part has had their legal team look at the issue extensively and doesn’t believe they’re at risk – pointing in part to Google’s own efforts to bring CUDA support to LLVM with GPUCC – though I suspect AMD’s efforts are a bit more inflammatory given the direct competition. Ultimately it’s a matter that will be handled by AMD and NVIDIA only if it comes to it, but it’s something that does need to be pointed out.
Otherwise by creating HIP AMD is solving one of the biggest issues that has hindered the company’s HPC efforts since CUDA gained traction, which is the fact that they can’t run CUDA. A compatibility layer against a proprietary API is never the perfect solution – AMD would certainly be happier if everyone could and did program in standard C++ – but there is a sizable user base that has grown up on CUDA and is at this point entrenched with it. And simply put AMD needs to have CUDA compatibility if they wish to wrest HPC GPU market share away from NVIDIA.

Wrapping things up then, with the Boltzmann Initiative AMD is taking an important and very much necessary step to redefine themselves in the HPC space. By providing an improved driver layer for Linux supporting headless operation and a unified memory space, with a compiler for direct, single source C++ compilation on top of that, and a CUDA compatibility layer to reach the established CUDA user base, AMD Is finally getting far more aggressive on the HPC side of matters, and making the moves that many have argued they have needed to make for quite some time. At this point AMD needs to deliver on their roadmap and to ensure they deliver quality tools in the process, and even then NVIDIA earned their place in the HPC space through good products and will not be easily dislodged – CUDA came at exactly the time when developers needed it – but for AMD if they can execute on Boltzmann it will be the first time in half a decade they would have a fighting chance at tapping into the lucrative and profitable HPC market.






Source: AMD








20 Comments
View All Comments
nathanddrews - Monday, November 16, 2015 - link
Clever play on words or typo:"Wrapping things up then, with the Boltzmann Imitative..."
NVIDIA seems so entrenched, I wish AMD luck on this one!
Ryan Smith - Monday, November 16, 2015 - link
The cleverness is all MS Word's on that one. That's what it corrected my typo as.IanHagen - Monday, November 16, 2015 - link
Yes, yes, there's no mistake. nVidia must've bribed Microsoft to twist articles in their favour, given that they cannot compete against AMD's brilliant designs fair and square. If only there would be justice on the land!Ryan Smith - Monday, November 16, 2015 - link
On a semi-related note, I misread the name as the "Bozeman Initiative" the first time around and was disappointed that it was Boltzmann. AMD missed an obvious opportunity for a combination Star Trek + GPU threading joke: "AMD Begins Bozeman Initiative: Acquires NVIDIA Warp Technology"ant6n - Monday, November 16, 2015 - link
The Bozeman was stuck for 90 years in a time loop, not sure you'd want that association.Wreckage - Monday, November 16, 2015 - link
CUDA support could also lead to Physx support. This could lead to greater adoption in games which will in turn make games better.VoraciousGorak - Monday, November 16, 2015 - link
It's not really "CUDA support" as much as it is the ability to easily recompile CUDA code to work with AMD GPUs. Likewise, PhysX is NVIDIA IP, so they're not likely to give it up anytime soon.WhisperingEye - Tuesday, November 17, 2015 - link
I thought the consoles recieved PhysX support, despite the host GPU.WaitingForNehalem - Monday, November 16, 2015 - link
It's about time!asmian - Monday, November 16, 2015 - link
>"Developed core principals" - second slide, "Why Boltzmann"OUCH! I hope that wasn't a public presentation slide... The curse of the auto-correct again, perhaps, but it shouldn't get past a PR team.