Khronos Announces OpenCL SPIR 2.0
by Ryan Smith on August 11, 2014 9:00 AM EST
The last time we talked to Khronos about the OpenCL Standard Portable Intermediate Representation (SPIR) was back at SIGGRAPH 2013. At the time Khronos was gearing up for the release of the first iteration of SPIR, then based on the OpenCL 1.2 specification. By building an intermediate representation for OpenCL, Khronos was aiming to expand the capabilities of OpenCL and its associated runtime, both by offering a method of distributing programs in a more developer-friendly “non-source” form, and by allowing languages other than OpenCL’s dialect of C to build upon the OpenCL runtime.
At the time of its announcement, Khronos released OpenCL SPIR 1.2 as a provisional specification, keeping it there over a protracted period to solicit feedback over the first version of the standard. Since that provisional release, Khronos finalized OpenCL 1.2 SPIR in early 2014 and has been working on building up their developer and user bases for SPIR.
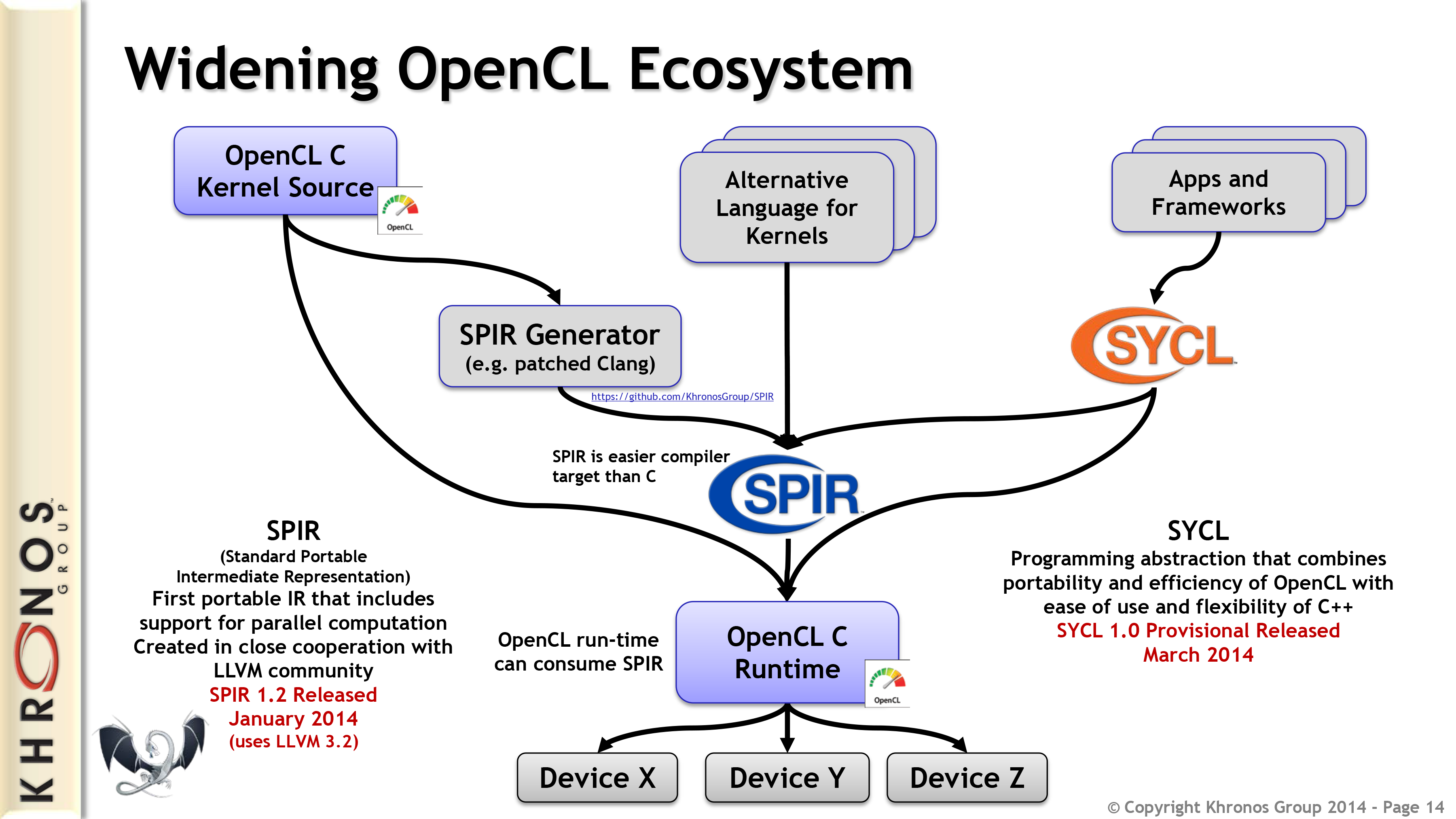
Which brings us to SIGGRAPH 2014 and Khronos’s latest round of specification updates. With OpenCL 2.0 already finalized and device makers scheduled to deliver the first runtimes a bit later this year, Khronos has now turned their attention towards updating SPIR to take advantage of OpenCL 2.0’s greater functionality. To that end, today Khronos is announcing the provisional specification for the next version of SPIR, OpenCL SPIR 2.0.
With much of the groundwork for SPIR already laid out on SPIR 1.2, SPIR 2.0 is a (generally) straightforward update to the specification to integrate OpenCL 2.0 functionality. OpenCL 2.0 in turn is the biggest upgrade to OpenCL since its introduction, adding several major features to the API to keep pace with functionality offered by the latest generations of GPUs.

As a quick recap, OpenCL 2.0’s headline features dynamic parallelism (device side kernel enqueue), shared virtual memory, and support for a generic address space. Dynamic parallelism allows kernels running on a device (e.g. GPU) to issue additional kernels without going through the host, reducing host bottlenecks. Meanwhile shared virtual memory allows for the host and device to share complex data, including memory pointers, executing and using data without the need to explicitly transfer it from host to device and vice versa. This feature is especially important for the HSA Foundation, as this is one of the critical features for enabling HSA execution on OpenCL. Finally generic address space support alleviates the need to write a version of a function for each named address space. Instead a single generic function can handle working with all of the named address spaces, simplifying development and cutting down on the amount of code that needs to be cached for execution.
With these functions finally exposed through SPIR, they can be tapped in to by all SPIR developers – both those developers looking to distribute their programs in intermediate form, and for developers using OpenCL as a backend for their own languages. In the case of the latter SPIR 2.0 should be especially interesting, as these feature additions make SPIR a more versatile backend that’s better capable of efficiently executing more complex languages.

In keeping with their goals of providing common, open standard APIs, in the long run it is Khronos’s hope that OpenCL and SPIR will become the runtime of choice for GPU applications. By building up a robust runtime and set of tools through SPIR, language developers can simply target SPIR rather than needing to develop against multiple different hardware devices; and meanwhile device manufacturers can focus on tightly optimizing their OpenCL runtime rather than juggling with supporting several disparate runtimes. To that end Khronos is claiming that they’re up to nearly 200 languages and frameworks that will be capable of using SPIR, including a few high-profile languages such as C++ AMP, Python, and OpenACC.
However from a PC standpoint Khronos still faces an uphill battle, and it will be interesting to see whether SPIR 2.0 runs into the same difficulties as SPIR 1.2 did. NVIDIA for their part never did fully support OpenCL 1.2, and as a result SPIR 1.2 couldn’t be used on NVIDIA’s products, preventing SPIR’s use on what’s a significant majority of high-performance discrete GPUs. So far we have not seen NVIDIA comment much on OpenCL 2.0 (though it’s interesting to note that Khronos president Neil Trevett is an NVIDIA employee); so SPIR’s success may hinge on whether NVIDIA chooses to fully support OpenCL 2.0 and SPIR.
NVIDIA for their part has their competing CUDA ecosystem, and like Khronos they are leveraging LLVM to allow for 3rd party languages and frameworks to compile down to PTX (NVIDIA’s intermediate language). For languages and frameworks utilizing LLVM this opens the door to compiling code down to both SPIR and PTX, but it’s a door that swings both ways since it diminishes the need for NVIDIA to support SPIR (never mind OpenCL 2.0). For their parts, AMD and Intel will be fully backing OpenCL 2.0 and SPIR 2.0, so it remains to be seen whether NVIDIA finally comes on board with SPIR 2.0 after essentially skipping out on 1.2.










1 Comments
View All Comments
MrSpadge - Wednesday, August 13, 2014 - link
I really like nVidias Maxwell architecture, and probably also what's about to come next. But the lack of any serious OpenCL support from their side is a major drawback for me.