The NVIDIA GeForce GTX Titan X Review
by Ryan Smith on March 17, 2015 3:00 PM ESTGM200 - All Graphics, Hold The Double Precision
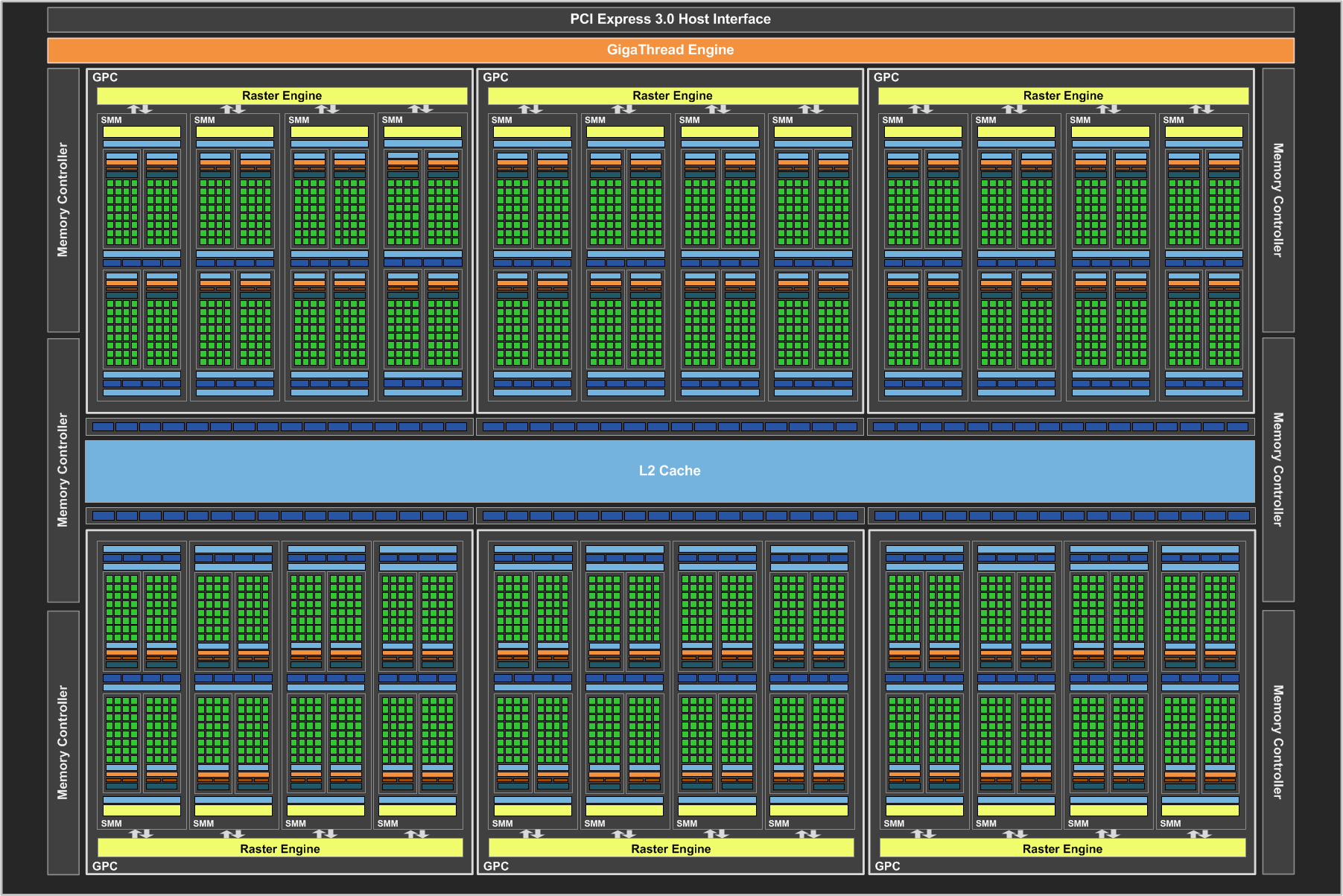
Before diving into our look at the GTX Titan X itself, I want to spend a bit of time talking about the GM200 GPU. GM200 is a very interesting GPU, and not for the usual reasons. In fact you could say that GM200 is remarkable for just how unremarkable it is.

From a semiconductor manufacturing standpoint we’re still at a standstill on 28nm for at least a little bit longer, pushing 28nm into its 4th year and having all sorts of knock-on effects. We’ve droned on about this for some time now, so we won’t repeat ourselves, but ultimately what it means for consumers is that AMD and NVIDIA have needed to make do with the tools they have, and in lieu of generational jumps in manufacturing have focused on architectural efficiency and wringing out everything they can get out of 28nm.
For NVIDIA those improvements came in the form of the company’s Maxwell architecture, which has made a concentrated effort to focus on energy and architectural efficiency to get the most out of their technology. In assembling GM204 NVIDIA built the true successor to GK104, putting together a pure graphics chip. From a design standpoint NVIDIA spent their energy efficiency gains on growing out GM204’s die size without increasing power, allowing them to go from 294mm2 and 3.5B transistors to 398mm2 and 5.2B transistors. With a larger die and larger transistor budget, NVIDIA was able to greatly increase performance by laying down a larger number of high performance (and relatively larger themselves) Maxwell SMMs.
On the other hand for GM206 and the GTX 960, NVIDIA banked the bulk of their energy savings, building what’s best described as half of a GM204 and leading to a GPU that didn’t offer as huge of a jump in performance from its predecessor (GK106) but also brought power usage down and kept costs in check.
Not Pictured: The 96 FP64 ALUs
But for Big Maxwell, neither option was open to NVIDIA. At 551mm2 GK110 was already a big GPU, so large (33%) increase in die size like with GM204 was not practical. Neither was leaving the die size at roughly the same area and building the Maxwell version of GK110, gaining only limited performance in the process. Instead NVIDIA has taken a 3rd option, and this is what makes GM200 so interesting.
For GM200 NVIDIA’s path of choice has been to divorce graphics from high performance FP64 compute. Big Kepler was a graphics powerhouse in its own right, but it also spent quite a bit of die area on FP64 CUDA cores and some other compute-centric functionality. This allowed NVIDIA to use a single GPU across the entire spectrum – GeForce, Quadro, and Tesla – but it also meant that GK110 was a bit jack-of-all-trades. Consequently when faced with another round of 28nm chips and intent on spending their Maxwell power savings on more graphics resources (ala GM204), NVIDIA built a big graphics GPU. Big Maxwell is not the successor to Big Kepler, but rather it’s a really (really) big version of GM204.
GM200 is 601mm2 of graphics, and this is what makes it remarkable. There are no special compute features here that only Tesla and Quadro users will tap into (save perhaps ECC), rather it really is GM204 with 50% more GPU. This means we’re looking at the same SMMs as on GM204, featuring 128 FP32 CUDA cores per SMM, a 512Kbit register file, and just 4 FP64 ALUs per SMM, leading to a puny native FP64 rate of just 1/32. As a result, all of that space in GK110 occupied by FP64 ALUs and other compute hardware – and NVIDIA won’t reveal quite how much space that was – has been reinvested in FP32 ALUs and other graphics-centric hardware.
| NVIDIA Big GPUs | ||||
| Die Size | Native FP64 Rate | |||
| GM200 (Big Maxwell) | 601mm2 | 1/32 | ||
| GK110 (Big Kepler) | 551mm2 | 1/3 | ||
| GF110 (Big Fermi) | 520mm2 | 1/2 | ||
| GT200 (Big Tesla) | 576mm2 | 1/8 | ||
| G80 | 484mm2 | N/A | ||
It’s this graphics “purification” that has enabled NVIDIA to improve their performance over GK110 by 50% without increasing power consumption and with only a moderate 50mm2 (9%) increase in die size. In fact in putting together GM200, NVIDIA has done something they haven’t done for years. The last flagship GPU from the company to dedicate this little space to FP64 was G80 – heart of the GeForce 8800GTX – which in fact didn’t have any FP64 hardware at all. In other words this is the “purest” flagship graphics GPU in 9 years.
Now to be clear here, when we say GM200 favors graphics we don’t mean exclusively, but rather it favors graphics and its associated FP32 math over FP64 math. GM200 is still a FP32 compute powerhouse, unlike anything else in NVIDIA’s lineup, and we don’t expect it will be matched by anything else from NVIDIA for quite some time. For that reason I wouldn’t be too surprised if we a Tesla card using it aimed at FP32 users such the oil & gas industry – something NVIDIA has done once before with the Tesla K10 – but you won’t be seeing GM200 in the successor to Tesla K40.
This is also why the GTX Titan X is arguably not a prosumer level card like the original GTX Titan. With the GTX Titan NVIDIA shipped it with its full 1/3 rate FP64 enabled, having GTX Titan pull double duty as the company’s consumer graphics flagship while also serving as their entry-level FP64 card. For GTX Titan X however this is not an option since GM200 is not a high performance FP64 GPU, and as a result the card is riding only on its graphics and FP32 compute capabilities. Which for that matter doesn’t mean that NVIDIA won’t also try to pitch it as a high-performance FP32 card for users who don’t need Tesla, but it won’t be the same kind of entry-level compute card like the original GTX Titan was. In other words, GTX Titan X is much more consumer focused than the original GTX Titan.

Tesla K80: The Only GK210 Card
Looking at the broader picture, I’m left to wonder if this is the start of a permanent divorce between graphics/FP32 compute and FP64 compute in the NVIDIA ecosystem. Until recently, NVIDIA has always piggybacked compute on their flagship GPUs as a means of bootstrapping the launch of the Tesla division. By putting compute in their flagship GPU, even if NVIDIA couldn’t sell those GPUs to compute customers they could sell them to GeForce/Quadro graphics customers. This limited the amount of total risk the company faced, as they’d never end up with a bunch of compute GPUs they could never sell.
However in the last 6 months we’ve seen a shift from NVIDIA at both ends of the spectrum. In November we saw the launch of a Tesla K80, a dual-GPU card featuring the GK210 GPU, a reworked version of GK110 that doubled the register file and shared memory sizes for better performance. GK210 would not come to GeForce or Quadro (though in theory it could have), making it the first compute-centric GPU from NVIDIA. And now with the launch of GM200 we have distinct graphics and compute GPUs from NVIDIA.
| NVIDIA GPUs By Compute | |||||
| GM200 | GK210 | GK110B | |||
| Stream Processors | 3072 | 2880 | 2880 | ||
| Memory Bus Width | 384-bit | 384-bit | 384-bit | ||
| Register File Size (Per SM) | 4 x 64KB | 512KB | 256KB | ||
| Shared Memory / L1 Cache (Per SM) |
96KB + 24KB | 128KB | 64KB | ||
| Transistor Count | 8B | 7.1B(?) | 7.1B | ||
| Manufacturing Process | TSMC 28nm | TSMC 28nm | TSMC 28nm | ||
| Architecture | Maxwell | Kepler | Kepler | ||
| Tesla Products | None | K80 | K40 | ||
The remaining question at this point is what happens from here. Was this divorce of compute and graphics a temporary action, the result of being stuck on the 28nm process for another generation? Or was it the first generation in a permanent divorce between graphics and compute, and consequently a divorce between GeForce/Quadro and Tesla? Is NVIDIA finally ready to let Tesla stand on its own?
With Pascal NVIDIA could very well build a jack-of-all-trades style GPU once more. However having already divorced graphics and compute for a generation, merging them again would eat up some of the power and die space benefits from going to 16nm FinFET, power and space that NVIDIA would likely want to invest in greater separate improvements in graphics and compute performance. We’ll see what Pascal brings, but I suspect GM200 is the shape of things to come for GeForce and the GTX Titan lineup.








276 Comments
View All Comments
FlushedBubblyJock - Saturday, March 21, 2015 - link
Wow, it's stomping all over 2 of AMDs best gpu's combined.It's a freaking monster.
cykodrone - Saturday, March 21, 2015 - link
I actually went to the trouble to make an account to say sometimes I come here just to read the comments, some of the convos have me rolling on the floor busting my guts laughing, seriously, this is free entertainment at its best! Aside from that, the cost of this Nvidia e-penis would feed 10 starving children for a month. I mean seriously, at what point is it overkill? By that I mean is there any game out there that would absolutely not run good enough on a slightly lesser card at half the price? When I read this card alone requires 250W, my eyes popped out of my head, holy electric bill batman, but I guess if somebody has a 1G to throw away on an e-penis, they don't have electric bill worries. One more question, what kind of CPU/motherboard would you need to back this sucker up? I think this card would be retarded without at least the latest i7 Extreme(ly overpriced), can you imagine some tool dropping this in an i3? What I'm saying is, this sucker would need an expensive 'bed' too, otherwise, you'd just be wasting your time and money.sna1970 - Saturday, March 21, 2015 - link
What dual GTX 980 Anand ?for 2 x $300 Gtx 970 you will get the same or better performance than Titan X for $600 ONLY.
almost same power as well.
$1000 for this card is too much , Just tooooo much.
rolfaalto - Saturday, March 21, 2015 - link
So much silly complaining about value. This is an incredible bargain for compute compared to Tesla -- absolutely crushes at single precision for a fraction of the price! For my application the new Titan X is the absolute best that money can buy, and it's comparatively cheap. So, I'll buy 10 of them, and 100 more if they work out.rolfaalto - Saturday, March 21, 2015 - link
... and the 12GB is the deal maker, 6 GB on the previous Titans was way too little.yiling cao - Sunday, March 22, 2015 - link
for people using cuda, there is just no AMD option, Upgrading every nvidia new releases.Antronman - Sunday, March 22, 2015 - link
Or, if you're the kind of person who actually needs CUDA and isn't just using it because they made a mistake in choosing their software and just chose something with a bloated price tag and fancy webpage then you get a Quadro card instead of wasting your money on a Titan.You know. The sort of people who need Solidworks because they're working for a multimillion or even multibillion dollar corporation that wants 3D models or is using GPU computing, or if you're using Maya to animate a movie for a multimillion dollar studio.
Even if you're an indie on a budget, you don't buy a Titan. Because you won't be using software with CUDA or special Nvidia optimization. Because you won't be using iRay.
With the exception of industry applications (excluding individual/small businesses), Nvidia is currently just a choice for brand loyalists or people who want a big epeen.
r13j13r13 - Sunday, March 22, 2015 - link
titan x vs R9 295x2MyNuts - Sunday, March 22, 2015 - link
Ill take 2 pleaseXsjado Koncept - Sunday, March 22, 2015 - link
Your "in-house project developed by our very own Dr. Ian Cutress" is garbage and is obviously not dividing workloads between multi-GPUs, a very simple task for any programmer with access to Google.It's plain as day to see, but gives NV the lead in another benchmark - was this the goal of such awful programming?