Hot Chips 2021 Live Blog: DPU + IPUs (Arm, NVIDIA, Intel)
by Dr. Ian Cutress on August 23, 2021 5:20 PM EST- Posted in
- SoCs
- Intel
- Arm
- Trade Shows
- NVIDIA
- Neoverse
- DPU
- IPU
- Hot Chips 33
- SmartNIC

05:27PM EDT - Welcome to Hot Chips! This is the annual conference all about the latest, greatest, and upcoming big silicon that gets us all excited. Stay tuned during Monday and Tuesday for our regular AnandTech Live Blogs.
05:30PM EDT - Just waiting for this session to start, should be a couple of minutes
05:30PM EDT - Arm up first with its Neoverse N2 cores


05:34PM EDT - Roadmap, objectives, core architecture, system architecture, performance, conclusions
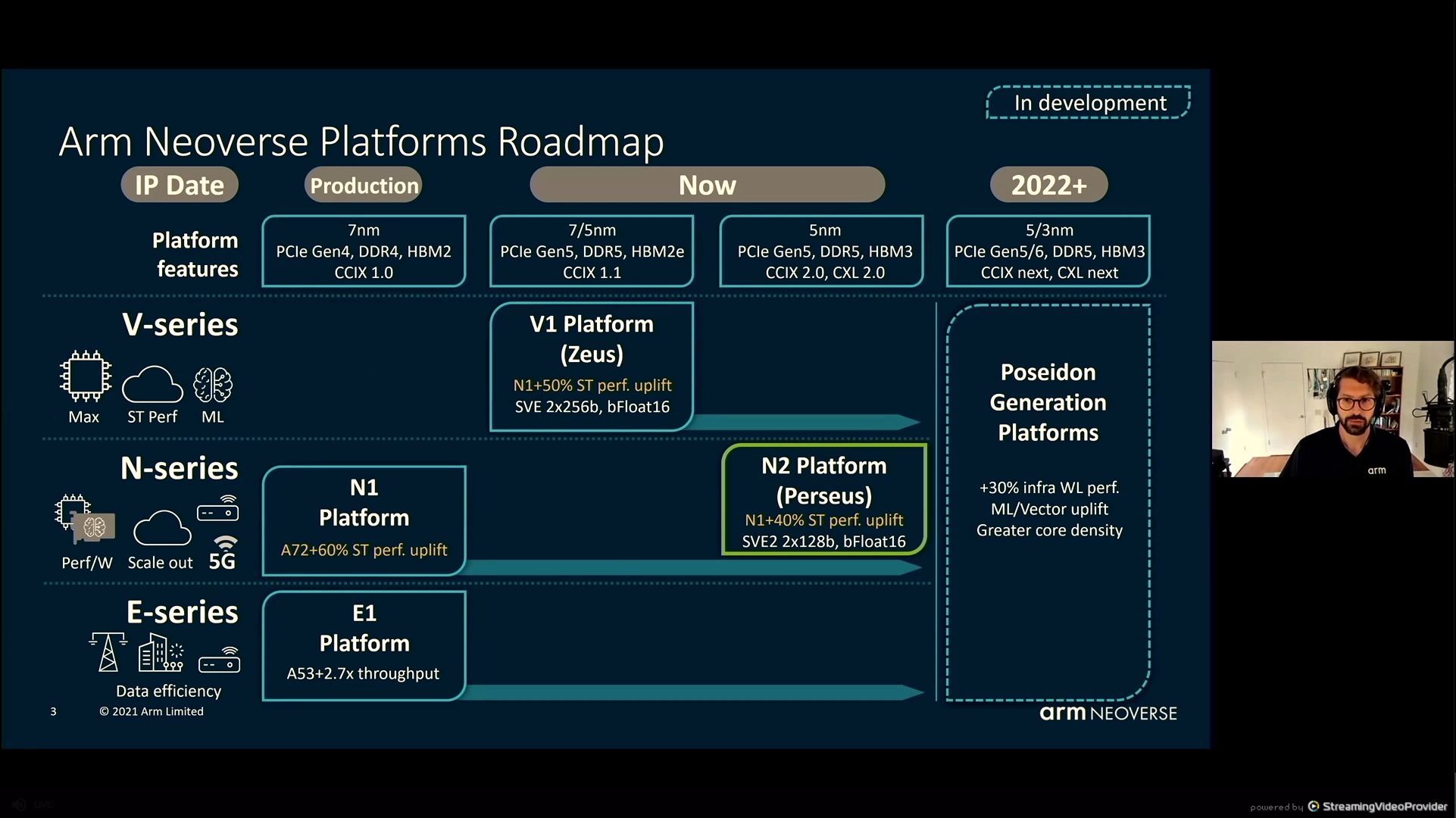
05:34PM EDT - Second generation infrastructure followiung N1
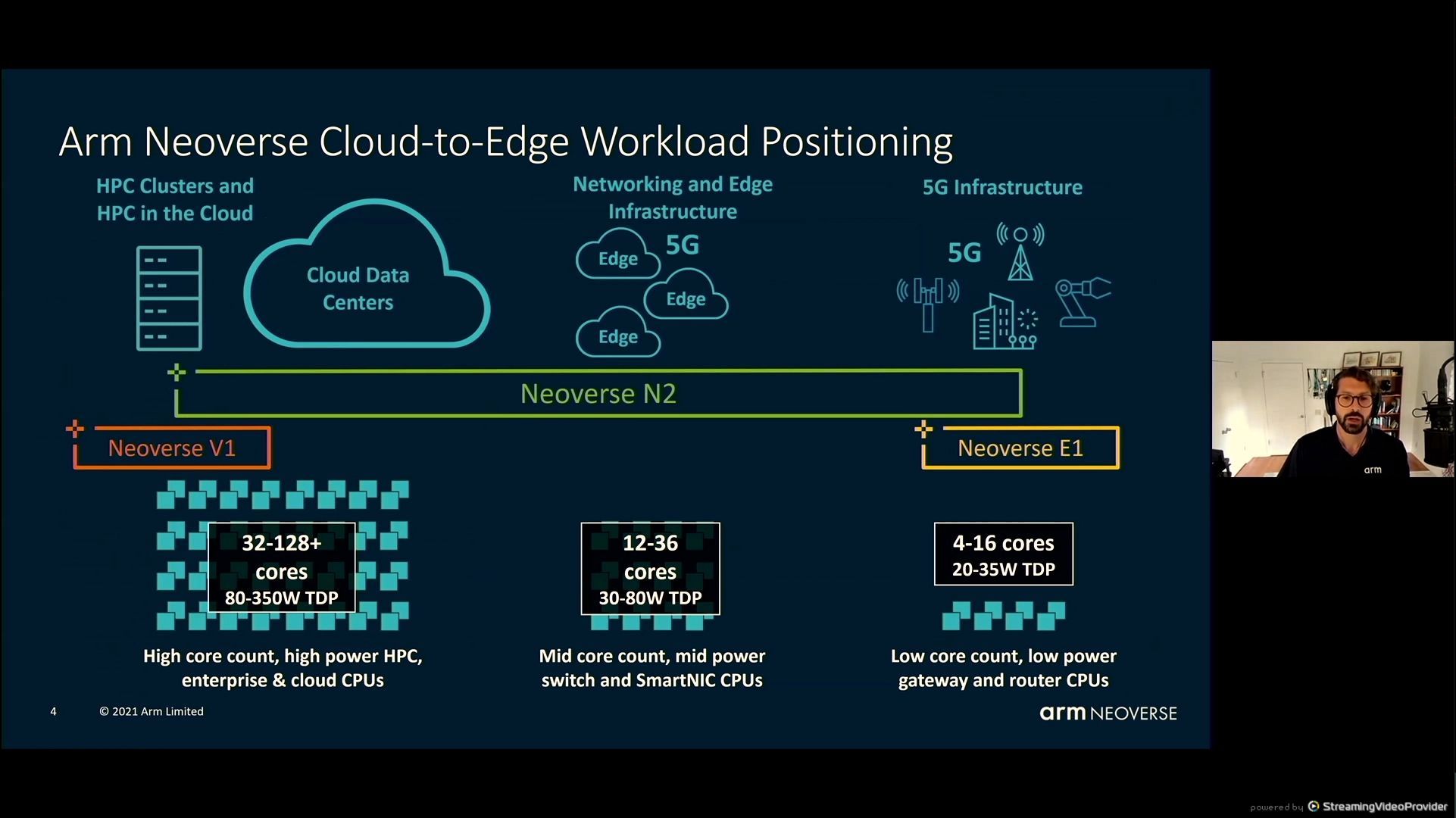
05:34PM EDT - 4-128 core designs
05:35PM EDT - 5G infrastructure to cloud data centers
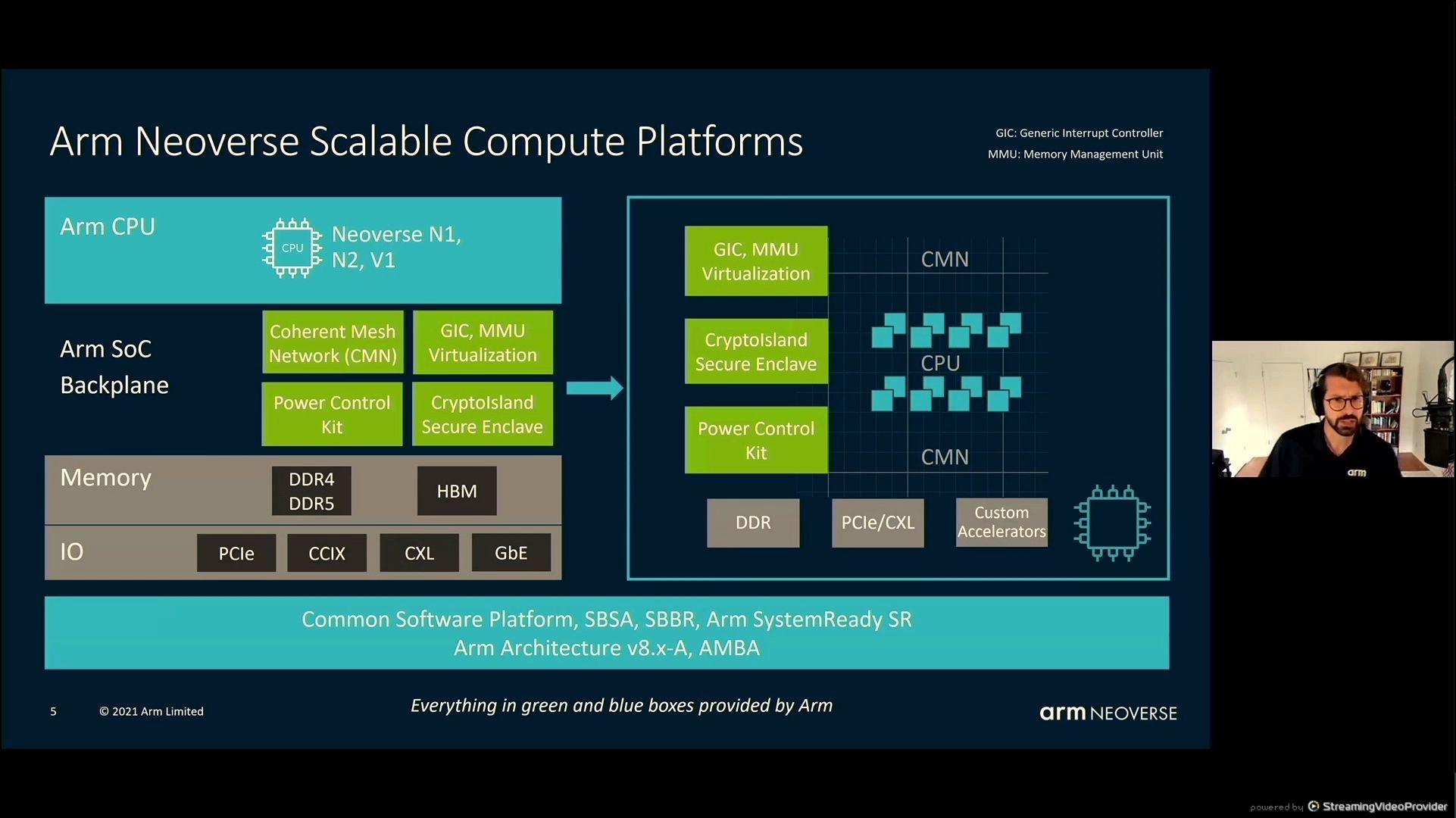
05:35PM EDT - Arm sells IP and definitions
05:35PM EDT - SBSA/SBBR support

05:36PM EDT - Marvell is already using N2, up to 36 in an SoC
05:36PM EDT - High speed packet processing

05:36PM EDT - All about SpecINT score with DDR5 and PCIe 5.0

05:37PM EDT - N2 with Arm v9
05:37PM EDT - Two lots of Scalable Vector Extensions, SVE, SVE2
05:37PM EDT - BF16 support, INT8 mul
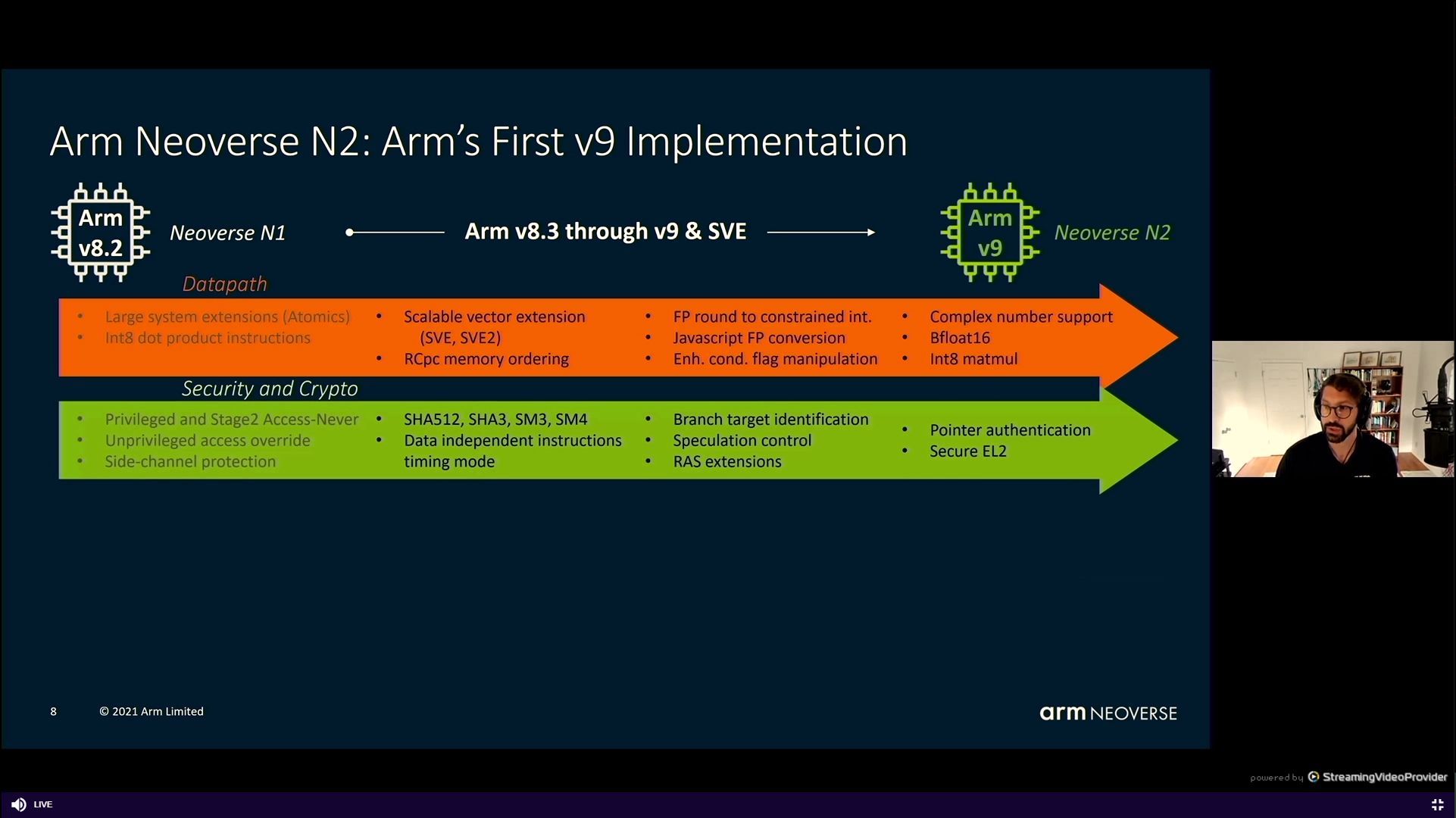
05:38PM EDT - Side channel security, SHA, SM3/4
05:38PM EDT - *SHA3/SHA512
05:38PM EDT - Persistent memory support
05:38PM EDT - memory partition and monitoring
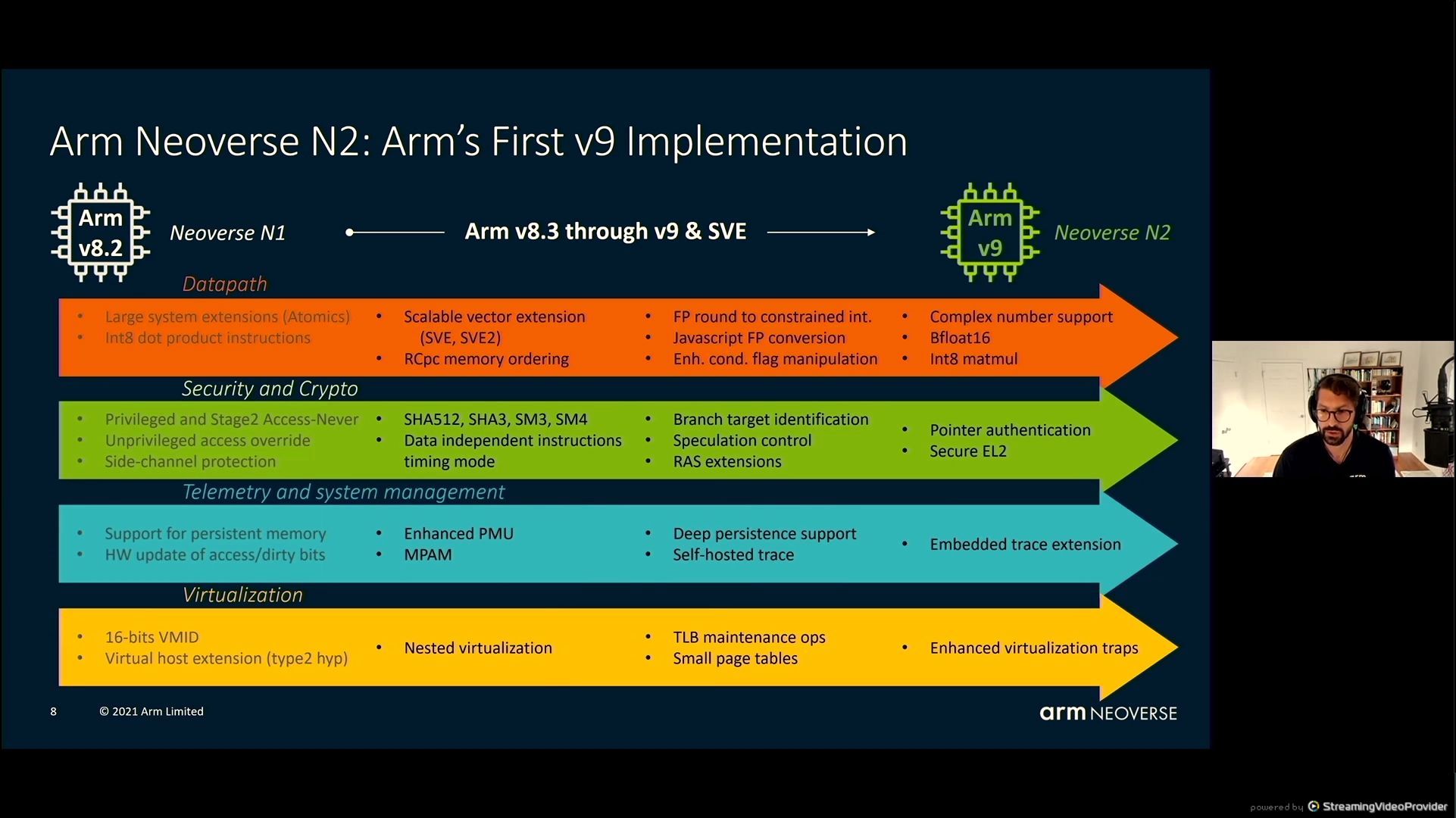
05:39PM EDT - Gen on gen improvements with virtualization
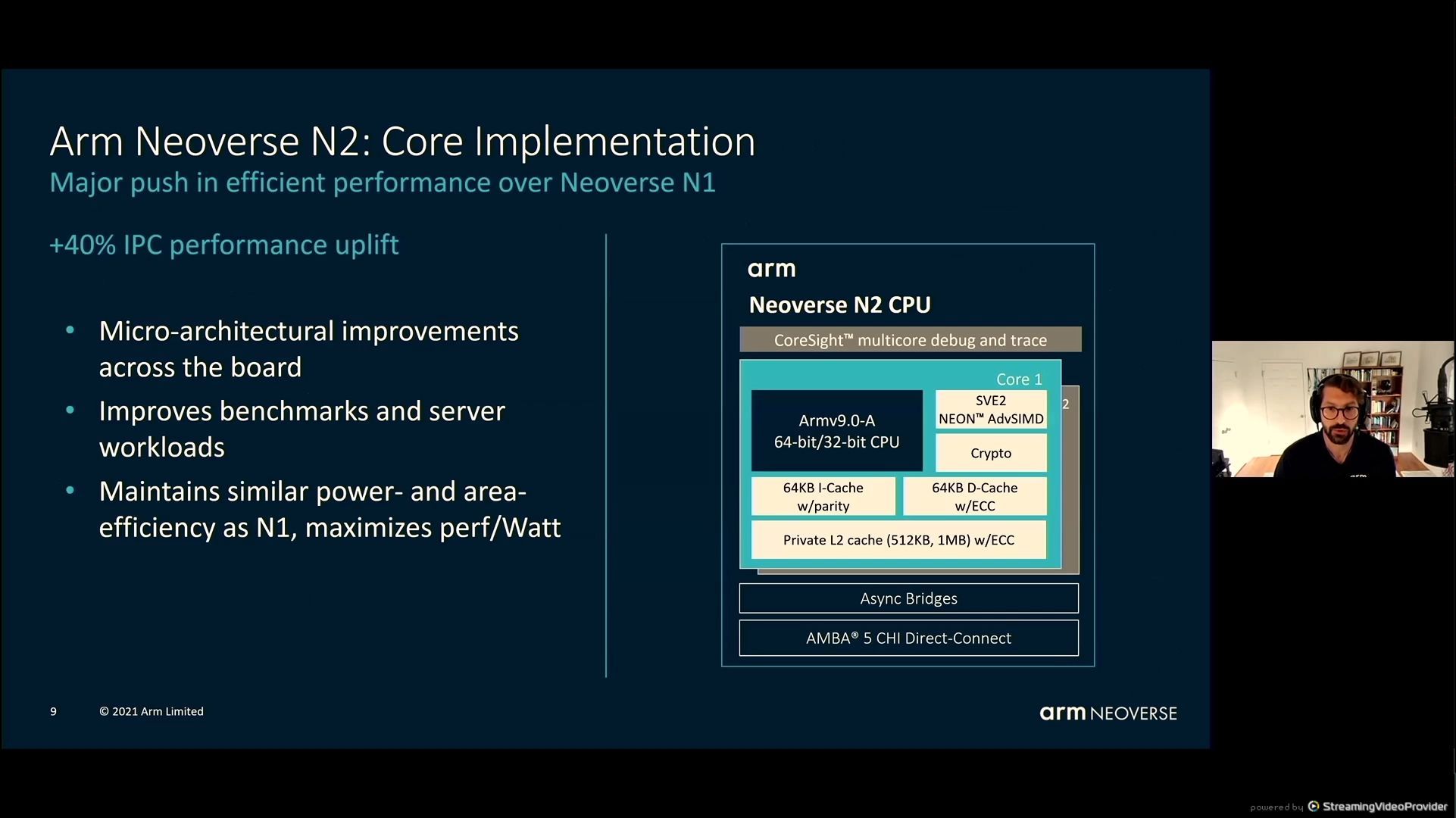
05:39PM EDT - +40% IPC uplift
05:39PM EDT - Similar power/area as N1, maximizes perf/Watt
05:39PM EDT - an intense PPA trajectory
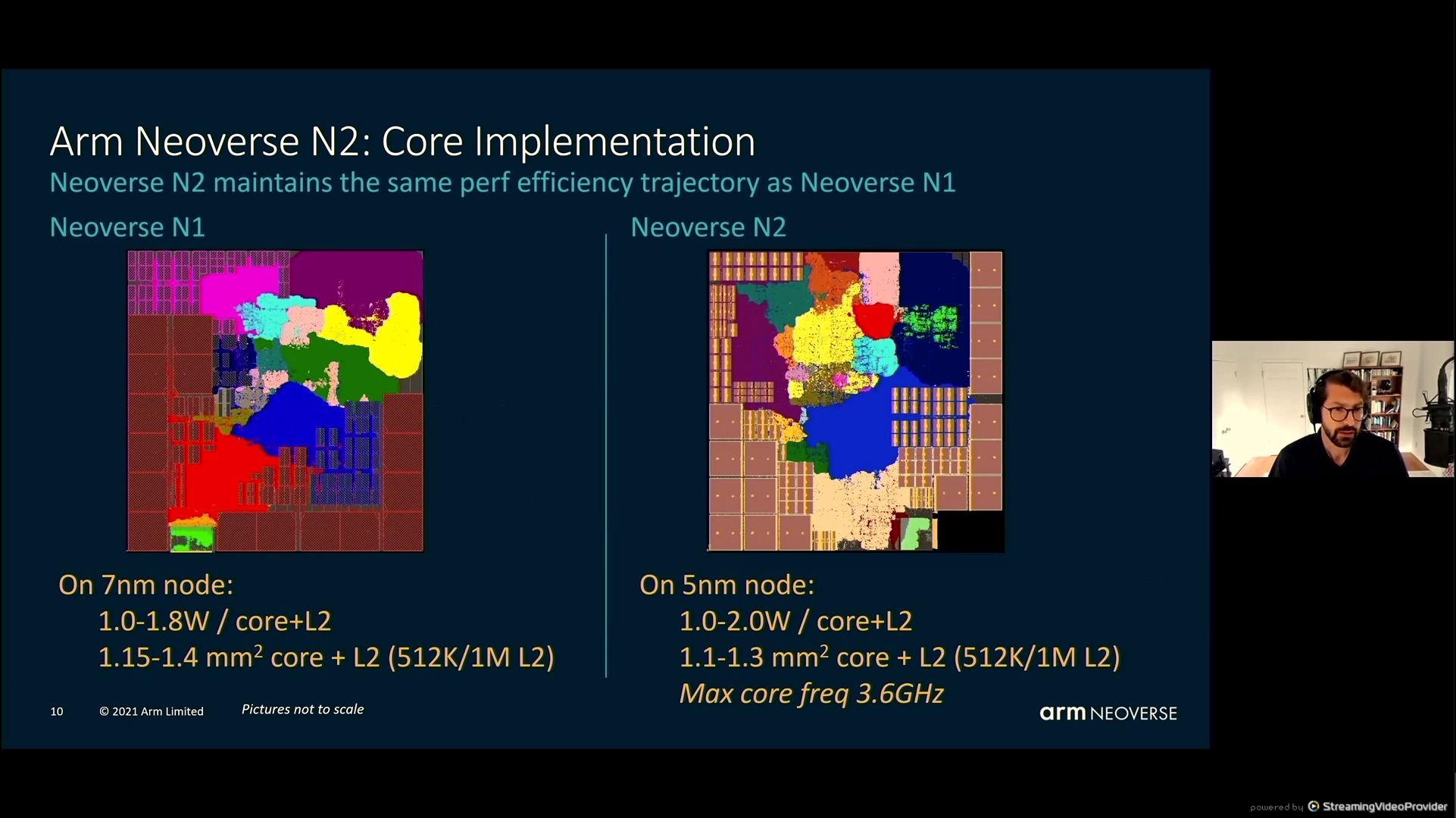
05:40PM EDT - 3.6 GHz max core frequency
05:40PM EDT - N1 on 7nm, vs N2 on 5nm
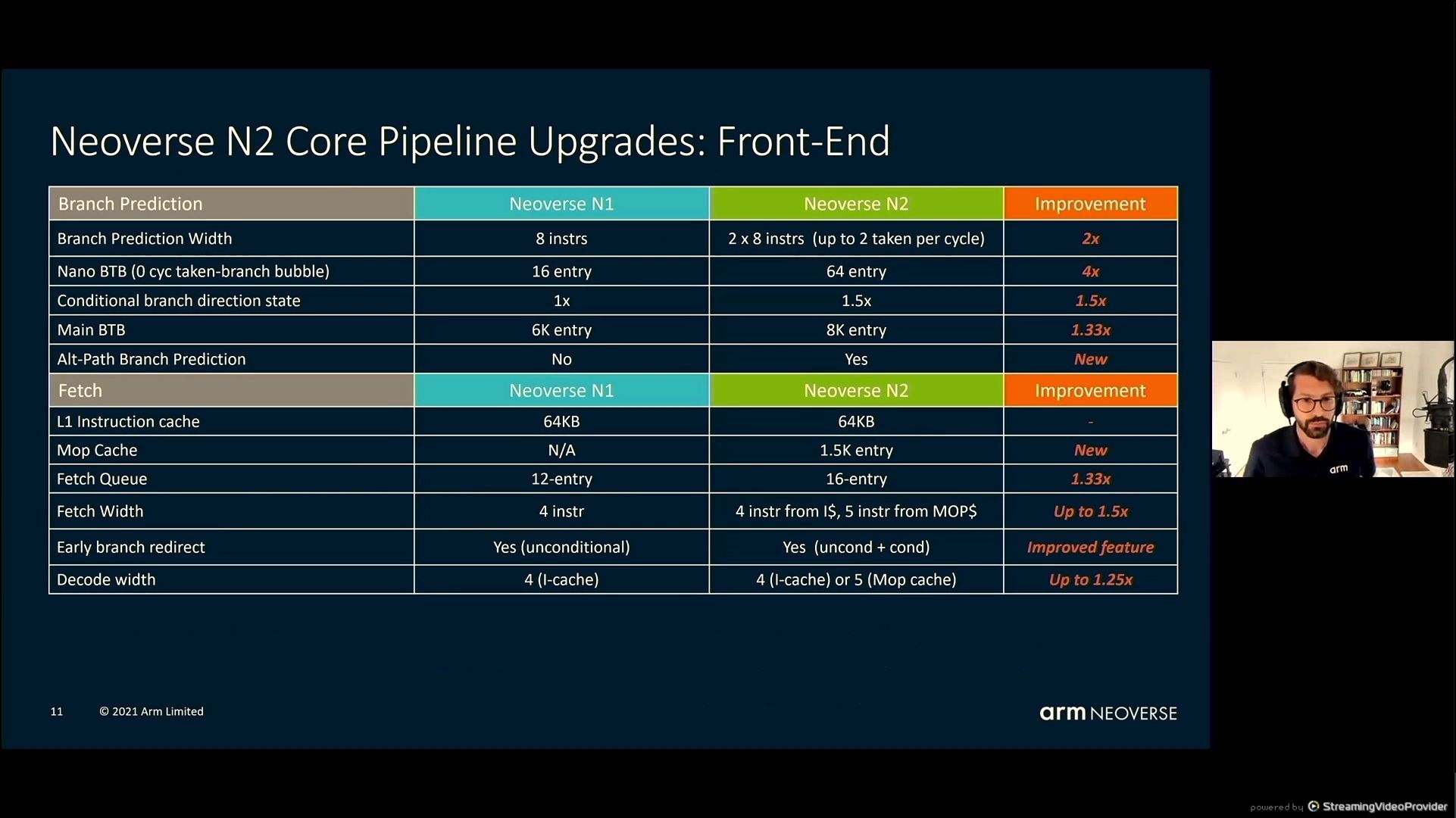
05:41PM EDT - uArch - Most structures are biggers
05:41PM EDT - bigger
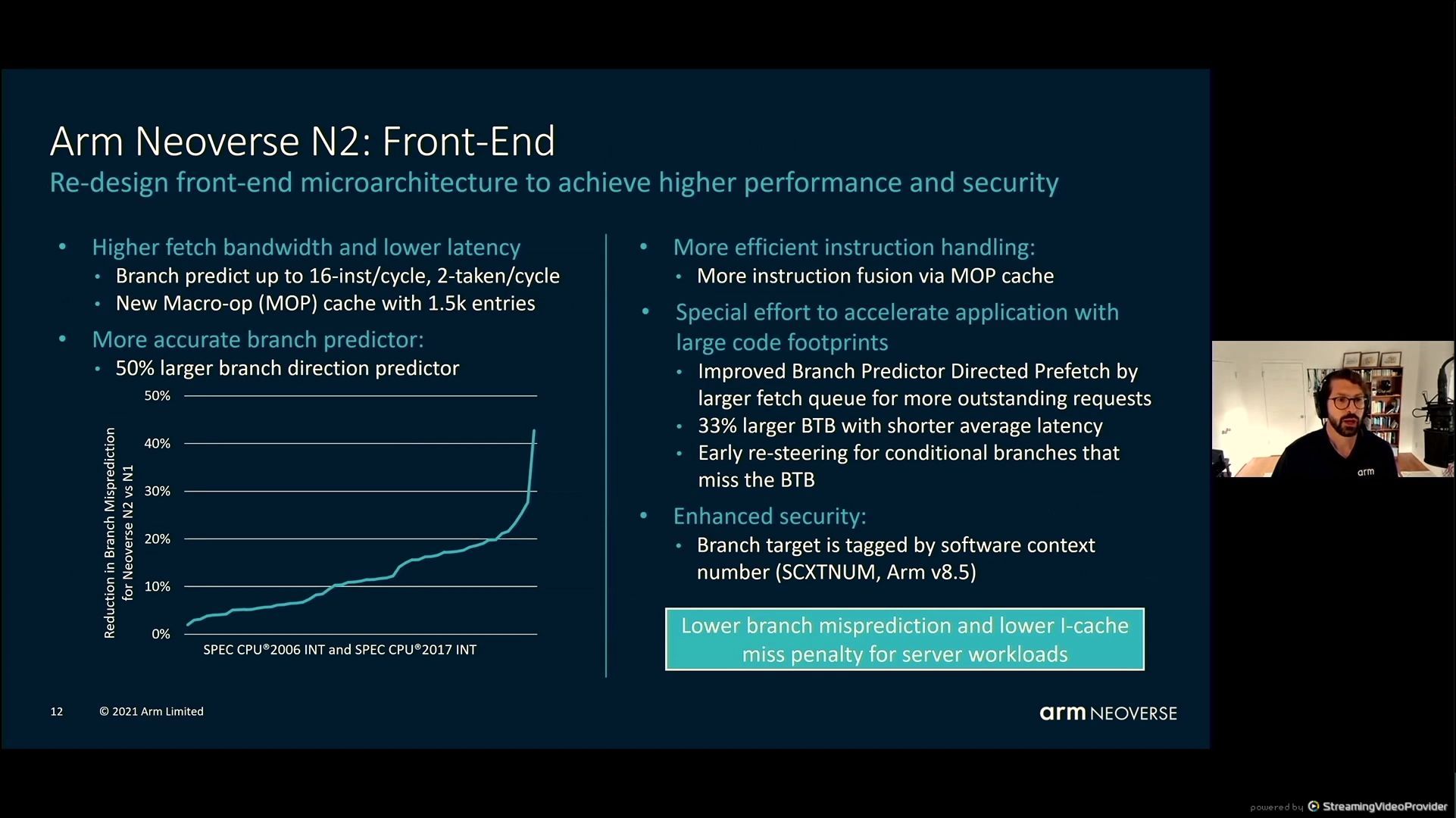
05:42PM EDT - Fetch more per cycle on the front end - increase branch prediction accuracy
05:42PM EDT - Enhanced security to prevent side-channel
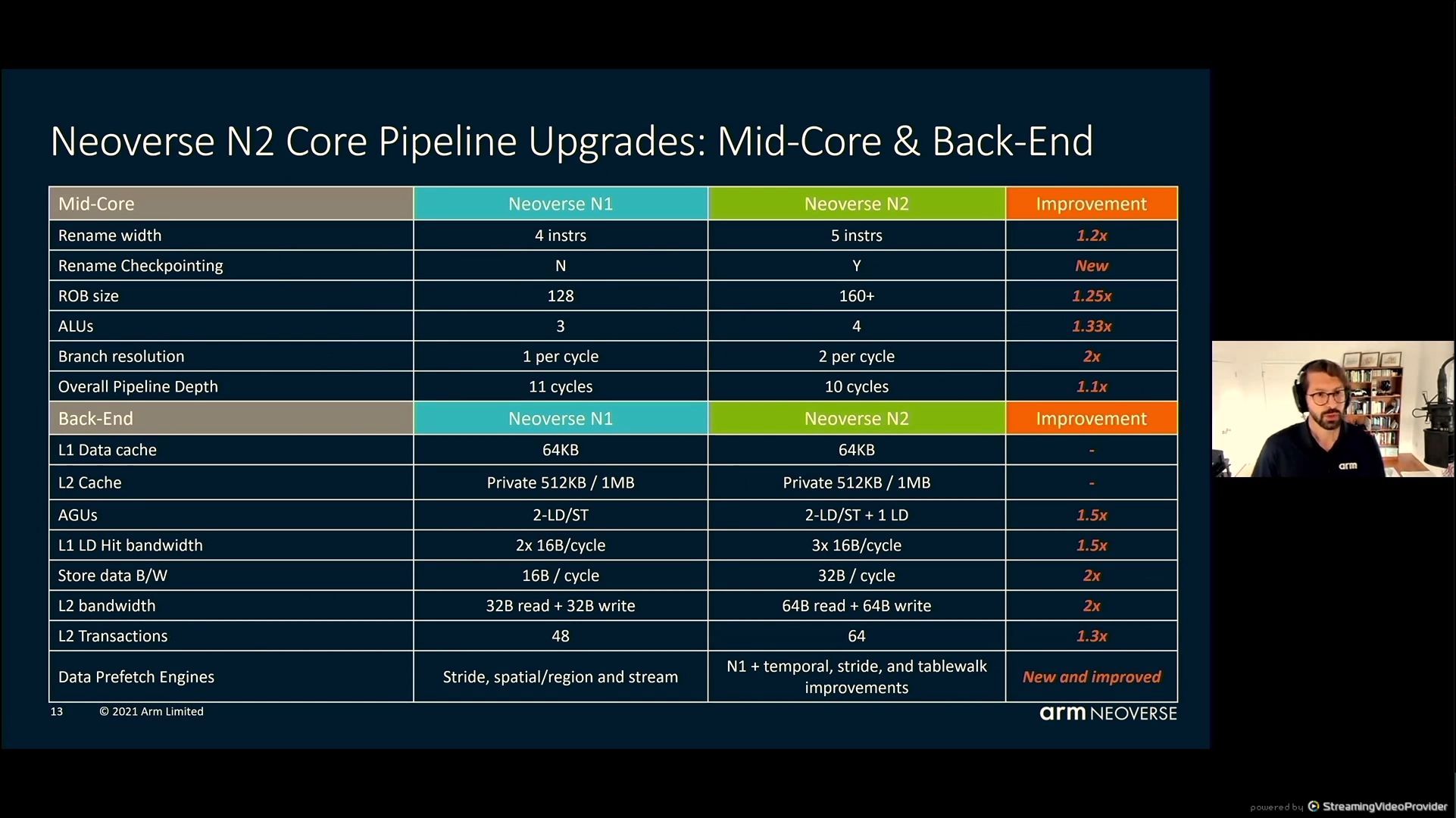
05:43PM EDT - More bigger structures on the back end
05:44PM EDT - N2 has Correlated Miss Caching (CMC) prefetching

05:45PM EDT - Latency improvement on L2 as a result of CMC
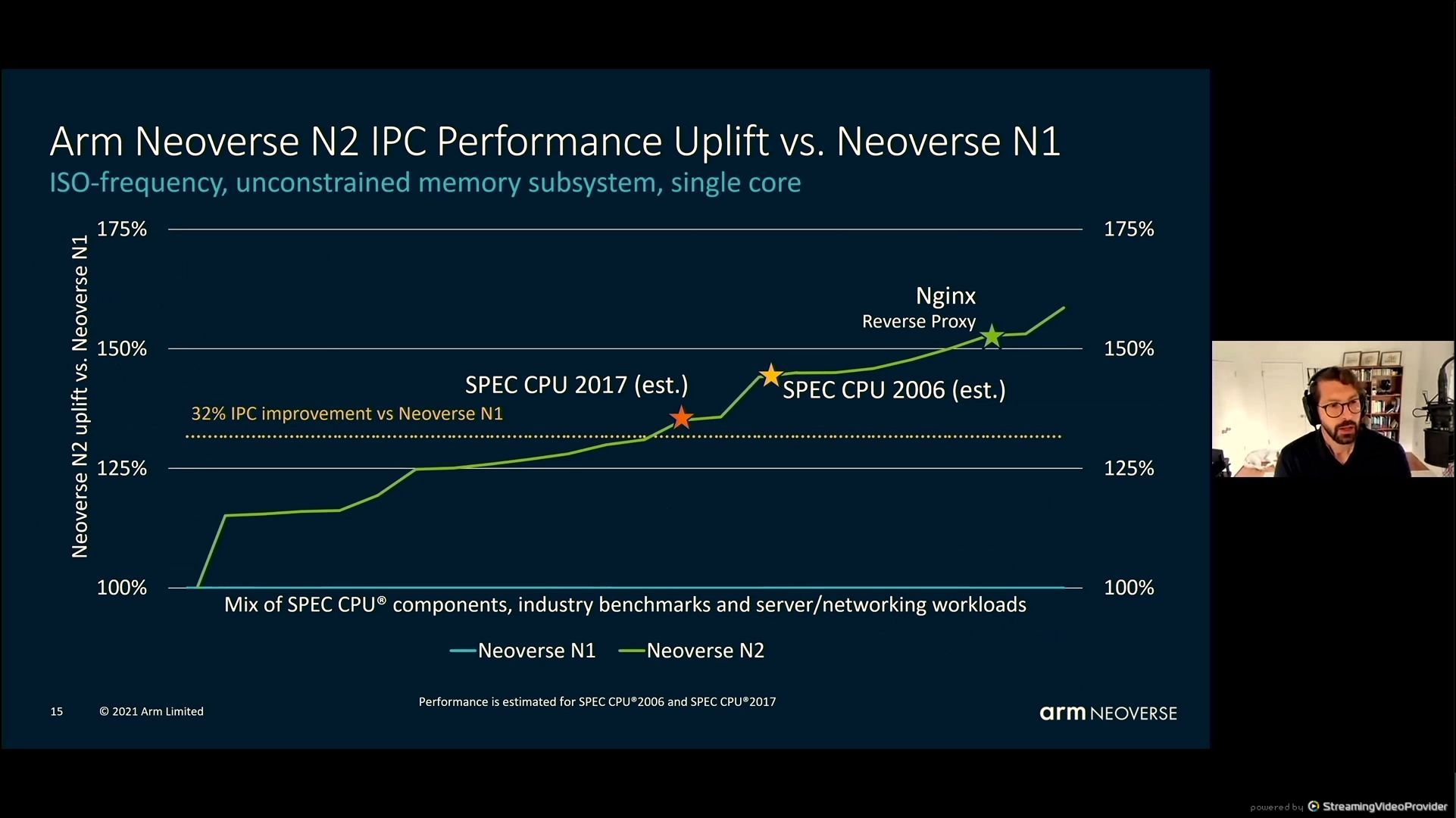
05:45PM EDT - 32% IPC improvement at iso-frequency
05:46PM EDT - SPEC2006 was 40% mentioned earlier
05:47PM EDT - Coherent Mesh Network - CMN700 - chiplets and multi-socket
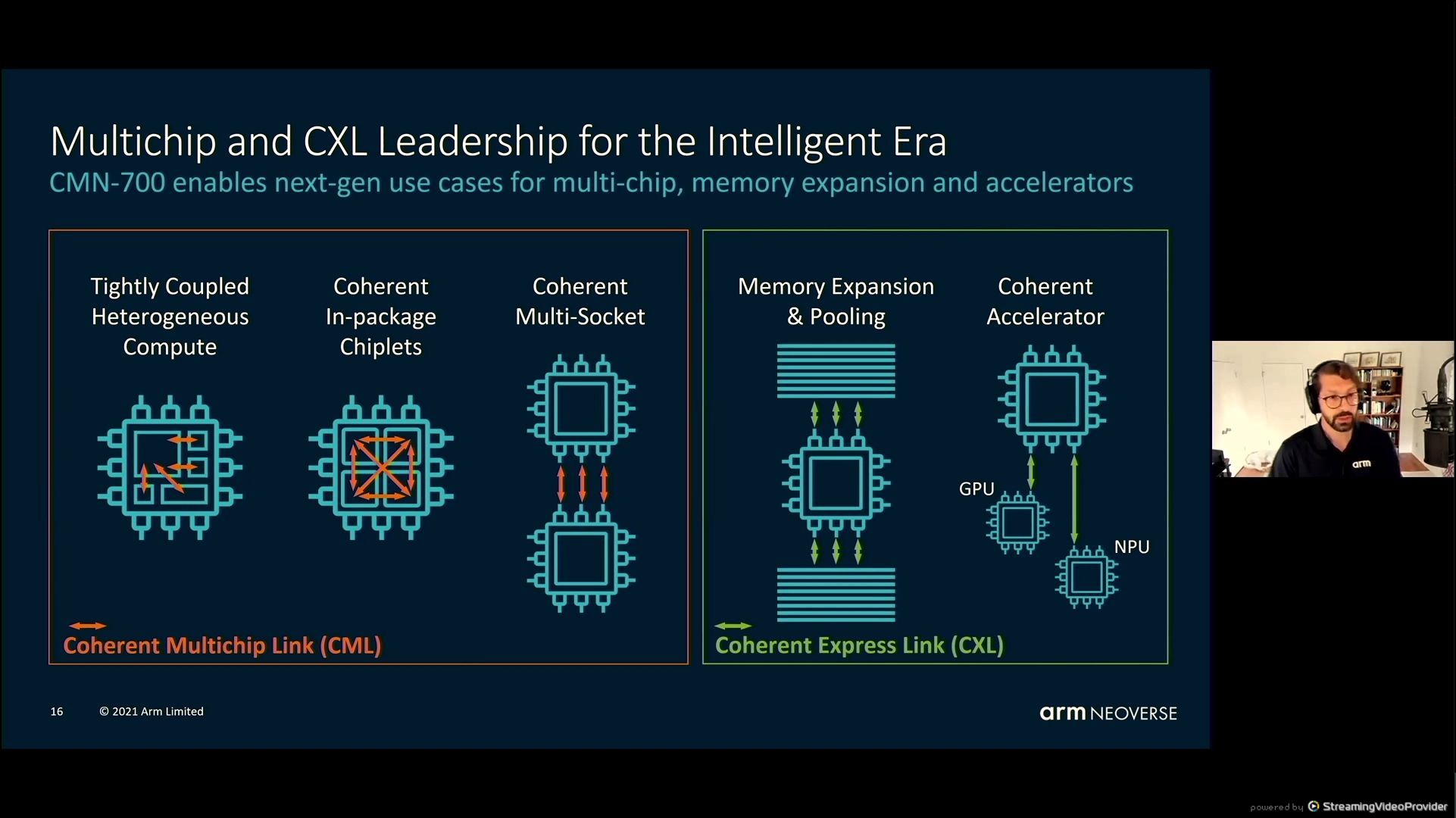
05:47PM EDT - Also CXL support

05:48PM EDT - improvements over 600 - double mesh links, 3x cross sectional BW
05:48PM EDT - Programmable hot-spot re-routing
05:49PM EDT - Composable Datacenter SoCs - chiplets and IO dies and super home dies
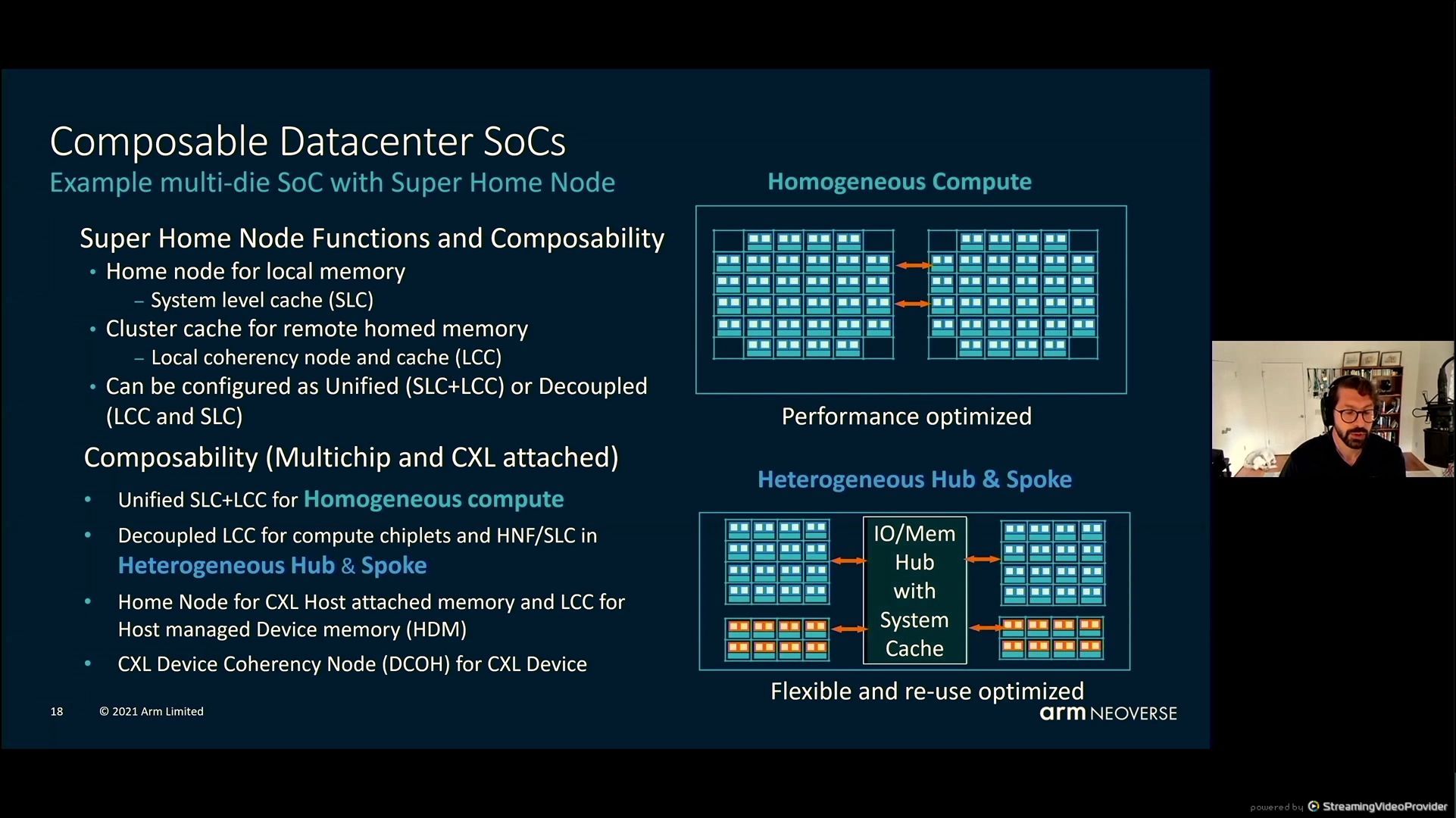

05:51PM EDT - balancing memory requests
05:51PM EDT - control for capacity or bandwidth
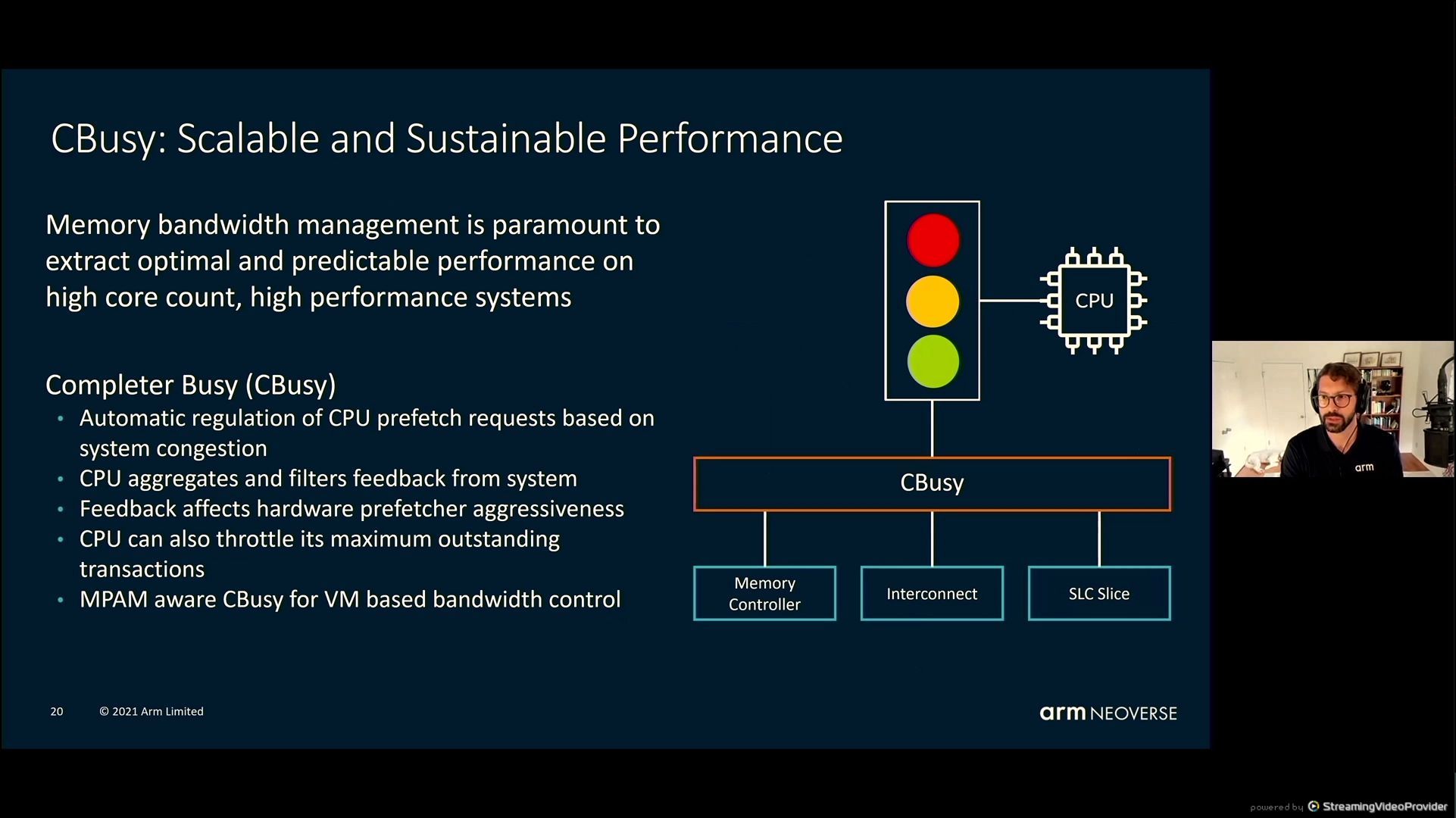
05:52PM EDT - Cbusy - throttling outstanding transactions to the CPU - affects hardware prefetcher aggressiveness
05:53PM EDT - Cbusy and MPAM meant to work together
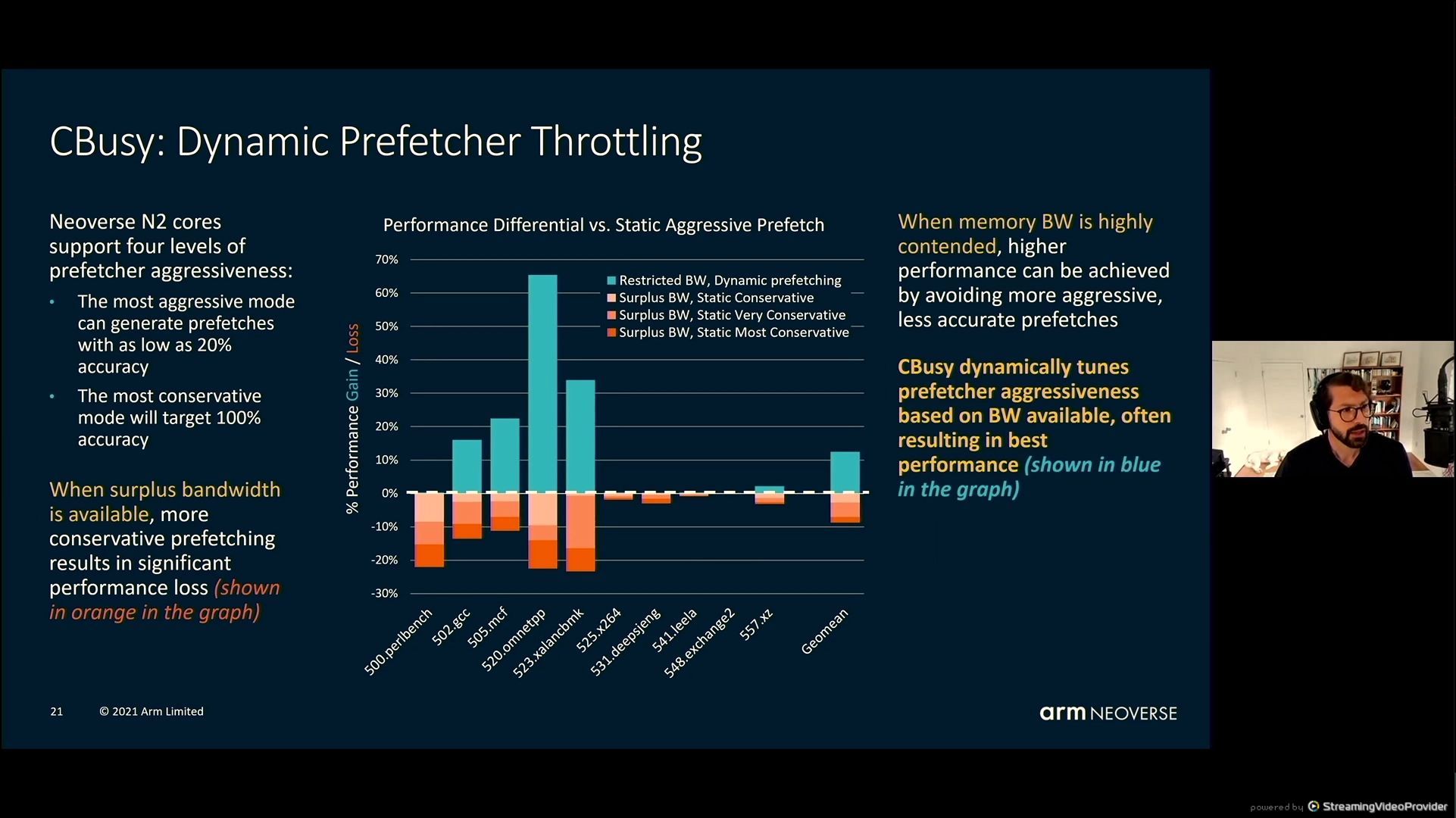
05:54PM EDT - Resulting in best performance

05:56PM EDT - Compared to the market with N2
05:56PM EDT - integer performance only
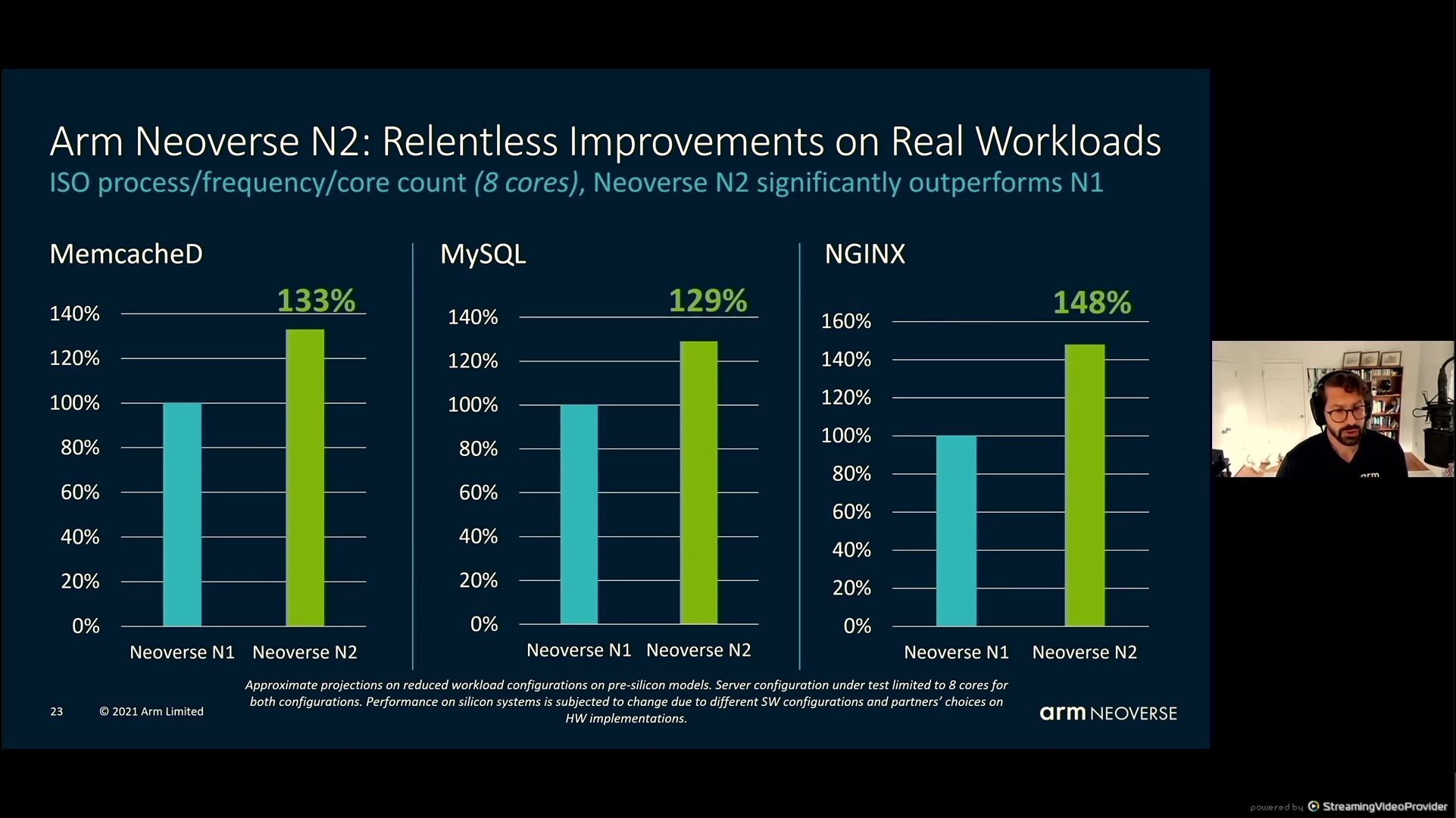
05:57PM EDT - 'Real world workload' numbers based on pre-silicon models

05:58PM EDT - Up to 256 cores of N2 should be fun
05:59PM EDT - hit the market in the next few months
05:59PM EDT - Q&A
05:59PM EDT - Q: Is N1/N2 at iso-freq - what freq on slide 10? A: a range of power modes, quoted 2-2.5 GHz which is what customers will use
06:01PM EDT - Q: Cbusy for a heterogeneous multi-die system? A: All IPs will get the CBusy information and throttle requests,
06:03PM EDT - Q: MPAM cache partitioning? weight? A: It can do. But also support fine grain threshholds for control - you can tune based on capacity without overpartitioning
06:03PM EDT - Second talk of the session - NVIDIA DPU
06:04PM EDT - Idan Burstein, co-authored NVMoF

06:04PM EDT - Architecture and platform use-cases

06:05PM EDT - Data center is going through a revolution
06:05PM EDT - Fully disaggregate your server between compute, memory, acceleration, storage, and software. Requires accelerated networking and DPUs to control it all
06:06PM EDT - 10-20x bandwidth deployed per server requires better networking
06:06PM EDT - a Datacenter infrastructure workload
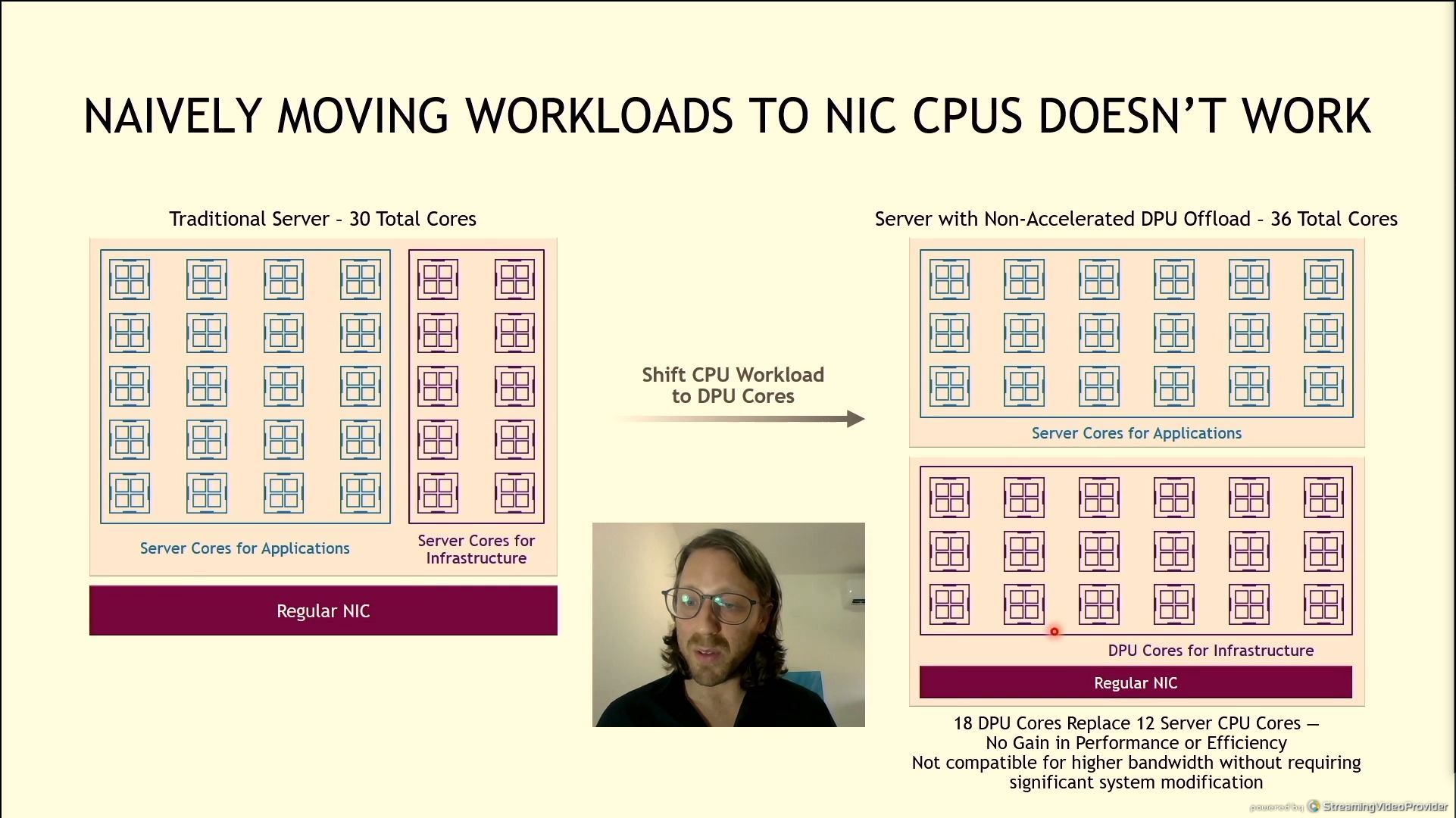
06:08PM EDT - Moving infrastructure workloads to the CPU is a bad idea
06:08PM EDT - Need appropriate offload
06:08PM EDT - Data pass acceleration needed
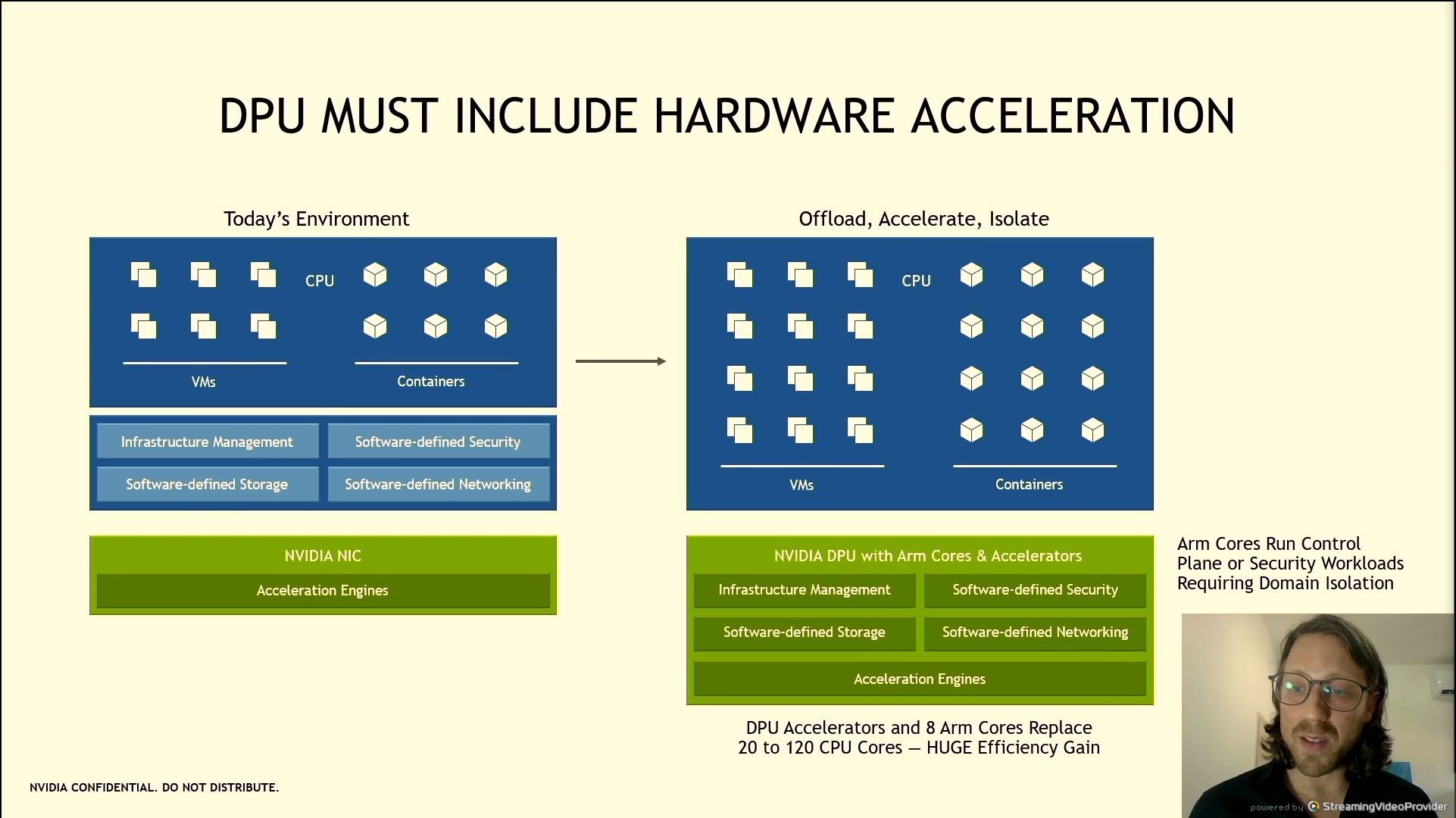
06:09PM EDT - Bluefield-2
06:09PM EDT - Roadmap
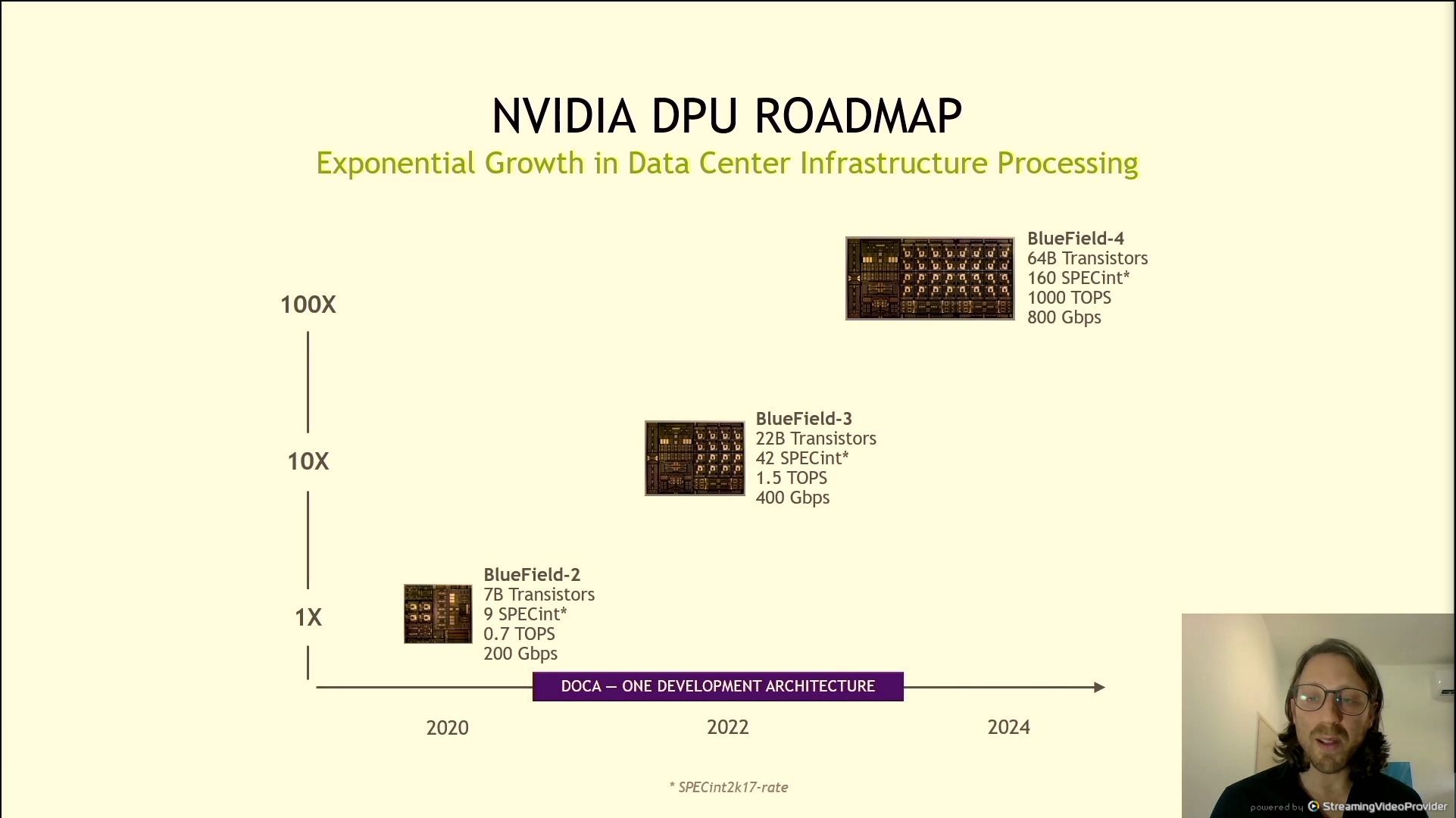
06:09PM EDT - Currently shipping BF-2, announced BF-3 with double bandwidth
06:09PM EDT - BF-4 is 4x BF-3
06:09PM EDT - BF-4 also uses NVIDIA AI
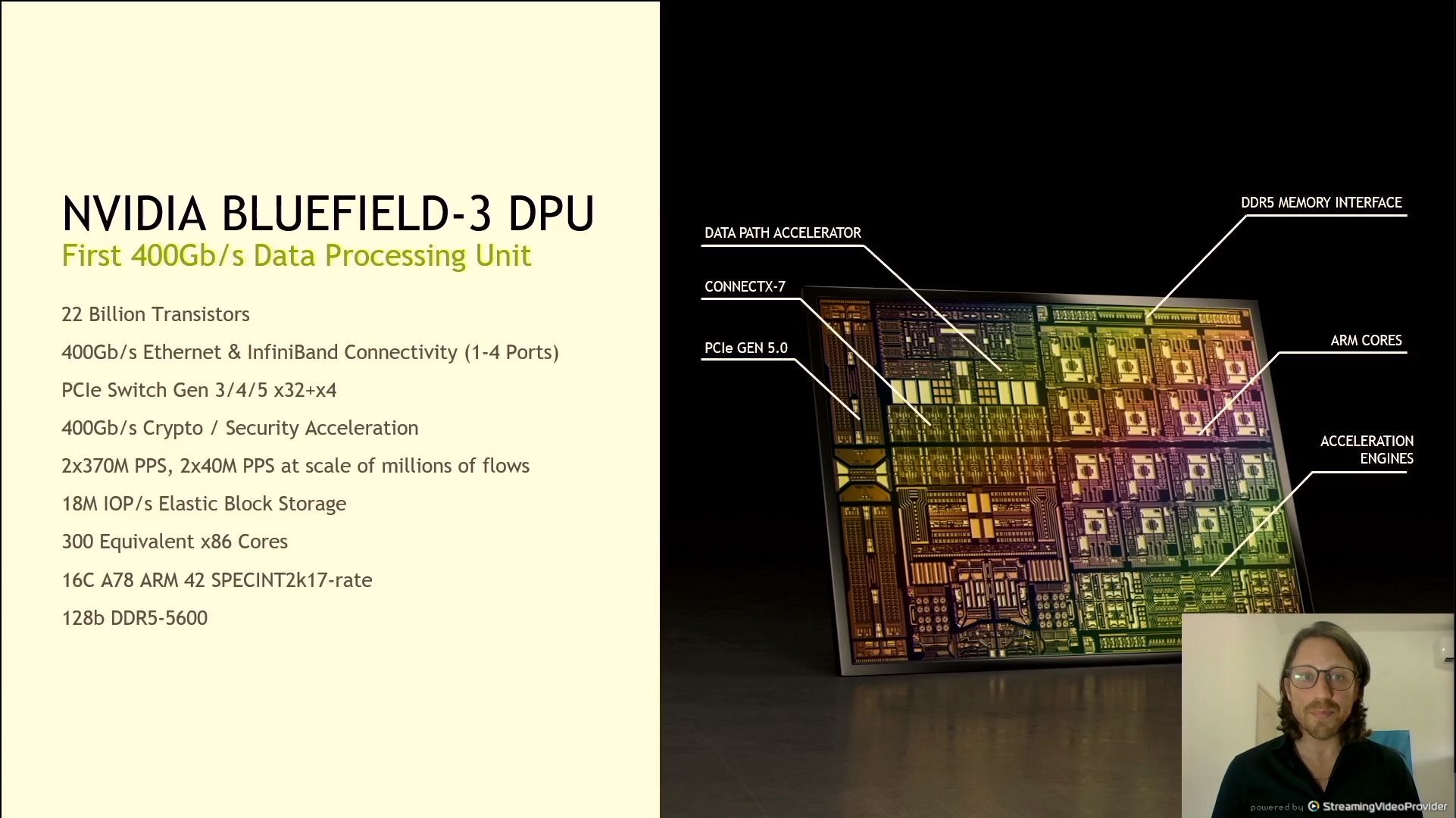
06:10PM EDT - 22 billion transistors
06:10PM EDT - PCIe 5.0 x32
06:10PM EDT - 400 Gb/s Crypto
06:10PM EDT - 300 equivalent x86 cores
06:10PM EDT - 16 cores of Arm A78
06:10PM EDT - DDR5-5600, 128-bit bus
06:11PM EDT - supports 18m IOPs
06:11PM EDT - Connect-X 7
06:11PM EDT - DOCA Framework

06:11PM EDT - Program on DOCA on BF-2, scales immediately to BF-3 and BF-4
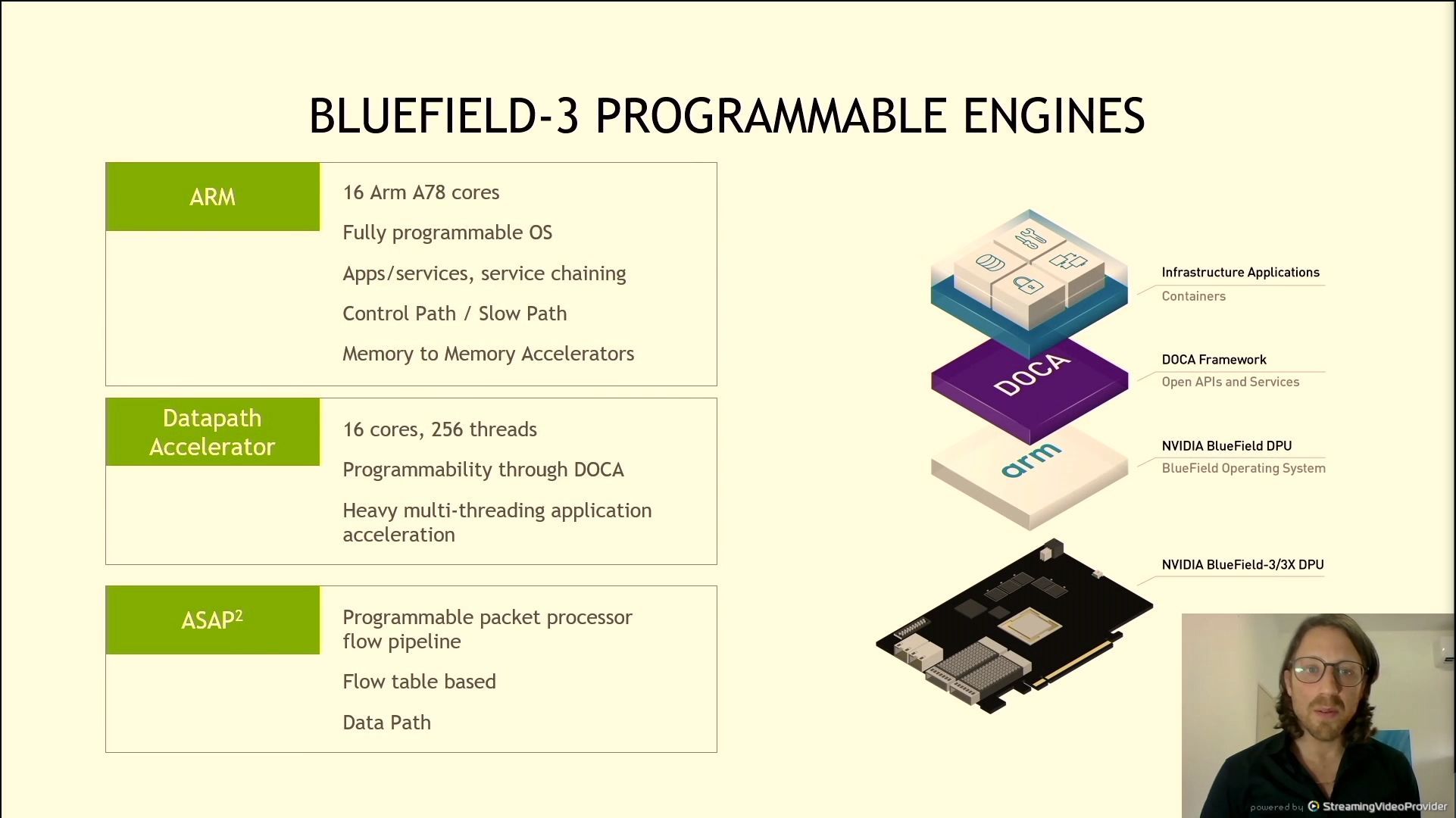
06:12PM EDT - 3 different programmable engines
06:12PM EDT - 16x Arm A78 - server level processor
06:12PM EDT - 16 cores, 256 threads (SMT16?) datapath accelerator
06:12PM EDT - ASAP - As soon as possible programmable packet processor flow pipeline
06:13PM EDT - Bluefield-4X
06:13PM EDT - Bluefield-3X
06:13PM EDT - Not ASAP, ASAP-squared
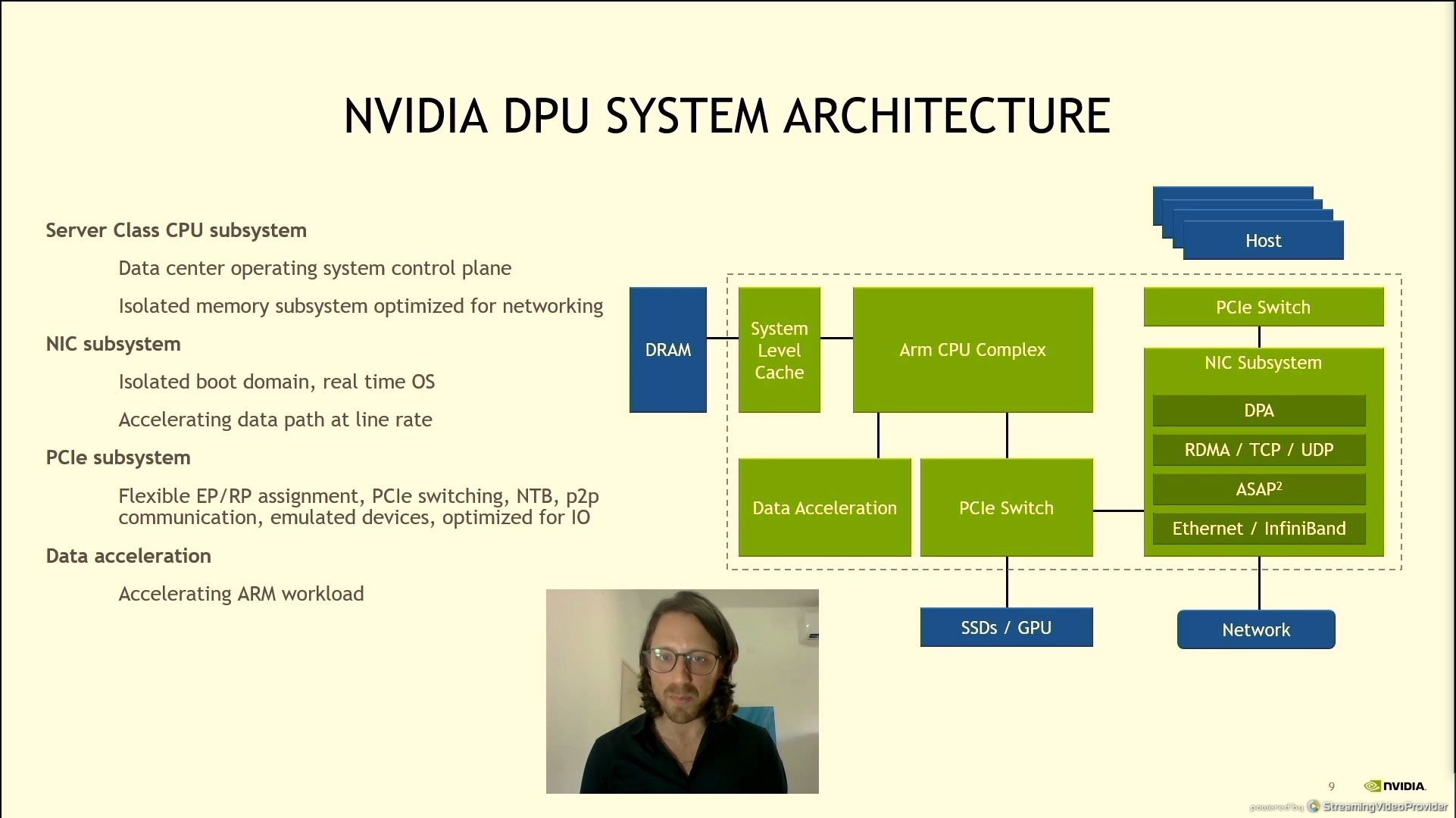
06:15PM EDT - Isolated boot domain in RT OS
06:16PM EDT - PCIe tuned for DPU

06:17PM EDT - Differentiating between the datapaths - software defined networking stack
06:18PM EDT - accelerating the full path from host to network
06:18PM EDT - it says bare metal host - can it do virtual hosts?
06:19PM EDT - Encryption, Tunneling, NAT, Routing, QoS, Emulation
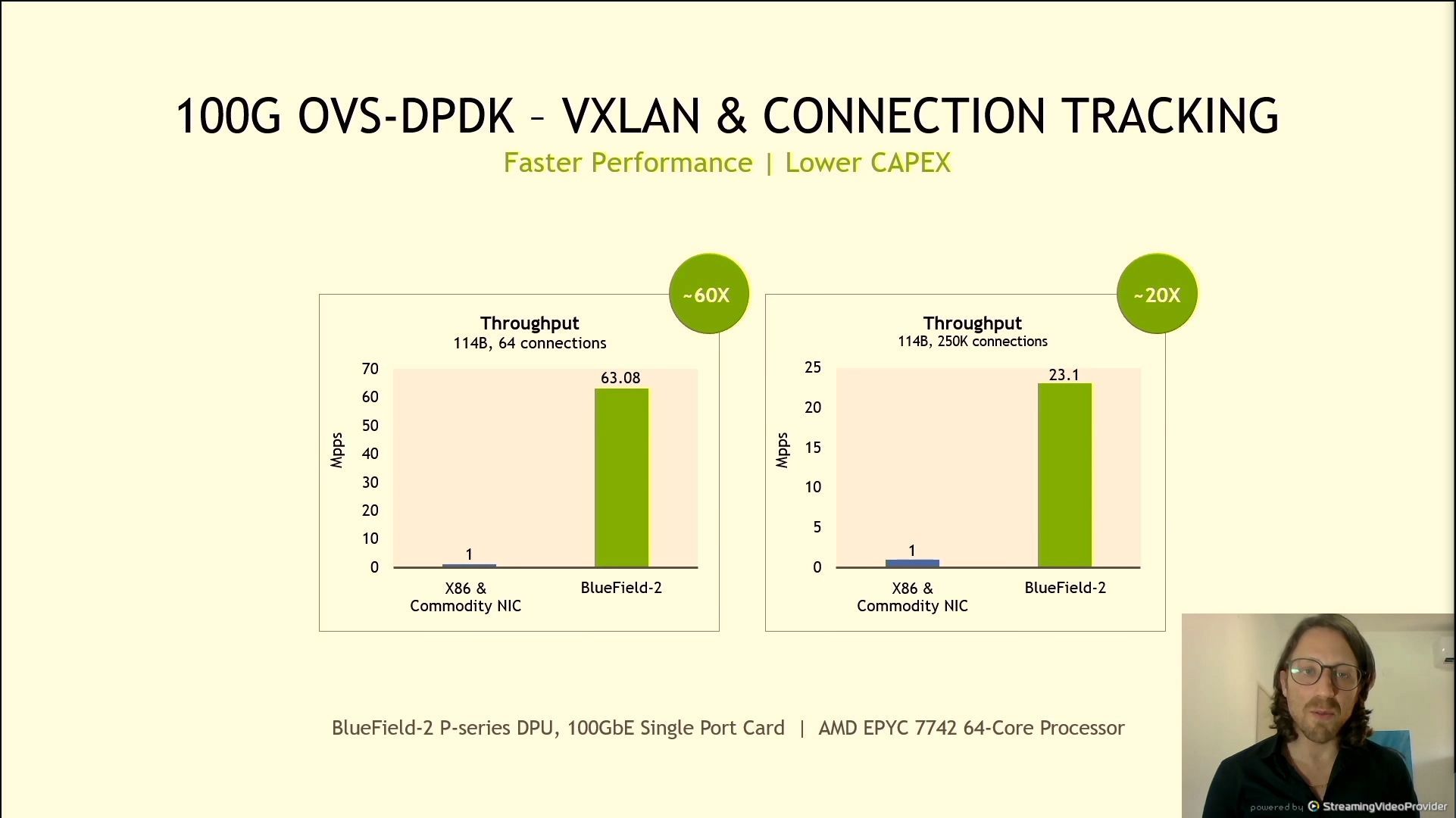
06:19PM EDT - 100G DPDK
06:19PM EDT - Million packets per second
06:20PM EDT - vs AMD EPYC 7742 64-core
06:20PM EDT - This is Bluefield 2
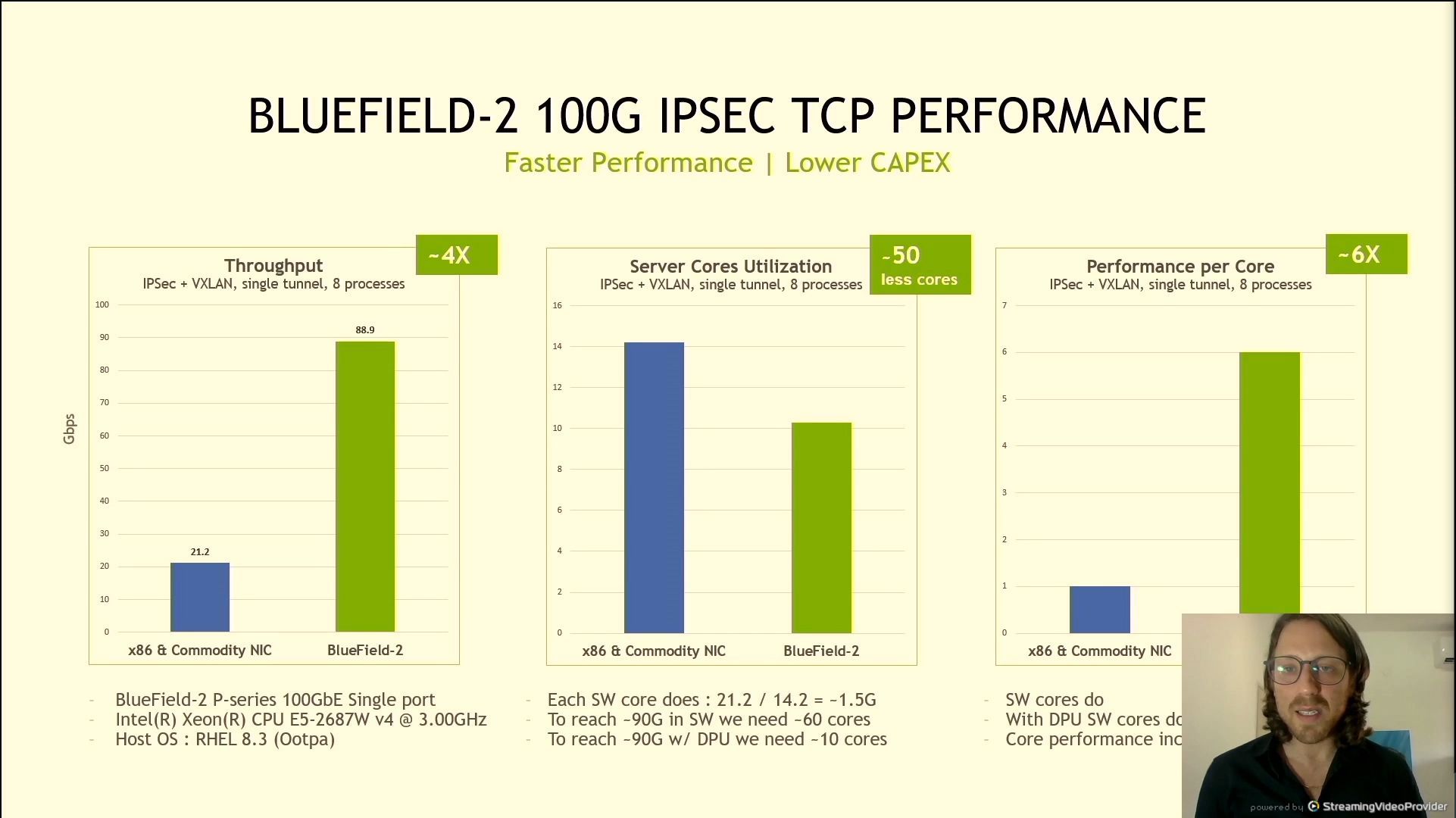
06:20PM EDT - TCP flow with 100G IPSEC

06:22PM EDT - Storage processing acceleration
06:22PM EDT - Data in-flight encryption

06:24PM EDT - NVMe over Fabric
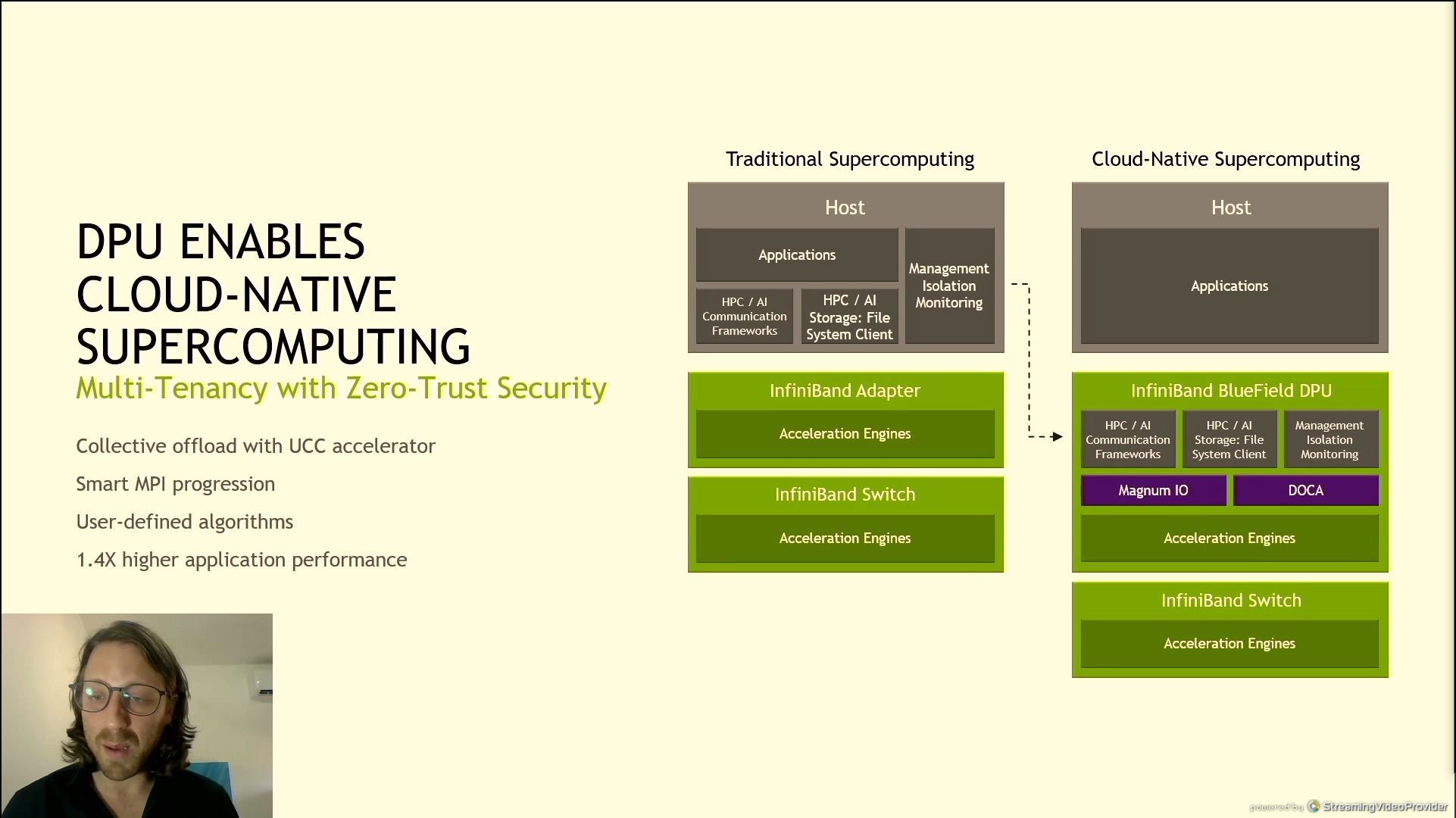
06:27PM EDT - Cloud-native supercomputing with non-blocking MPI performancew
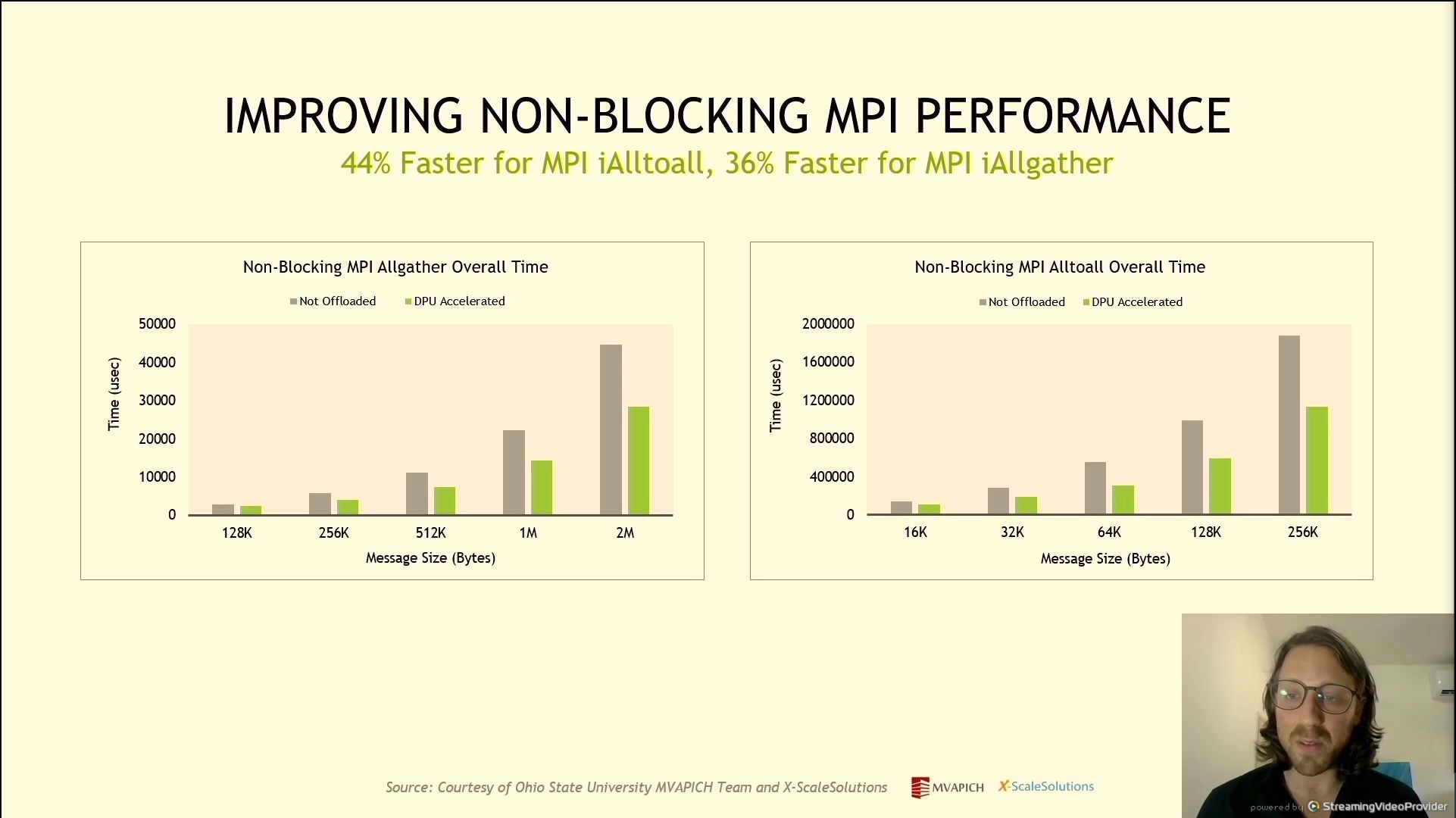
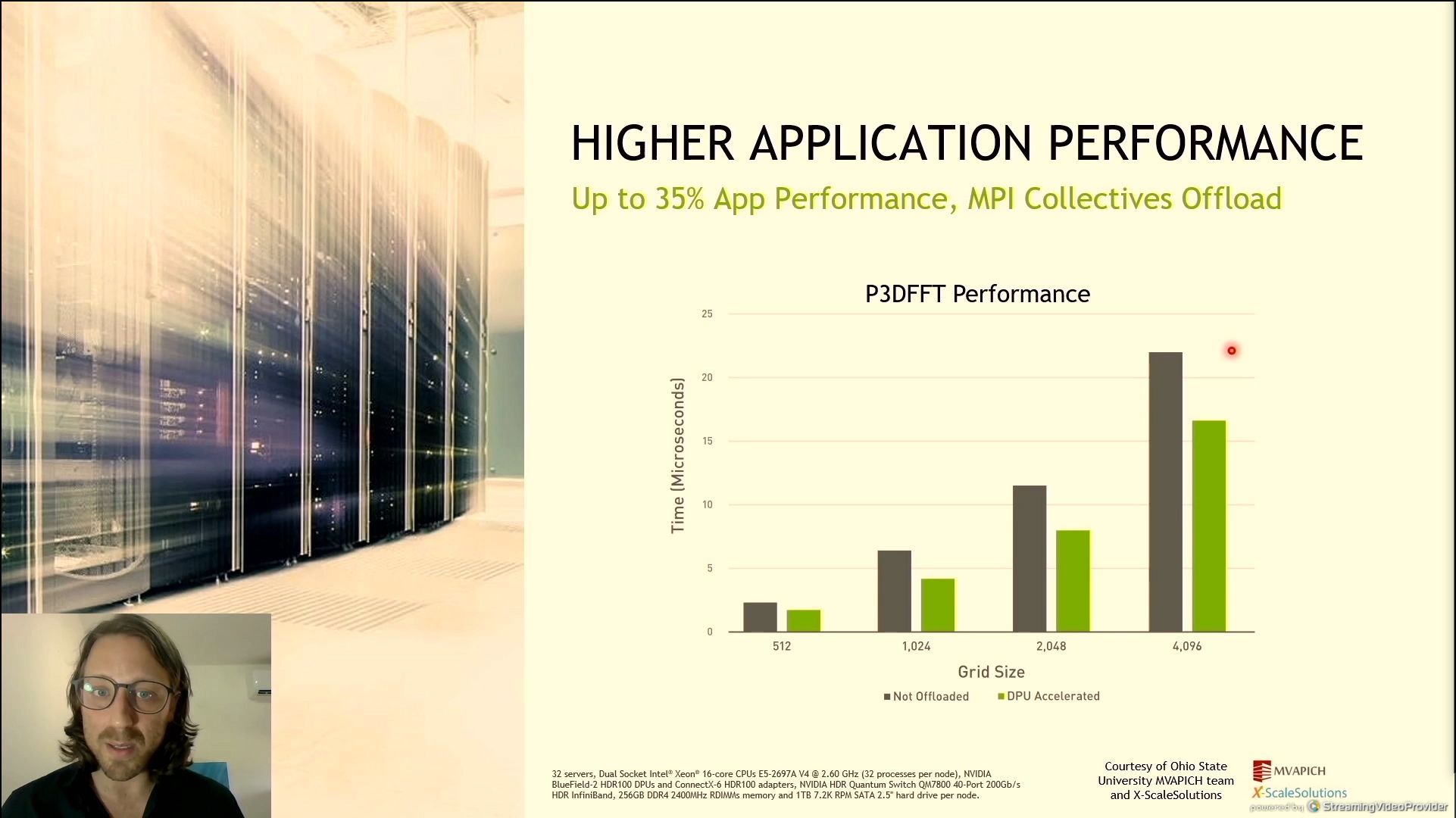
06:27PM EDT - Accelerated FFT performance across multi-node HPC
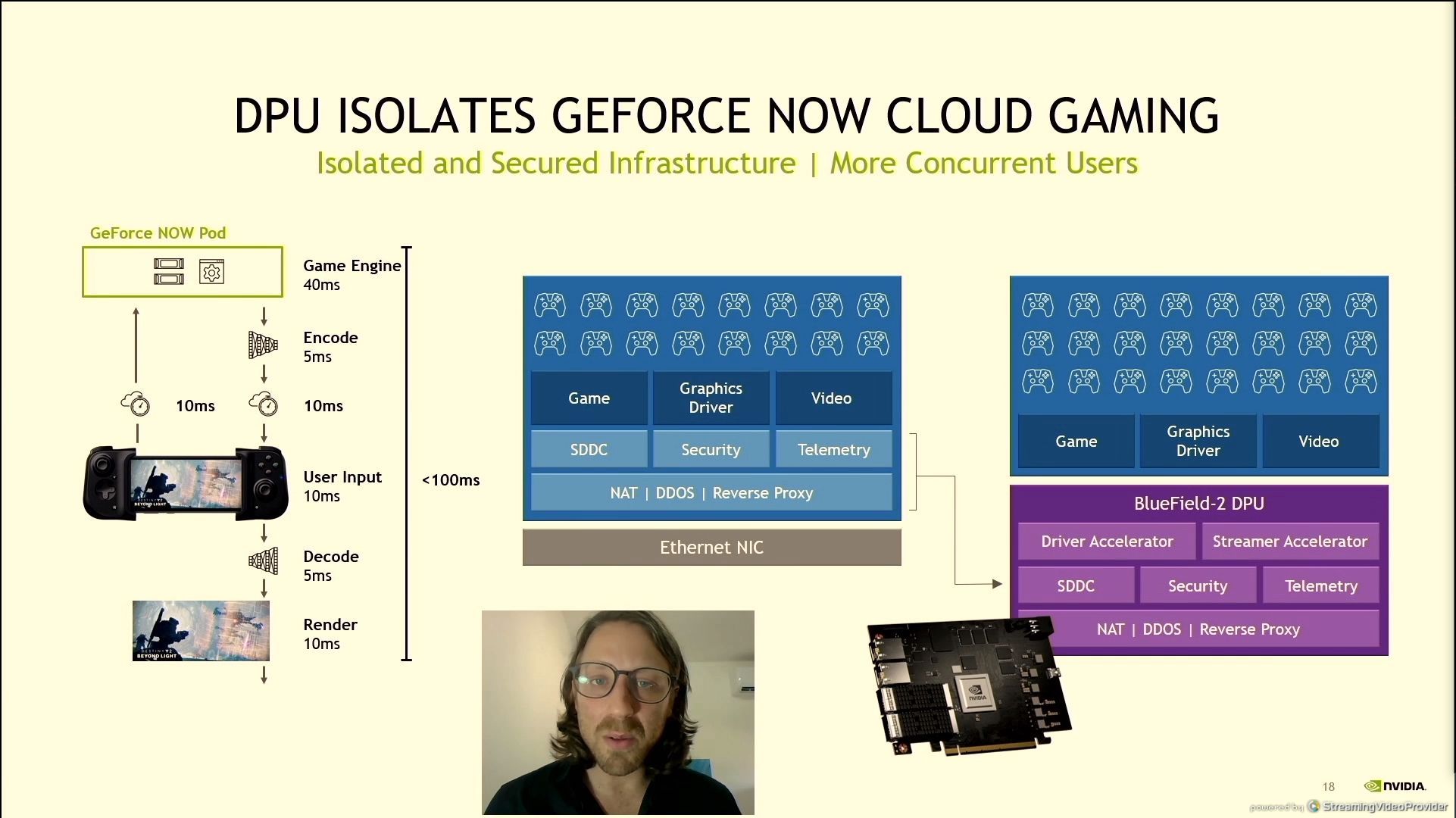
06:28PM EDT - DPU isolates Geforce Now - 10 million concurrent users
06:28PM EDT - +50% more users per server
06:28PM EDT - Push more concurrent users
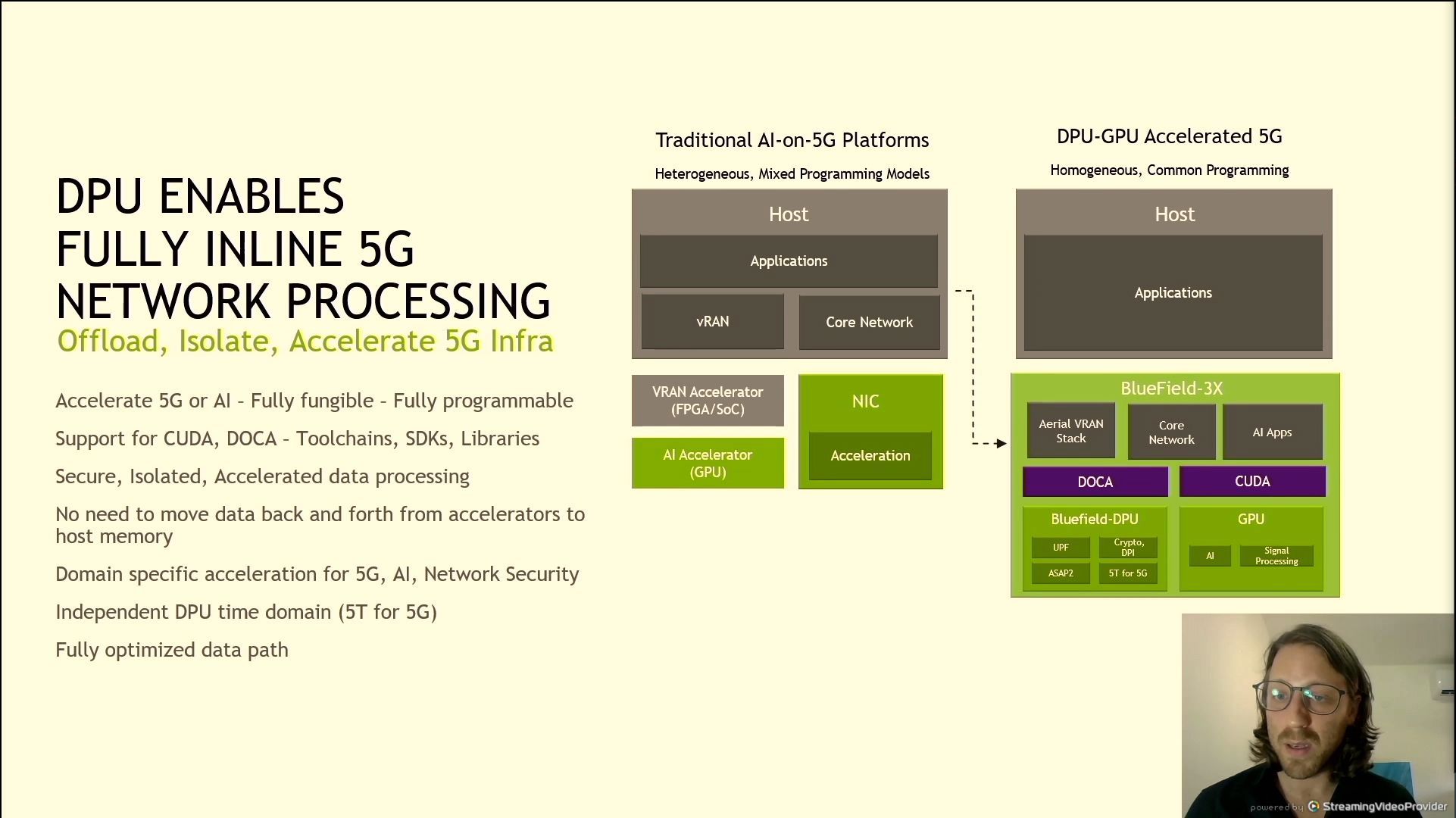
06:29PM EDT - Bluefield 3X has onboard GPU
06:30PM EDT - Support for CUDA
06:30PM EDT - GPU + DPU + network connectivity, fully programmable on a single PCIe card
06:31PM EDT - Q&A Time
06:31PM EDT - Q: Cortex A rather than N1/N2 A: A78 was the most performing core at the time
06:31PM EDT - Q: Add CXL to future Bluefield? A: Can't comment. See CXL as important
06:33PM EDT - Q: RT-OS cores? A: Designed internally, arch is RISC-V compatible
06:34PM EDT - Q: Can DPU accelerate RAID construction? A: Yes it can - trivial and complex
06:36PM EDT - That's the end, next up is Intel
06:36PM EDT - Bradley Burres

06:37PM EDT - Driving network across the datacenter for Intel

06:38PM EDT - Same five minute intro about IPUs as the previous talks
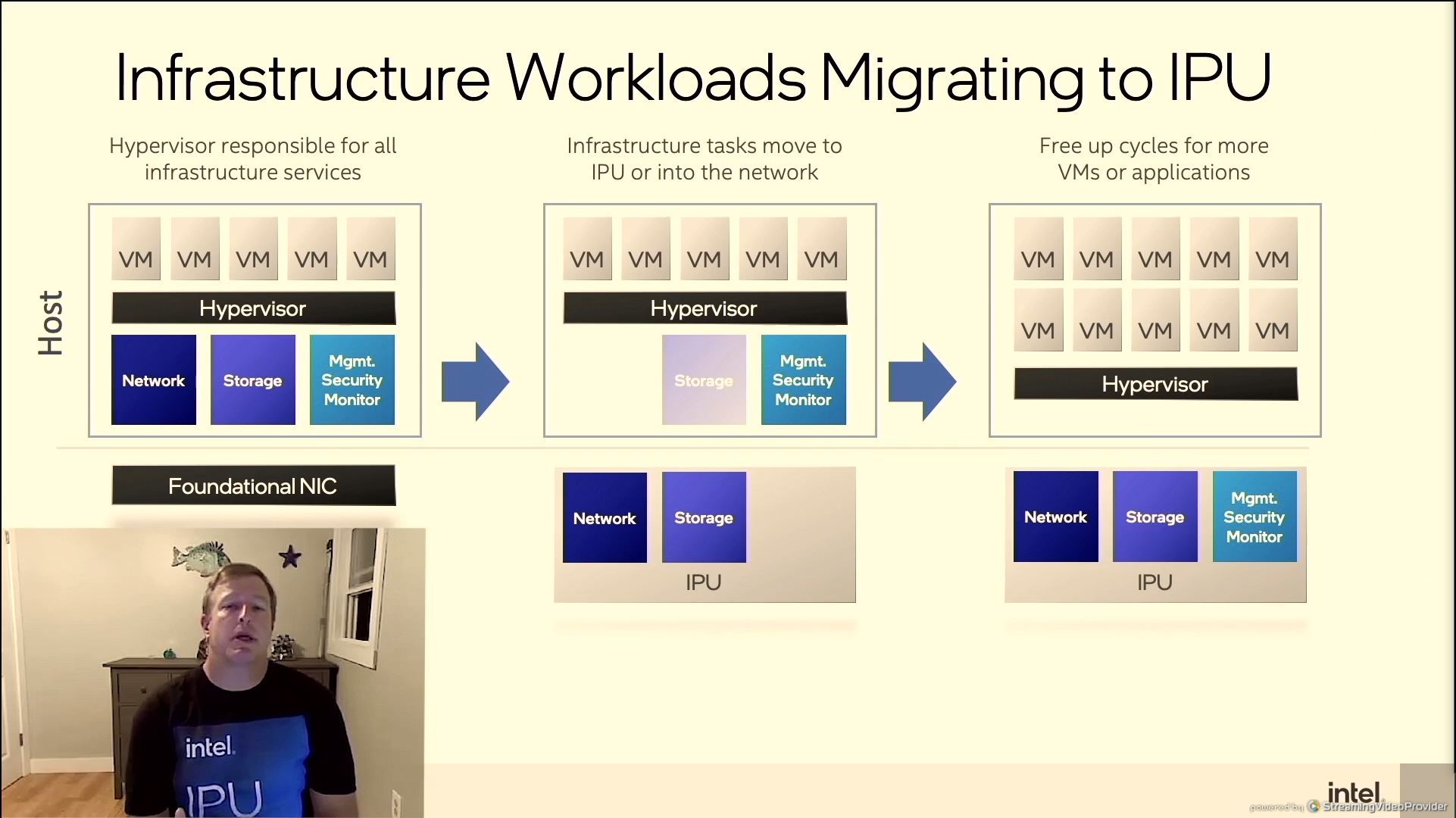
06:40PM EDT - IPU over time has been gaining more control to free up CPU resources. Move these workloads to the IPU = more performance!
06:41PM EDT - 'solving the infrastructure tax'

06:41PM EDT - Mount Evans
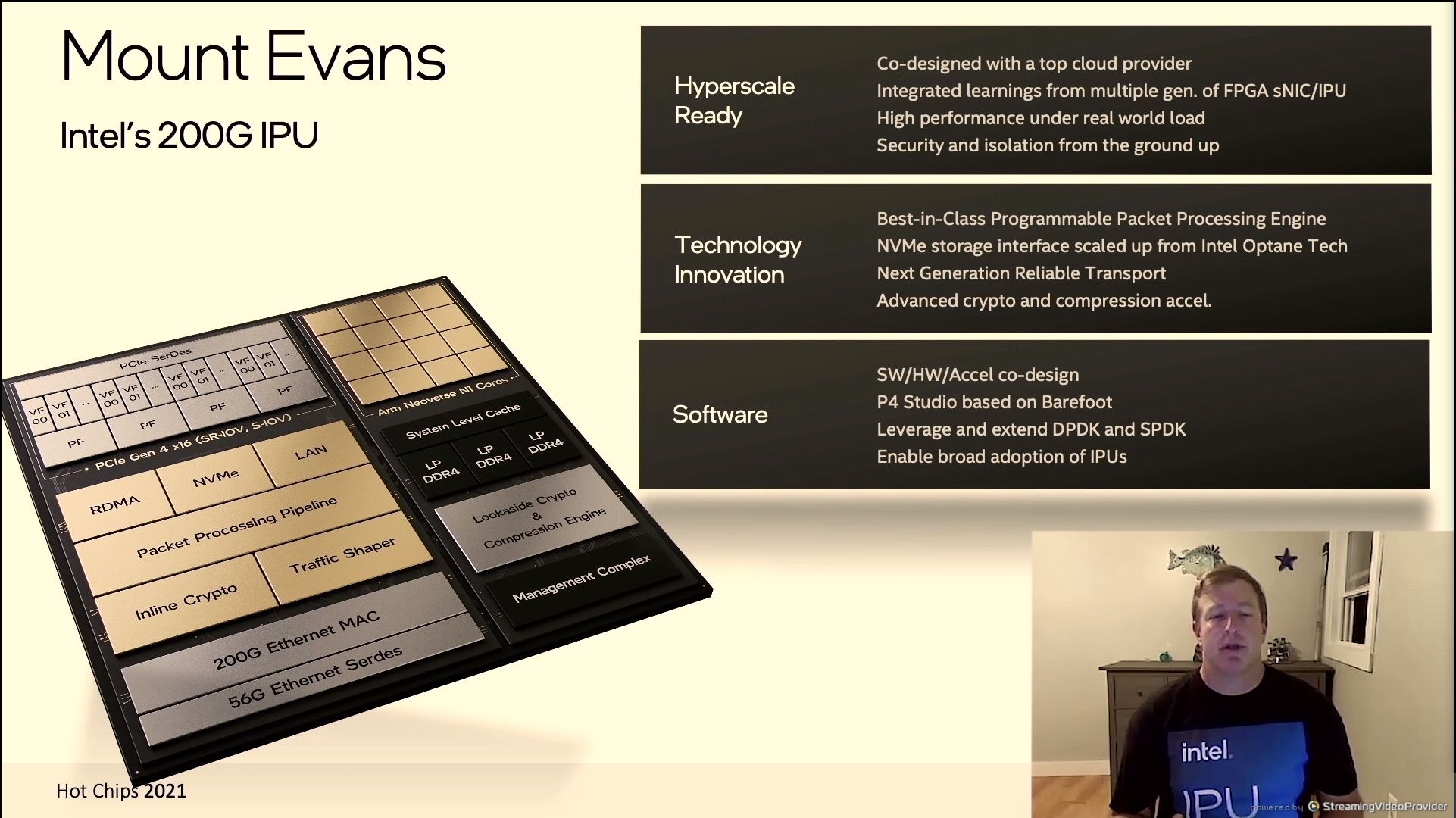
06:41PM EDT - Developed with a CSP
06:41PM EDT - Baidiu or JD ?
06:42PM EDT - 16 Neoverse N1 cores
06:42PM EDT - 200G Ethernet MAC
06:42PM EDT - PCIe 4.0 x16
06:42PM EDT - NVMe storage with Optane recognition
06:42PM EDT - Advanced crypto and compression acceleration
06:42PM EDT - Software, Hardware, Accelerator co-design
06:43PM EDT - solving the long-tail infrastructure issue
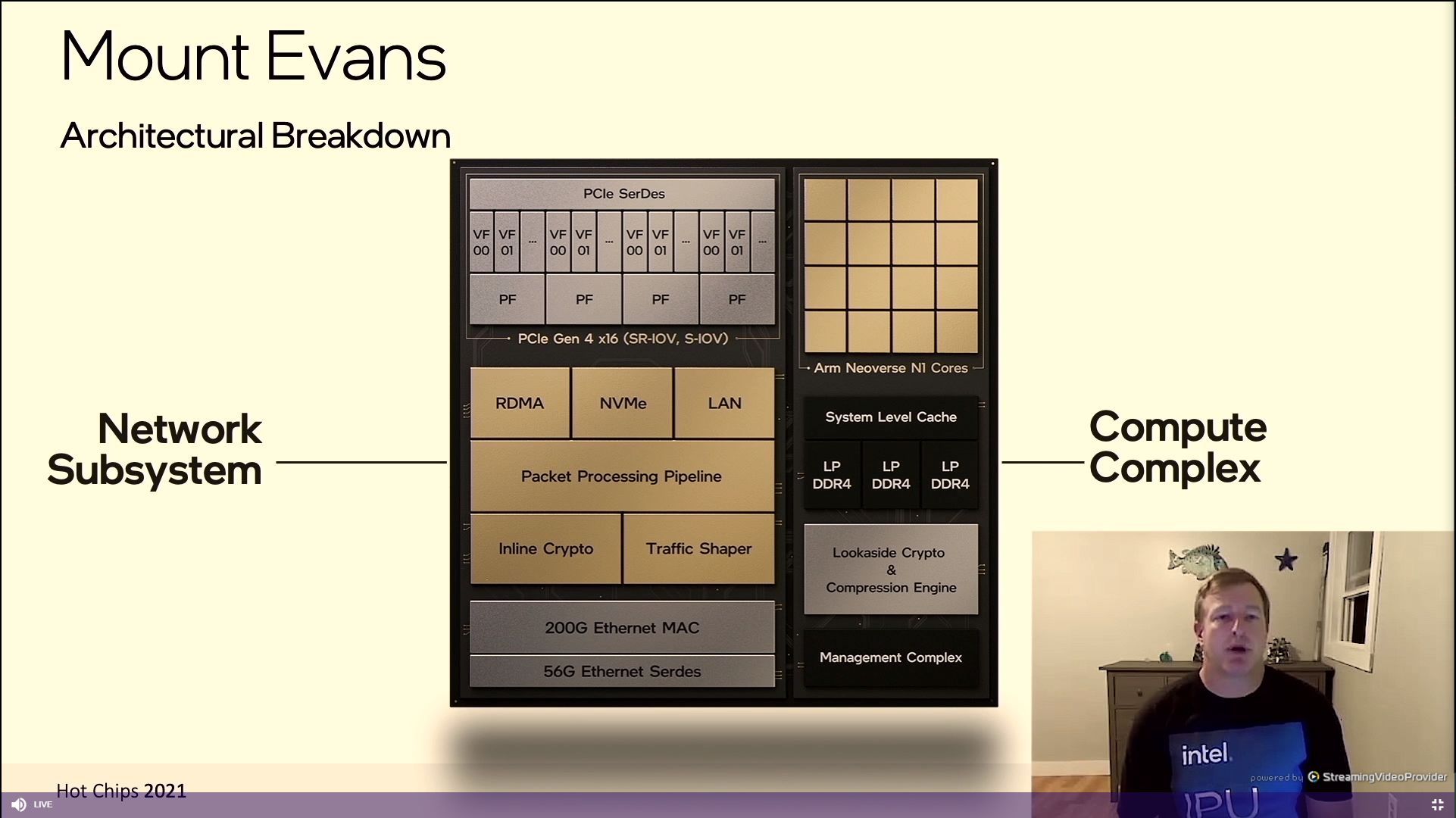
06:44PM EDT - Dataplane on the left, compute on the right
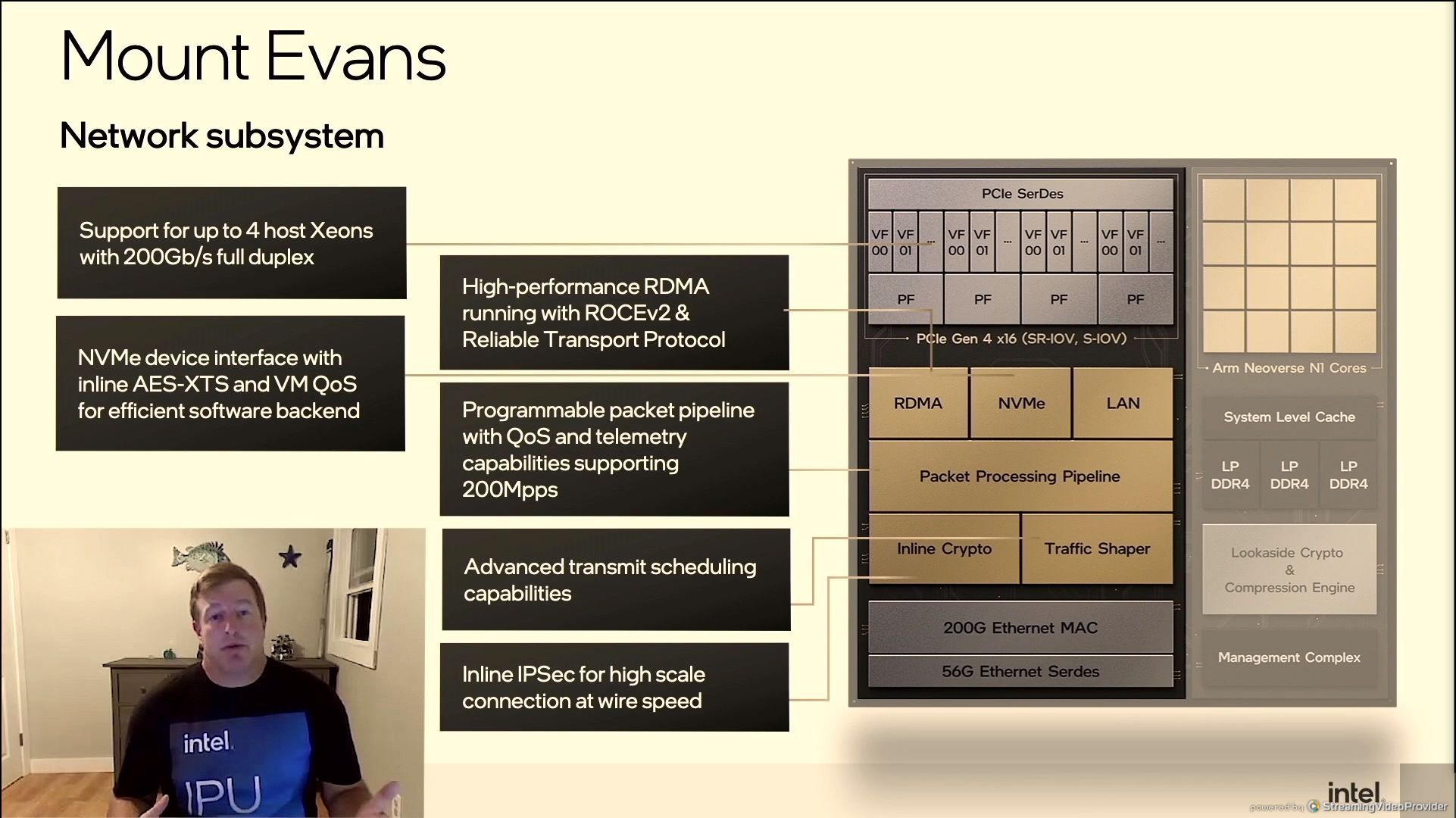
06:44PM EDT - Support 4 socket systems with one Mount Evans
06:44PM EDT - RDMA and ROCE v2
06:44PM EDT - QoS and telemetry up to 200 million packets per second
06:45PM EDT - Inline IPSec

06:46PM EDT - N1s at 3 GHz
06:46PM EDT - three channels of dual mode LPDDR4 - 102 GB/s bandwidth
06:46PM EDT - Engines for crypto
06:47PM EDT - Intel didn't just glue assets together
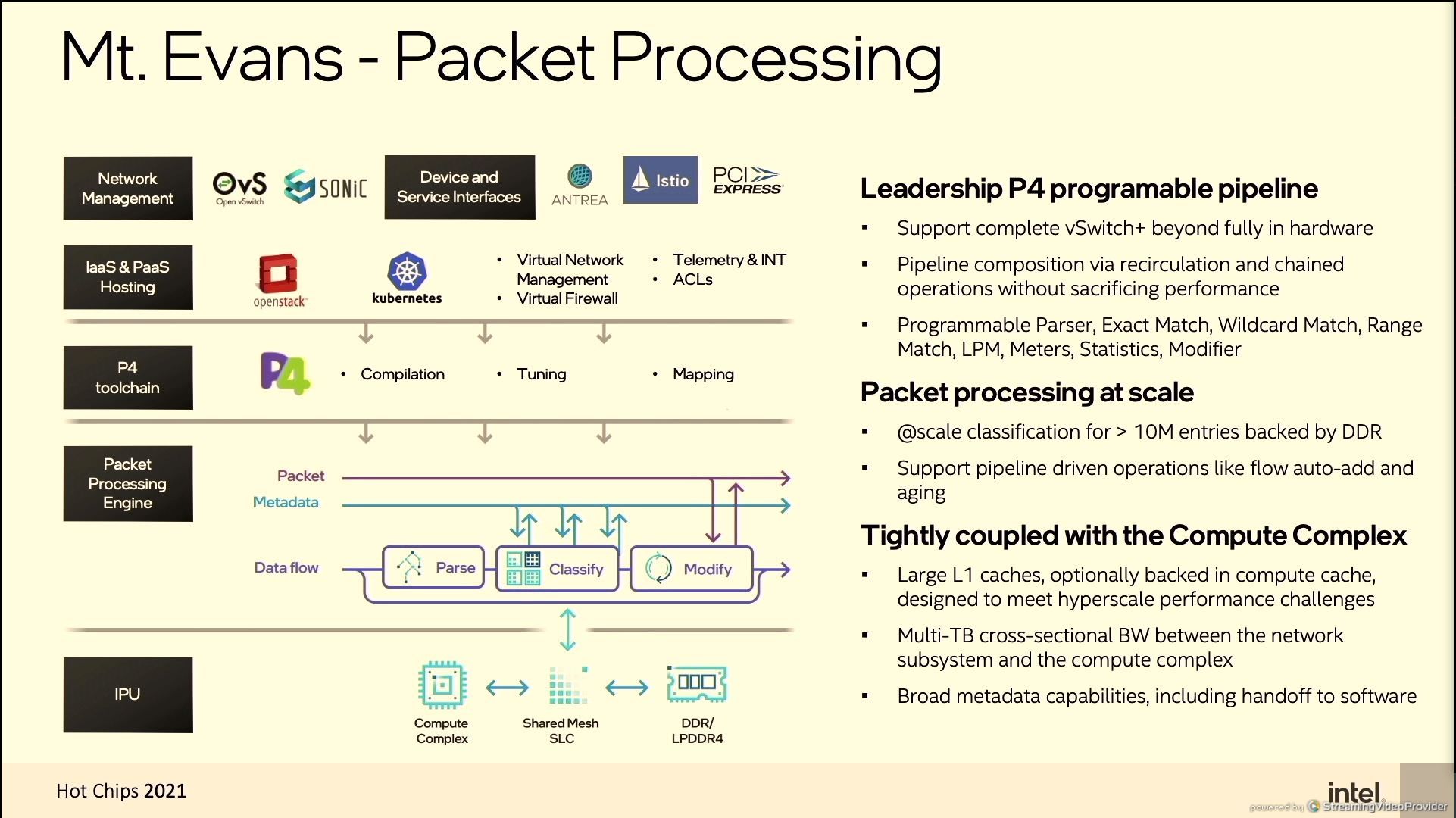
06:49PM EDT - P4 programmable pipeline
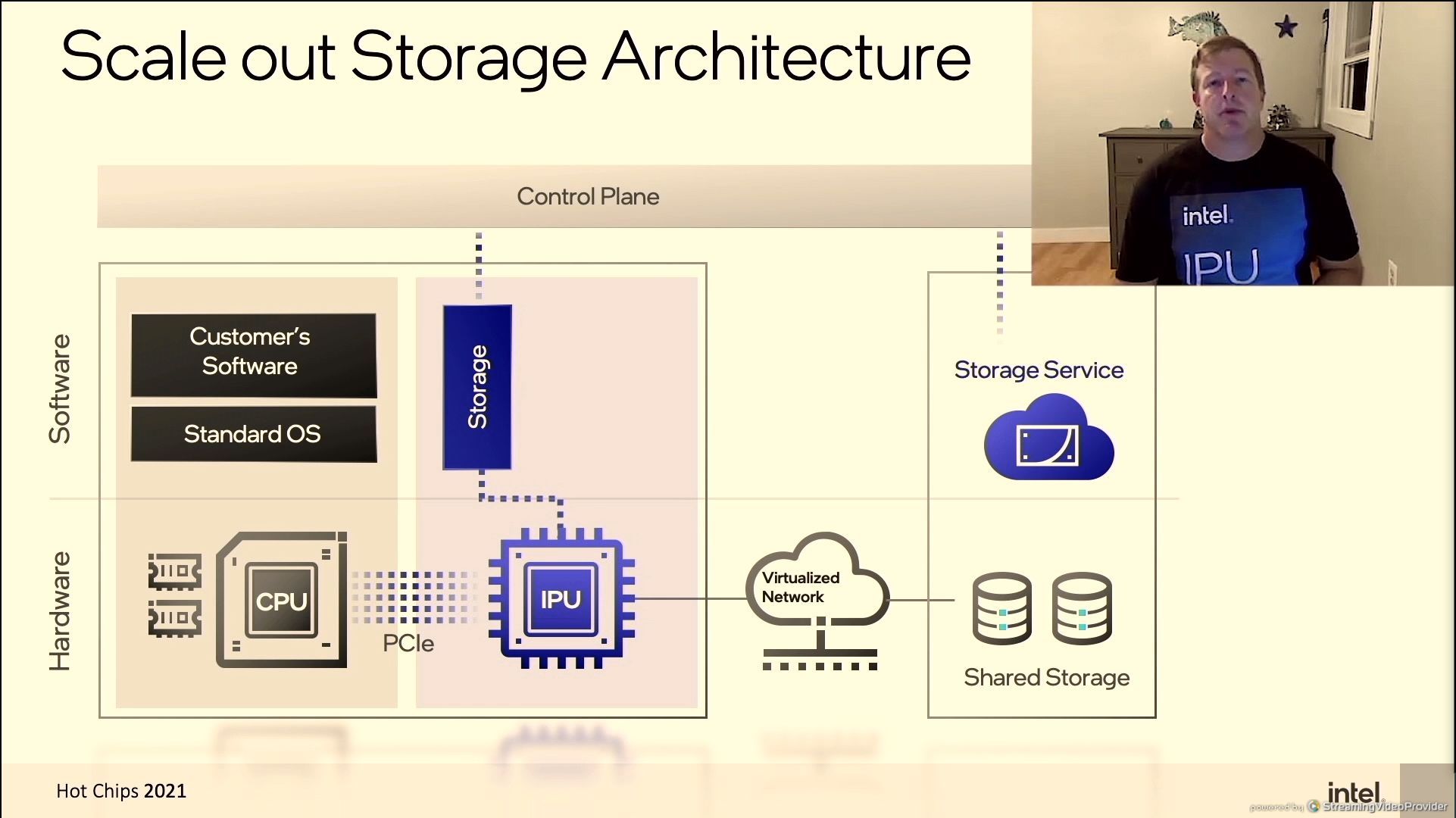
06:51PM EDT - Most applications for IPU is 'brownfield' - has to be dropped in to current infrastructure
06:54PM EDT - Now talking system security with isolation and recovery independent of workloads and tenants
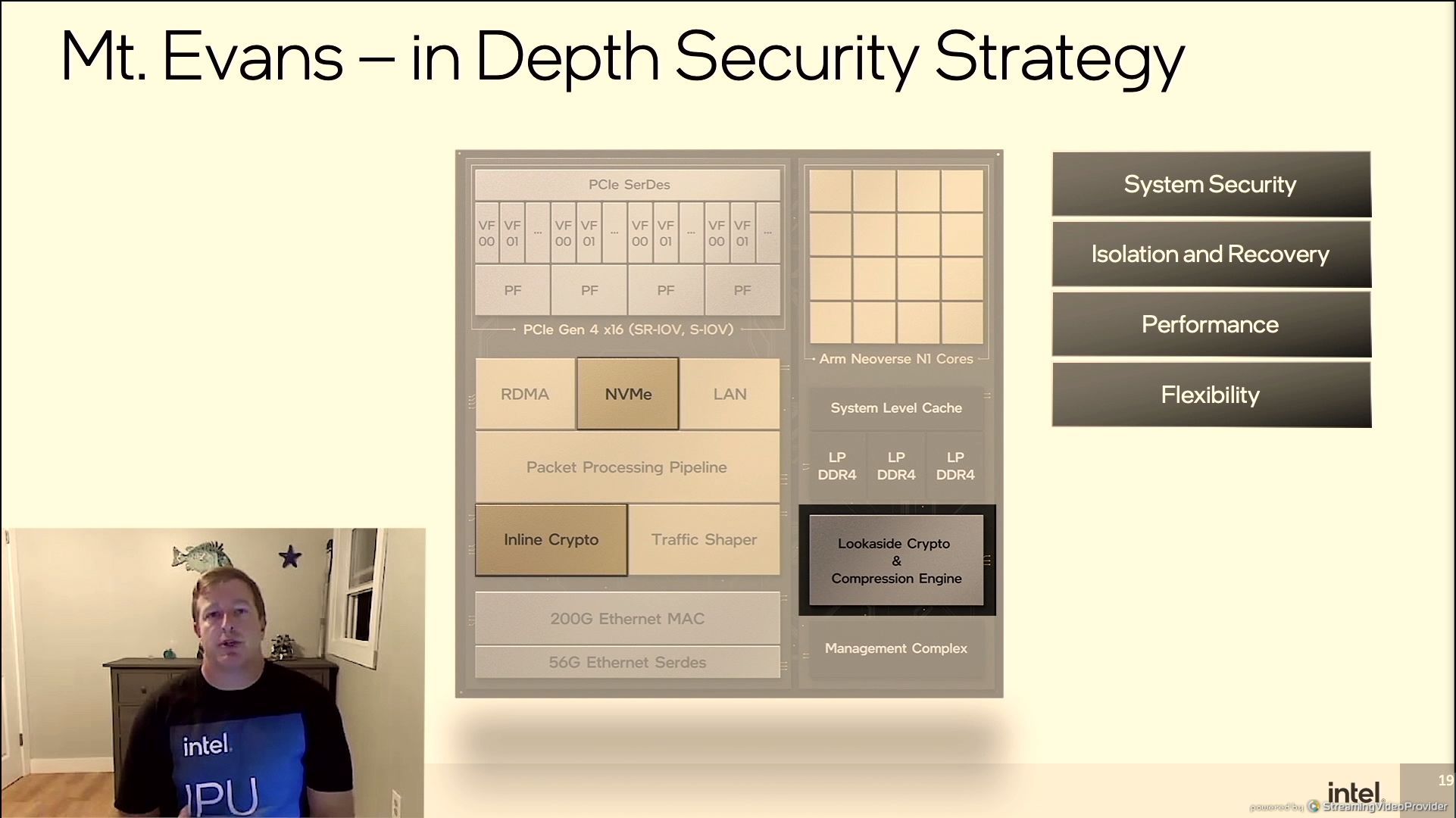
06:55PM EDT - QoS, uptime
06:56PM EDT - malicious driver detection

06:56PM EDT - Futureproofing
06:56PM EDT - Compliant to NSA standards and FIPS140. Said something about 2030?
06:57PM EDT - More info at the intel On event

06:57PM EDT - Q&A Time
06:58PM EDT - Q: PPA with Arm vs IA A: IP available and schedule picked Arm
06:59PM EDT - Q: SBSA compliant? A: Yes
06:59PM EDT - Q: TDP? A: work within PCIe power
07:00PM EDT - Q: Work with SPR given both crypto? A: Yes
07:00PM EDT - Q: Does Mount Evans replace server PCH? A: No, orthogonal
07:02PM EDT - Q: specific to Xeon A: Use with any CPU
07:02PM EDT - THat's a wrap, time for a keynote!
07:02PM EDT - .








12 Comments
View All Comments
OreoCookie - Monday, August 23, 2021 - link
Is that Intel‘s first modern (i. e. post XScale sale) ARM product? That seems quite significant.autarchprinceps - Tuesday, August 24, 2021 - link
I agree. With its main competitors in the field also using ARM, the ecosystem will standardise around that. Increasing amounts of workload will run on ARM, even on x86 servers.I think that is a good thing. With Xe HP(C) also using an actual GPU architecture, instead of trying to use x86 like Xeon Phi did, and an actual foundry service, Intel seems to be committing a lot more to make good products and sales where they can, rather than to rely on vendor lock in and economics of scale alone.
OreoCookie - Tuesday, August 24, 2021 - link
Totally agree with you on Xeon Phi, it was such a bad idea to think that a massive amount of x86 cores (P54C derivatives if memory serves) are better suited than an architecture designed from the ground up for GPU workloads. Peak Intel hubris.Now that they let go of it, they can suddenly make products that seem to actually be competitive. Seem to, because nobody has tested them yet. But at least it looks as if they have all the right ingredients: the right architecture, up-to-date manufacturing, etc.
Ian Cutress - Thursday, August 26, 2021 - link
Phi eventually went Silvermont in KNL.jeremyshaw - Tuesday, August 24, 2021 - link
Also plenty of arm products from the FPGA side of the business. One of which is quite popular for the MiSTer retro hardware (silicon logic) project.Intel FPGA are about as inhouse as Intel >10GbE network chips, so I think the FPGA business counts.
watersb - Tuesday, August 24, 2021 - link
Seems as if Hot Chips this year is really huge! Perhaps things deferred in 2020?twotwotwo - Tuesday, August 24, 2021 - link
I think it's mostly that Ian decided to go all-out covering it this year!Ian Cutress - Thursday, August 26, 2021 - link
I did 18 live blogs last year as well! This year I decided to coalesce several blogs from one section into singular piecestwotwotwo - Tuesday, August 24, 2021 - link
Because I (apparently) love writing things down so I can later be officially, on-the-record wrong, I kind of think these will remain pretty specialized, and lose out in favor of (90%) putting accelerators and small cores in servers but without this tight coupling and (10%) smarter but not revolutionary networking/storage gear.Seems what distinguishes this hardware from any old mini-computer on an AIC is 1) high-bandwidth, fast communication between components on a SoC and 2) special-purpose accelerators and lots of small cores.
But servers have an embarrassment of bandwidth that's expected to grow, and in the long term you can put accelerators and efficiency cores in them without bundling them into a second mini-computer like this. Meanwhile form the other end, it's possible to keep making incrementally smarter NVMe devices or NICs without inventing a whole new category.
Maybe these end up priced to sell in volume, or the software and ecosystem around them is so good that they're an irresistible drop-in speedup for lots of datacenter apps. If they remain only economical for people who have otherwise maxed out a server and need to cram more power in the box, or for a few network/storage-centric uses, then for most of us it's gonna be another trend that comes and goes.
twotwotwo - Tuesday, August 24, 2021 - link
(I should have said "storage devices"--I don't think NVMe as we know it could integrate compression offload, for example, and its crypto support is pretty specific to a single full-disk key I think, but you could imagine a storage device that could do more!)