The NVIDIA GPU Tech Conference 2017 Keynote Live Blog
by Ryan Smith on May 10, 2017 11:45 AM EST
11:51AM EDT - I'm here at NVIDIA's keynote at their annual GPU Technology Conference
11:52AM EDT - So far the WiFi is holding up, but if I get quiet for a bit, you can take a good guess as to why
11:54AM EDT - The press posse is here in full, and the analysts are mixed in here as well
11:54AM EDT - It's going to be a full house. At this point NVIDIA is using pretty much every bit of space at the San Jose Convention Center for GTC
11:55AM EDT - Meanwhile I expect it to be a bit of a party atmosphere for the NVIDIA employees and management
11:56AM EDT - NVIDIA just posted an amazing Q1'FY18 result yesterday afternoon. The company's revenue is growing by leaps and bounds across pretty much all segments
11:57AM EDT - The song playing right now? "I'm on top of the world"
11:58AM EDT - So what are we expecting this year?
11:59AM EDT - NVIDIA's datacenter business is booming thanks to neural networking advances and Pascal products, so that will be a big focus
11:59AM EDT - NVIDIA's datacenter business is booming thanks to neural networking advances and Pascal products, so that will be a big focus
12:00PM EDT - NVIDIA and Jen-Hsun will want to continue to grow that business, and that means providing more hardware and more tools (and more training) for developers
12:00PM EDT - On the hardware side, we *may* see something about their forthcoming Volta architecture
12:01PM EDT - As a reminder, NVIDIA is scheduled to deliver Volta cards to Oak Ridge National Laboratory this year as part of their recent US supercomputer contract win. So this would be the time to talk Volta
12:01PM EDT - It's also the most reasonable explanation for why NVIDIA delayed the show from March of this year to May
12:02PM EDT - WiFi is struggling as everyone gets seated and tries to Periscope this...
12:02PM EDT - On that note, there is an official NVIDIA livestream: http://www.nvidia.com/page/home.html
12:03PM EDT - As for other NV announcements, except the usual bits about self-driving cars. Maybe something about their success with the Nintendo Switch as well
12:07PM EDT - And here we go
12:07PM EDT - WiFi is all but dead at this point
12:07PM EDT - Starting things off with a thematic intro video about AI
12:09PM EDT - Here's Jen-Hsun
12:10PM EDT - "Life after Moore's Law"
12:12PM EDT - Microprocessor performance has improved by nearly a million times in the last 30 years
12:12PM EDT - But in the last several years, progress has slowed, both in improving manufacturing processes and improving IPC
12:13PM EDT - We're now at the end of 2 roads
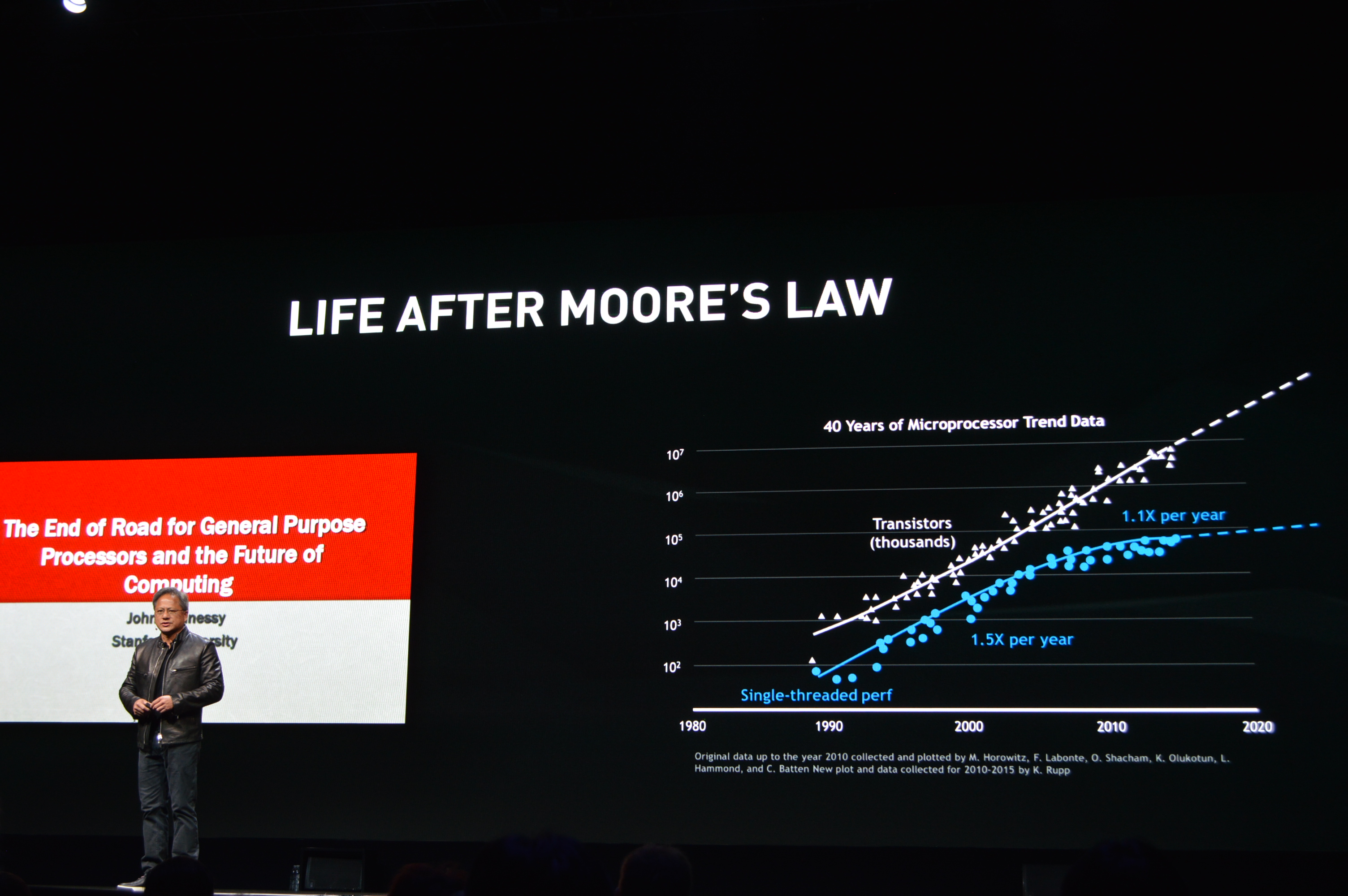
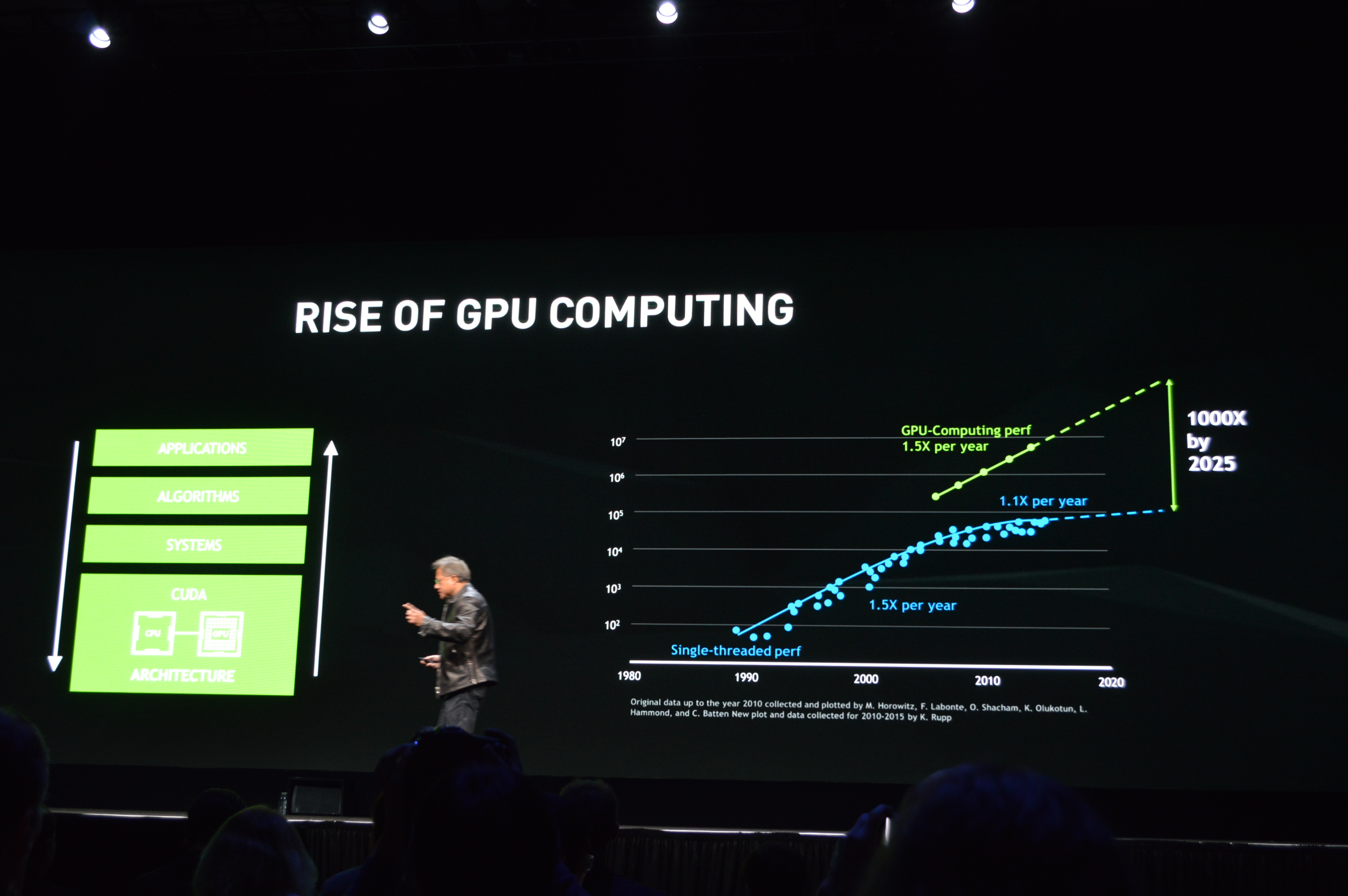
12:16PM EDT - Now recapping how GPUs are a domain-specific accelerator to serial-processing CPUs
12:18PM EDT - Parallel processing and GPUs need to be available everywhere
12:19PM EDT - The catch in making all of this happen? Mapping workloads to parallel computing, which isn't human-intuitive
12:19PM EDT - NVDIA has now been at this for a decade (since the launch of G80)
12:19PM EDT - So they've laid a lot of the groundwork to make all of this happen, and are now reaping the rewards

12:20PM EDT - "GTC has been growing so fast". 3x attendees in 5 years
12:21PM EDT - And this is even with NVIDIA holding opther GTCs on other continents
12:22PM EDT - "10 out of the world's top 10 car companies are here"
12:23PM EDT - Announcing "Project Holodeck"

12:24PM EDT - (A fistful of Datas not included, I hope)
12:24PM EDT - Demo time

12:25PM EDT - Holodeck: VR + full motion tracking + avatars
12:25PM EDT - All of this is rendered in real time
12:26PM EDT - The demo isn't quite working as well as it should
12:26PM EDT - The guest speaker's voice isn't coming through
12:26PM EDT - Okay, kinks worked out
12:27PM EDT - Showing off a rendering of a hyper car with the presenters' avatars in the same space

12:28PM EDT - Jen-Hsun is a car guy, of course, so if he can work in a car presentation, he's happy

12:29PM EDT - This is admittedly rough right now, but you can get an idea of where NVIDIA would like to go
12:30PM EDT - VR for the immersion, highly accurate graphical rendering and physics simulation to support the environment
12:30PM EDT - Early access in September
12:30PM EDT - Moving on. "Era of Machine Learning"
12:31PM EDT - Jen-Hsun is listing examples of services that are powered by machine learning
12:32PM EDT - "One of the most important revolutions ever"
12:32PM EDT - "Computers are learning by themselves"
12:36PM EDT - Jen-Hsun is continuing to recap the growth of capabilities of neural network based AI in the last 5 years

12:39PM EDT - A recent innovation: adversarial networks. One network that tries to fool another network, and the second network tries not to be fooled
12:39PM EDT - Each one reinforces the behavior you want in the other one

12:42PM EDT - One example: using deep learning to fill in incomplete ray-traced images
12:43PM EDT - Getting ray-traced-like quality without hasving to process all of the rays
12:44PM EDT - Essentially a very clever implementation of interpolation to reduce computational needs
12:44PM EDT - The most popular course at Stanford is apparently Introduction to Machine Learning

12:45PM EDT - "We have democratized computing"
12:46PM EDT - "Our strategy: create the most productive platform for machine learning"
12:47PM EDT - Recapping all of the frameworks NVIDIA supports, and all of the cloud services that offer NVIDIA GPUs
12:48PM EDT - "Every single cloud company in the world has NVIDIA GPUs provisioned in the cloud"
12:49PM EDT - Meanwhile NVIDIA is still doing fundamental and applied research in the AI field

12:53PM EDT - Video time: a SAP service that uses AI to count up how often an advertiser's brand is presented in a video clip
12:53PM EDT - SAP Brand Impact
12:56PM EDT - Now discussing how increasing GPU performance is allowing AI model complexity to grow
12:56PM EDT - Now it's time to the "next chapter of computing"
12:57PM EDT - "The most complex project that has ever been undertaken" Presumably by NVIDIA
12:57PM EDT - Tesla V100
12:58PM EDT - 815mm2, TSMC 12nm FFN, 21B transistors

12:59PM EDT - 15 TFLOPS FP32, 7.5 TFLOPS FP64
01:00PM EDT - 20MB register file, 16MB cache, 16GB of HBM2 at 900GB/sec. NVLink 2 at 300GB/sec
01:00PM EDT - R&D Budget: $3B USD


01:01PM EDT - A new Tensor operation isntruction in Volva. A*B+C into a FP32 result
01:02PM EDT - 4x4 Multiply + C at the same time

01:03PM EDT - Versus Pascal: 1.5x general purpose FLOPS, but 12x Tensor FLOPS for DL training
01:05PM EDT - NVIDIA is basically doubling-down on deep learning by adding more instructions (and therefore hardware) that is specialized for deep learning
01:05PM EDT - Not entirely clear if these are seperate cores, or new instructions in NVIDIA's standard CUDA cores
01:06PM EDT - Though it sounds like the latter
01:07PM EDT - And one can't reiterate enough how stupidly large the GV100 GPU is here. 815mm2 is massive for a GPU die. It's apparently the reticle limit for TSMC
01:08PM EDT - NV has quickly moved on from Volta. Now back to demos

01:09PM EDT - Galaxy simulation
01:10PM EDT - 7-8x perf improvement in 5 years
01:13PM EDT - These demos are all being run on Volta, BTW

01:15PM EDT - What was possible on Titan X (Maxwell) in a few minutes is now possible on Volta in a few seconds

01:16PM EDT - Now discussing performance gains on the Caffe2 and Microsoft Cognative Toolkit frameworks
01:17PM EDT - A 64 Volta setup can complete ResNet -50 in a couple of hours
01:19PM EDT - Now on stage: Matt Wood of Amazon AWS
01:21PM EDT - Volta will be the foundation for AWS's next general purpose GPU instance
01:23PM EDT - Offering NV GPUs has been very successful for Amazon. Customers apparently like it a lot
01:24PM EDT - Product announcement: DGX-1 with Tesla V100 (DGX-1V)
01:25PM EDT - 8 Tesla V100s in an NVLink Hybrid Cube arrangement
01:25PM EDT - $149,000, orders start today
01:25PM EDT - 960 Tensor TFLOPS (Jen-Hsun is lamenting that he doesn't have another 40 TFLOPS)
01:25PM EDT - Delivery in Q3
01:26PM EDT - Volta in Q3 in DGXes, Q4 for OEMs
01:26PM EDT - All DGX_1 orders are now going to be for DGX-1V, it seems


01:27PM EDT - Next product: DGX Station. A personal DGX with 4x Tesla V100s. 1500W, water cooled
01:28PM EDT - For deep learning engineers
01:28PM EDT - $69,000

01:28PM EDT - Orders starting now
01:29PM EDT - Next product: HGX-1. A server for cloud conputing
01:29PM EDT - 8x Tesla V100 in a hybrid cube. GPUs can be virtualized and provisioned as a cloud provider sees fit. So public cloud hosting

01:31PM EDT - Now on stage: Jason Zander, CVP of MS's Azure division
01:33PM EDT - Jen-Hsun and Jason are shooting the breeze on what MS can do with machine learning
01:34PM EDT - Like AWS, MS's Azure business has been a major success for the company

01:36PM EDT - Shipping Volta GV100 in volume in 2017 would be very impressive. Both because of the sheer size of the thing, and because it's only a year after they've done the same with Pascal
01:36PM EDT - Announcing Tensorrt for TeensorFlow. Compiler for deep learning inferencing

01:37PM EDT - TensorRT, even (everything in NV's titles are capitalized)
01:40PM EDT - Discussing both throughput and latency of inference
01:40PM EDT - The latter being a particular interesting point, since NV is normally throughput-focused
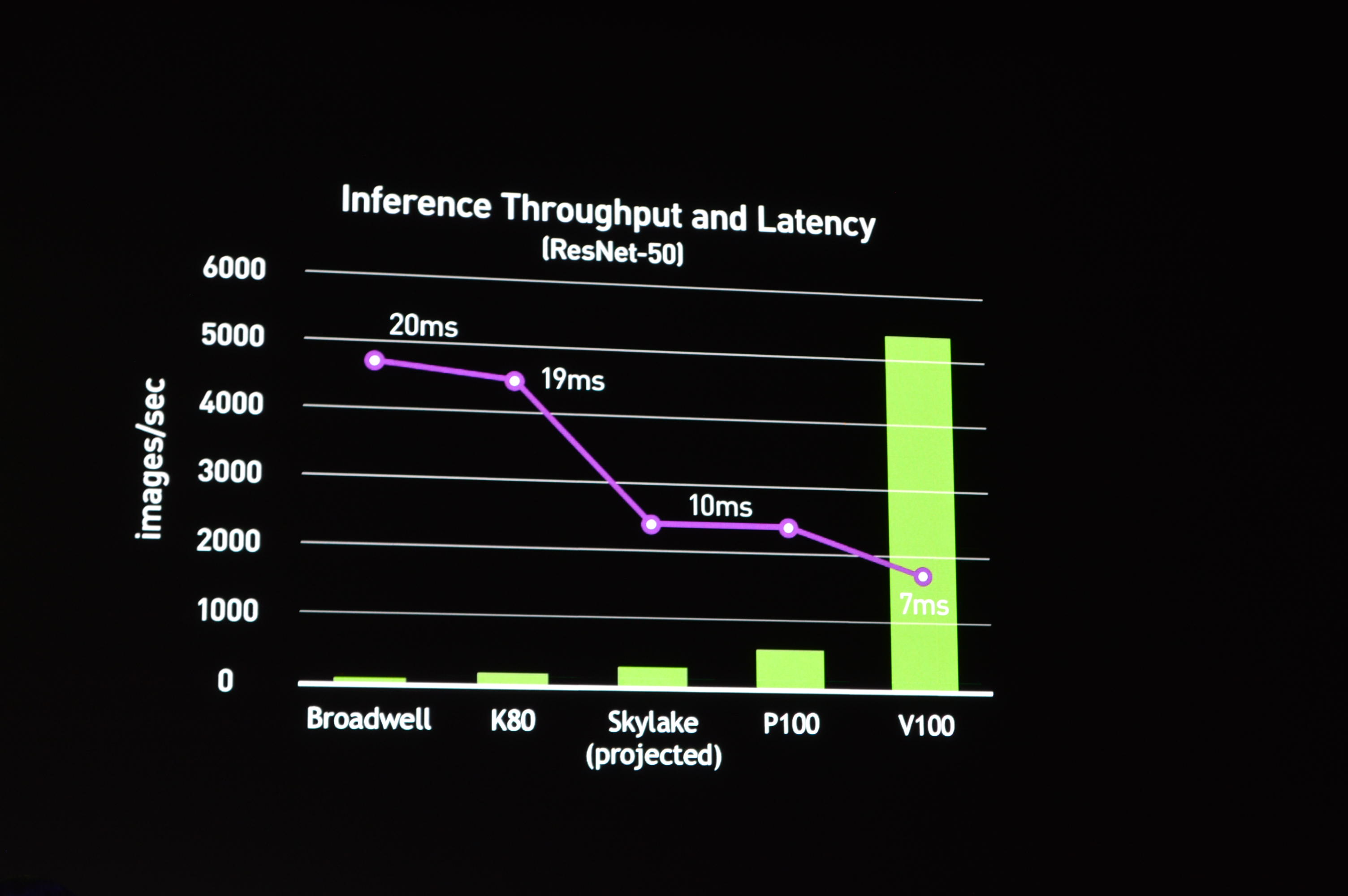
01:41PM EDT - Next product announcement: Tesla V100 for Hyperscale Inference
01:42PM EDT - A 150W full height half-length PCIe card



01:44PM EDT - Now Jen-Hsun makes his salesman pitch for why all of these accelerators make sense or datacenters
01:45PM EDT - Assuming your work perfectly maps to a GPU, then you can get racks of CPU servers in a much smaller number of GPU servers
01:45PM EDT - (Some workloads do scale like that, many others scale, but not quite that well)
01:46PM EDT - Interesting that NV is pitching Tesla V100 for interfencing. With Pascal, P100 was for training, other products like P40 were for inferencing

01:46PM EDT - Next announcement: NVIDIA GPU Cloud
01:47PM EDT - A full turnkey GPU deep learning platform
01:47PM EDT - "Containerized" with virtual machines pre-configured for the task at hand. Configure in a few minutes
01:47PM EDT - "NVDocker" container

01:48PM EDT - NVIDIA isn't doing their own cloud. Rather NV provides the software and a registry
01:48PM EDT - In other words they are being a middle-man: provide the software and point you to the cloud services that can run it
01:49PM EDT - Random aisde: the name of NV's internal DGX computer for development use is "Saturn V"
01:50PM EDT - Now demoing the NV GPU Cloud. Private beta is being offered to all GTC attendees
01:52PM EDT - Will support numerous permutations of software stack versions and GPUs "for as long as we live"
01:52PM EDT - Beta in July
01:53PM EDT - Now talking about AI at the edge
01:54PM EDT - Talking about the need to improve AI automation of driving


01:58PM EDT - Self-driving car tech demos
01:59PM EDT - NV provides the middleware. Partners put the finishing touches on the rest
02:00PM EDT - Toyota has selected NV Drive PX platform for their autonomous vehicles

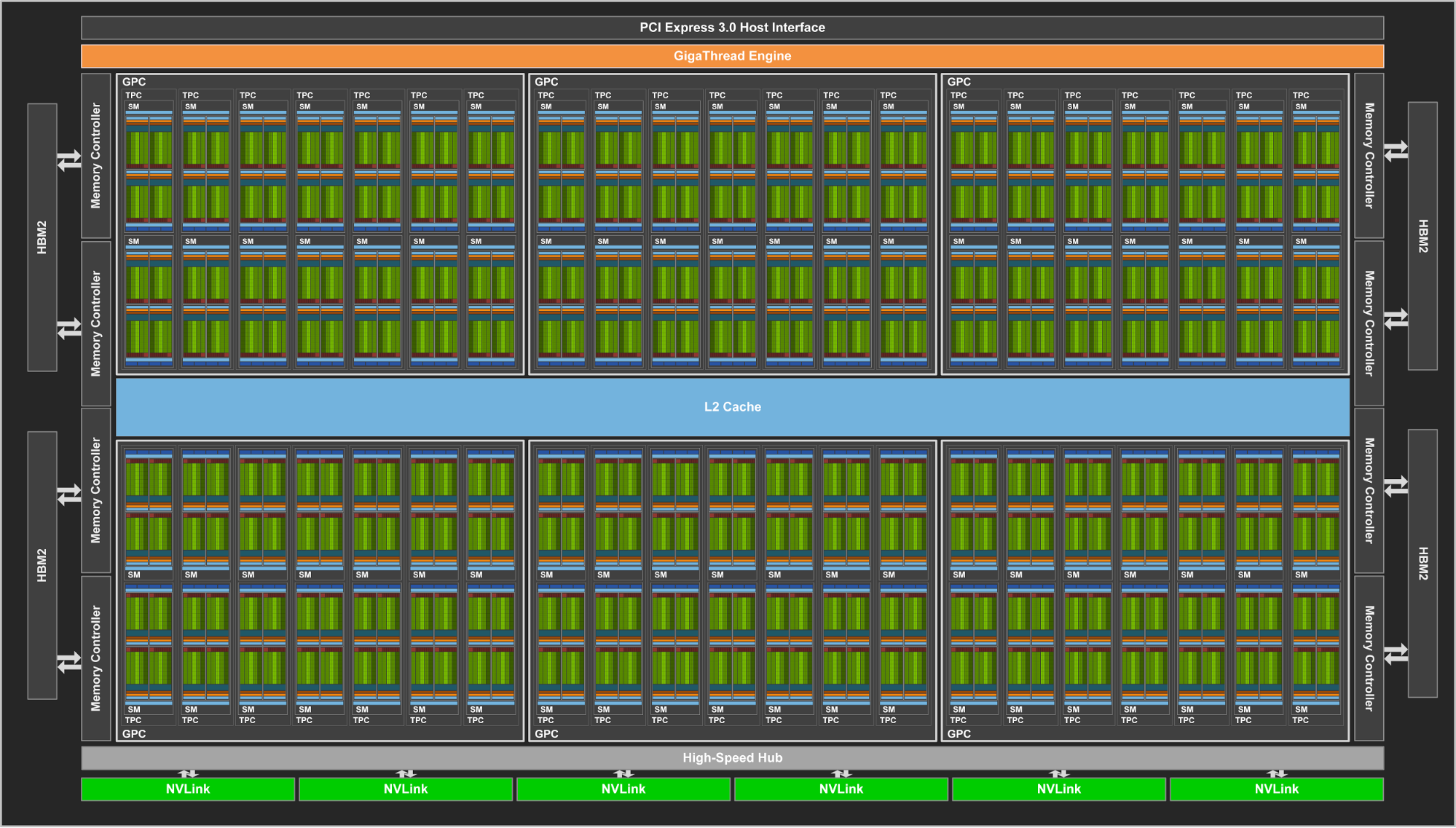
02:03PM EDT - Now discussing Xavier SoC. Previously announced in 2016, this will be using a Volta-architecture GPU

02:04PM EDT - Xavier combines a CPU for single-threading, a GPU for parallel work, and then Tensor cores for deep learning
02:05PM EDT - NVIDIA is going to open source Xavier's deep learning accelerator

02:06PM EDT - This could prove a big deal, but at this point Jen-Hsun is moving very quickly
02:08PM EDT - Now talking about robots and deep learning to train them
02:09PM EDT - (ed: bite my shiny metal... GPU)
02:10PM EDT - Announcing the Isaac robot simulator
02:10PM EDT - (Both Asimov and Newton, for anyone asking which isaac it is)
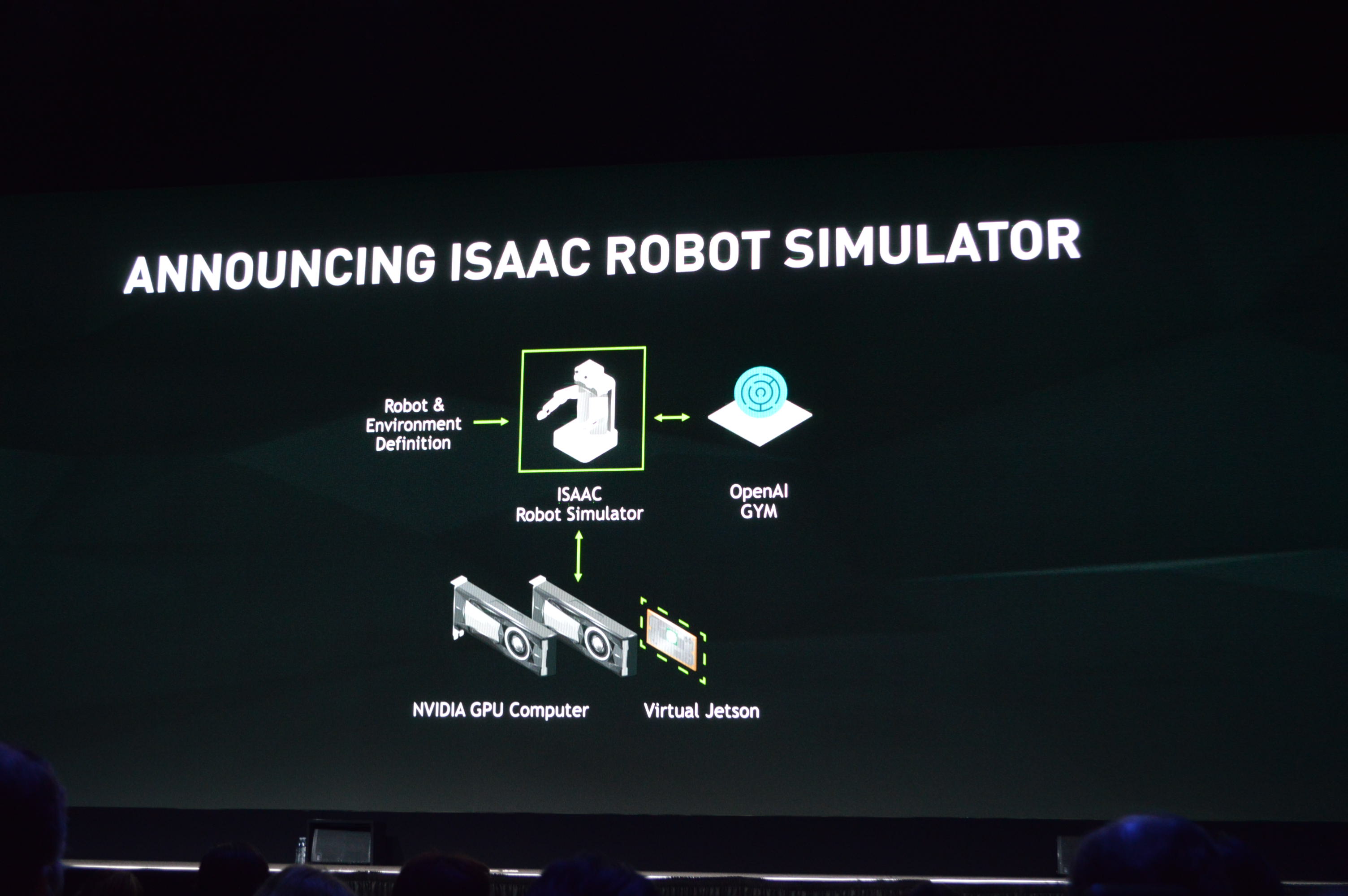
02:11PM EDT - Training a robot for the physical world in a virtual world
02:11PM EDT - So have a GPU do physics calculations, and another GPU does the neural network training based on those physics results

02:12PM EDT - Genetic algorithms meets neural networking
02:13PM EDT - Teaching a robot how to play hockey
02:14PM EDT - Can also be taught to golf
02:16PM EDT - That was the last presentation. Now recap time
02:18PM EDT - Accelerated computing, Volta & Tesnor Core, TensorRT, DGX & HGX systems, NVIDIA GPU Cloud, Xavier DLA open source, Toyota adopting Drive PX, and Isaac
02:18PM EDT - That's a wrap. Off to get more info about Volta








23 Comments
View All Comments
jackstar7 - Wednesday, May 10, 2017 - link
Always a treat when a livestream from a tech company keeps dropping out...littlebitstrouds - Wednesday, May 10, 2017 - link
Always a treat when a tech person thinks livestreaming involves only technology...jjj - Wednesday, May 10, 2017 - link
So V100 is towards 1.5GHz, no bump in clocks vs P100 ( or Volta vs Pascal).jjj - Wednesday, May 10, 2017 - link
Vega with its delays lost an entire cycle and will now compete with Volta.jjj - Wednesday, May 10, 2017 - link
"DGX Station. A personal DGX with 4x Tesla V100s. 1500W, water cooled"Suggests V100 stays below 300W with it's 5120 cores.
Nottheface - Wednesday, May 10, 2017 - link
So Volta Q4 for OEMS means we will have it in less than a month to us consumers???Really you're saying a card out in a month is competing with something coming out 7+ months from now?
DanNeely - Wednesday, May 10, 2017 - link
For that matter is Q4 to OEMs for any consumer variants, or just GV100 compute chips with GV102, etc coming a bit later?jjj - Wednesday, May 10, 2017 - link
@DanNeelyQ4 is for this ridiculous chip not anything else.
However, this is on a mature process, 12nm is just the latest version for 16nm so there is no reason to go for high ASP cards first where you can afford lower yields. Nvidia clearly has Volta ready and they will release consumer GPUs at any time they see fit, likely sooner than this 815mm2 chip.If Vega puts any pressure on Pascal, we get Volta fats, if not, Nvidia needs to boost revenues for the holidays so they'll do 1-2 SKUs this year and more next year.
jjj - Wednesday, May 10, 2017 - link
This is not a consumer card and its timing has little to do with consumer parts. AMD got absolutely obliterated today, Intel too for that matter.Now Volta vs Vega Instinct, just the new instruction in Volta puts Nvidia at least a generation ahead of AMD. The difference in timing is negligible, especially when you consider the adoption of the software platform for the 2 vendors.Vega would have ramped slow in deep learning but now has the Volta wall in front of it.
In consumer, Vega likely arrives as just Vega 10 at first and you can bet Nvidia has a couple of SKUs ready to go in Q3. Vega had zero positive leaks so far and it's unlikely that it can match Pascal in utilization (gaming perf per FLOPS). Aside from that there is power, GV100 has 43% more cores than GP100 at what appears to be similar clocks and TDP. There is a small gain from process but that's a huge efficiency gain.
This is really the first time Nvidia got serious about deep learning and showed thier hand, how they push forward.
AMD needs to learn to execute and be more aggressive, they could also use better timing in when to adopt a new technology- in general, could be a new instruction or a new type of memory and so on as AMD tends to go in to early and it costs them.
Intel needs a good leader and must be an outsider that hasn't been sheltered by the x86 monopoly.
Zingam - Wednesday, May 10, 2017 - link
If the use liquid helium coolant they might do it!