AMD Unveils CDNA GPU Architecture: A Dedicated GPU Architecture for Data Centers
by Ryan Smith on March 5, 2020 5:25 PM EST- Posted in
- GPUs
- AMD
- Machine Learning
- Supercomputing
- AMD FAD 2020
- CDNA

Over the last decade, the industry has seen a boom in demand for GPUs for the data center. Driven in large part by rapid progress in neural networking, deep learning, and all things AI, GPUs have become a critical part of some data center workloads, and their role continues to grow with every year.
Unfortunately for AMD, they’ve largely been bypassed in that boom. The big winner by far as been NVIDIA, who has gone on to make billions of dollars in the field. Which is not to say that AMD hasn’t had some wins with their previous and current generation products, including the Radeon Instinct series, but their share of that market and its revenue has been a fraction of what NVIDIA has enjoyed.
AMD’s fortunes are set to change very soon, however. We already know that AMD (as a supplier to Cray) has scored two big supercomputer wins with the United States – totaling over $1 billion for CPUs and GPUs – so there have been a lot of questions on just what AMD has been working on that has turned the heads of the US government. The answer, as AMD is revealing today, is their new dedicated GPU architecture for data center compute: CDNA.
The Compute counterpart to the gaming-focused RDNA, CDNA is AMD’s compute-focused architecture for data center and other uses. Like everything else being presented at today’s Financial Analyst Day, AMD’s reveal here is at a very high level. But even at that high level, AMD is making it clear that there’s a fission of sorts going on in their GPU development process, leading to CDNA and RDNA becoming their own architectures.
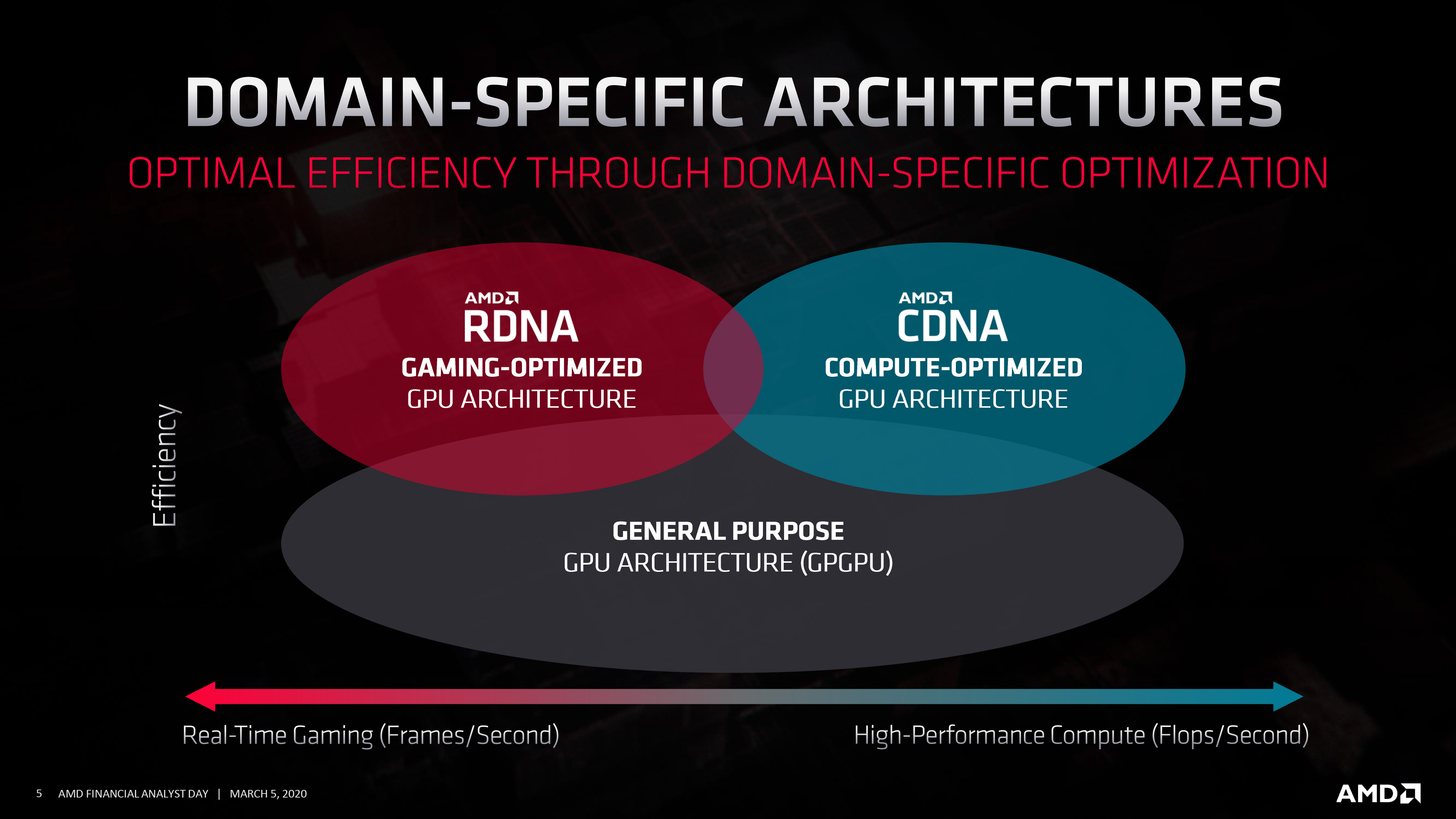
Just how different these architectures are (and over time, will be) remains to be seen. AMD has briefly mentioned that CDNA is going to have less “graphics-bits”, so it’s likely that these parts will have limited (if any) graphics capabilities, making them quite dissimilar from RDNA GPUs in some ways. So broadly speaking, AMD is now on a path similar to what we’ve seen from other GPU vendors, where compute GPUs are increasingly becoming a distinct class of product, as opposed to repurposed gaming GPUs.
AMD’s goals for CDNA are simple and straightforward: build a family of big, powerful GPUs that are specifically optimized for compute and data center usage in general. This is a path AMD already started to go down with GPUs such as Vega 20 (used in the Radeon Instinct MI 50/60), but now with even more specialization and optimization. A big part of this will of course be machine learning performance, which means supporting faster execution of smaller data types (e.g. INT4/INT8/FP16), and AMD even goes as far as to explicitly mention tensor ops. But this can’t come at the cost of traditional FP32/FP64 compute either; those supercomputers that AMD’s GPUs will be going in will be doing a whole lot of high precision math. So AMD needs to perform well across the compute and machine learning spectrum, across many data types.
To get there, AMD will also need to improve their performance-per-watt, as this is an area they have frequently trailed at. Today’s Financial Analyst Day announcement isn’t going into any real detail on how AMD is going to do this – beyond the obvious improvements in manufacturing processes, at least – but AMD is keenly aware of their need to improve.
All the while CDNA will also differentiate itself with features, including some things only AMD can do. Enterprise-grade reliability and security will be one leg here, including support for ever-popular virtualization needs.

But AMD will also be leaning on their Infinity Fabric to give them an edge in performance scaling and CPU/GPU integration. Infinity Fabric has been a big part of AMD’s success story this far on the CPU side of matters, and AMD is applying this same logic to the GPU side of matters. This means using IF to not only link GPUs to other GPUs, but using IF to link GPUs to CPUs. Which is something we’ve already seen in the works for AMD’s supercomputer wins, where both systems will be using IF to team up 4 GPUs with a single CPU.
AMD’s big win, however, will be a bit further down the line, when their 3rd gen Infinity Fabric is ready. It’s at that point where AMD intends to deliver a fully unified CPU/GPU memory space, fully leveraging their ability to provide both the CPUs and GPUs for a system. Unified memory can take a few different forms, so there are some important details that are missing here that will be saved for another day, but ultimately having a unified memory space should make programming heterogenous systems a whole lot easier, which in turn makes incorporating GPUs into servers all the better choice.
And since CDNA is now its own branch of AMD’s GPU architecture – with command of it falling under data center boss Forrest Norrod, interestingly enough – it also has its own roadmap with multiple generations of GPUs. With AMD treating Vega 20 as the branching point here, the company is revealing two generations of CDNA to come, aptly named CDNA (1) and CDNA 2.

CDNA (1) is AMD’s impending data center GPU. We believe this to be AMD’s “Arcturus”, and according to AMD it will be optimized for machine learning and HPC uses. This will be an Infinity Fabric-enabled part, using AMD’s second-generation IF technology. Keeping in mind that this is a high level overview, at this point it’s not super clear whether this part is going in either of AMD’s supercomputer wins; but given what we know so far about the later El Capitan – which is now definitely using CDNA 2 – CDNA (1) may be what’s ending up in Frontier.
Following CDNA (1) of course is CDNA 2. AMD is not sharing too much in the way of details here – after all, they haven’t yet shipped the first CDNA let alone the second – but they have confirmed that it will incorporate AMD’s third generation Infinity Fabric. As well, it will use a newer manufacturing node, which AMD is calling "Advanced Node" for now, as they are not disclosing the specific node they intend to use. So in a few different respects, CDNA 2 will be the piece de resistance of AMD’s heterogeneous compute plans, where they finally get to have a unified, coherent memory system across discrete CPUs and GPUs.
As for shipping dates, while AMD isn’t disclosing exact dates at this time, the roadmap itself only extends to the end of 2022, meaning that AMD expects to be shipping CDNA 2 in volume by then. This aligns fairly well with this week’s El Capitan announcement, which has the supercomputer being delivered in 2023.
Overall, AMD has some significant ambitions for their future data center GPUs. And while they have a lot of catching up to do to realize those ambitions, they’ve certainly laid out a promising roadmap to get there. AMD isn’t wrong about the importance of the data center market from both a technology perspective and a revenue perspective, and having a dedicated branch of their GPU architecture to get there may be just what AMD needs to finally find the success they seek.








25 Comments
View All Comments
brucethemoose - Thursday, March 5, 2020 - link
Sweet... But I hope the software side of things gets some love?I don't know much about datacenter compute, but CUDA code is absolutely *everywhere* in academic and tinkerer AI stuff, and I've had no luck getting the ROCM PyTorch branch to compile, much less run existing projects...
mode_13h - Sunday, March 8, 2020 - link
I got bad news for you: HIP uses ROCm. So, you're still stuck with getting the ROCm stack to work. Compiling CUDA code will just add another step of using their HIP toolchain to convert it.https://gpuopen.com/compute-product/hip-convert-cu...
Personally, I hope they stay committed to OpenCL. I don't want to use CUDA, even on Nvidia GPUs.
One thing I like about Intel's oneAPI strategy is that it's built on OpenCL/SYCL.
JayNor - Monday, June 8, 2020 - link
Intel's oneAPI is open, so AMD could add an openCL backend if they want.Codeplay announced doing a native CUDA backend for oneAPI. The oneAPI use of SYCL doesn't have dependencies on an openCL implementation.
A quote from Codeplay:
"This project enables you to target NVIDIA GPUs using SYCL code, without having to go through the OpenCL layer in the system. "
OranjeeGeneral - Sunday, March 8, 2020 - link
You've hit the problem right on the nail. AMD is super bad at the software side, No hardware in the world will sell if you can't figure out the API/software side. There is barely any serious DeepLearning framework not even an inference engine framework out there that support AMD hardware. Why? Because they have no API/framework that is anywhere as good as CuDNN/CUDA. And no engineers / manpower that actually would help those frameworks to implement and support these backend at day ONE.If AMD does not fix this issue they will never get any traction. You can not do this on a shoestring budget and always say yeah but we prefer OpenAPIs blablablabla. Barely anybody in the DL world give a shit of open compute APIs anymore. OpenCL has pretty much failed to be of any serious competition.
mode_13h - Sunday, March 8, 2020 - link
AMD has maintained forks of these frameworks for years. I don't know how much of this code has been merged back into their trunks, but you incorrectly speak as if AMD hasn't been working on it. Here are two biggies. I remember seeing more, but perhaps that means they've gotten support for the other frameworks merged.https://github.com/ROCmSoftwarePlatform/tensorflow...
https://github.com/ROCmSoftwarePlatform/pytorch
Where AMD messed up is by putting all their eggs in the OpenCL basket, and hoping that would be enough. Meanwhile, Nvidia was seeding CUDA usage throughout academia and they were fairly quick to offer the cudnn library of accelerated deep learning primitives. So, it's natural that CUDA gained some momentum, even as far back as when AMD hardware still had a compute power advantage.
Meanwhile, AMD decided it needed to overhaul its software architecture, so a lot of resources went into KFD and ROCm, which involved years of out-of-tree patches and a frustrating user experience for anyone trying to get the stack running with AMD hardware.
In spite of all of this, AMD does have a first class in-tree kernel driver (not like Nvidia, whose NVLink no longer works it new kernels for related reasons) and it *does* have a good amount of momentum on the software front. These are still advantages it holds over many of the AI hardware startups trying to enter this space.
So, it's *possible* that AMD could finally succeed in being an AI hardware player, but still not a given. AMD would need to put forth a level of effort and focus beyond what they've done 'till now, which was barely enough to catch up to where Nvidia had been, a couple years prior. I'm not betting on their success, here, but they *have* been doing considerably more than you say.
JayNor - Monday, June 8, 2020 - link
AMD's Frontier project ENA nodes appear to be modifying the 64 core Rome chiplet design, cutting it back to 4 cores per chiplet, then adding another 8 chiplets of GPUs ... with 32 CUs per GPU chiplet. Their stated requirement if for each node to be within 200W and to deliver 10TFlops FP64."Given the performance goal of 1 exaflop and a power budget of 20MW for a 100,000-node exascale machine, we need to architect the ENA node to provide10 teraflops of performance in a 200W power envelope."
"The EHP uses eight GPU chiplets. Our initial configuration provisions 32 CUs per chiplet. "
"The EHP also employs eight CPU chiplets (four cores each), for a total of 32 cores, with greater parallelism through optional simultaneous multi-threading."
That's all excerpts from this 2017 document ... I haven't seen any other description. Has there been an update?
https://www.computermachines.org/joe/publications/...
scineram - Monday, August 17, 2020 - link
Frontier is literally Arcturus which is literally a monolithic chip.ballsystemlord - Thursday, March 5, 2020 - link
Spelling and grammar errors:"AMD's goals for CDNA are simple and straightforward: build family of big,..."
Missing "a":
"AMD's goals for CDNA are simple and straightforward: build a family of big,..."
"And while they have a lot of catching do to realize those ambitions,..."
"up" not "do":
"And while they have a lot of catching up to realize those ambitions,..."
ballsystemlord - Thursday, March 5, 2020 - link
@Ryan , will some of these CDNA GPUs be made available for consumers to purchase at consumer level pricing, or are they enterprise only?Ryan Smith - Thursday, March 5, 2020 - link
Unfortunately AMD isn't talking about specific GPUs or SKUs at this time. But considering the target market, I don't expect to see AMD sell CDNA parts for cheap if they can avoid it. They're trying to compete with high-end Teslas, after all.