The last time we discussed CUDA and Tesla in depth was in September of 2010. At the time NVIDIA had just recently launched their lineup of Fermi-powered Tesla products, and was using the occasion to announce the 3.2 version of their CUDA GPGPU toolchain. And though when we’re discussing the fast pace of the GPU industry we’re normally referring to NVIDIA’s massive consumer GPU products arm, the Tesla and Quadro businesses are not to be underestimated. An aggressive 6 month refresh schedule is not just good for consumer products it seems, but it’s good for the professional side too.
Even against the backdrop of a 6 month refresh schedule, quite a bit has changed in the intervening period. NVIDIA’s Parallel Nsight – which we only first discussed in depth back in September – has gone free, with NVIDIA realizing that charging for the software wasn’t going to sell as many GPUs and that no one likes doing software licensing. Meanwhile the first (and thusfar only) Mac Fermi card was launched in the form of a Quadro card, helping NVIDIA go after the all-important niche of Mac desktop *nix programmers. Even the financial side of things is showing some change, with NVIDIA having just closed out Fiscal Year 2011 with nearly $100mil in Tesla sales, which at around 2.8% of NVIDIA’s revenue is the highest Tesla revenue has ever been. In fact the only thing we haven’t seen surprisingly enough is a Tesla refresh – we had GF110 pegged as an obvious upgrade for the Tesla line, which under GF100 continues to ship with only 448 SPs enabled to help meet the necessary 225W power envelope.

Meanwhile the CUDA team has been hard at work developing the next version of CUDA after CUDA 3.2, which brings us to today’s announcement. Today NVIDIA is announcing CUDA 4.0, the next full version of the toolchain. As is customary for CUDA development given its long QA cycle, NVIDIA is making their formal announcement well before the final version will be shipping. The first release candidate will be available to registered developers March 4th, and we’d expect the final version to be available a couple of months later based on NVIDIA’s previous CUDA releases.
CUDA 4.0 ends up being an interesting release as it breaks with NVIDIA’s previous release schedules somewhat. Previous CUDA releases were timed with the launch of hardware: CUDA 1.0 was released to go with G80/G9x (albeit nearly a year after they launched), CUDA 2.0 was released for GT200 in 2008, and CUDA 3.0 was released for Fermi in 2010. In the case of CUDA 4.0 there’s no new hardware to talk about at the moment, so it’s the first independent software-only major CUDA release. I’d expect that NVIDIA will still be on CUDA 4.x by the time Kepler launches, but that’s still several months out.
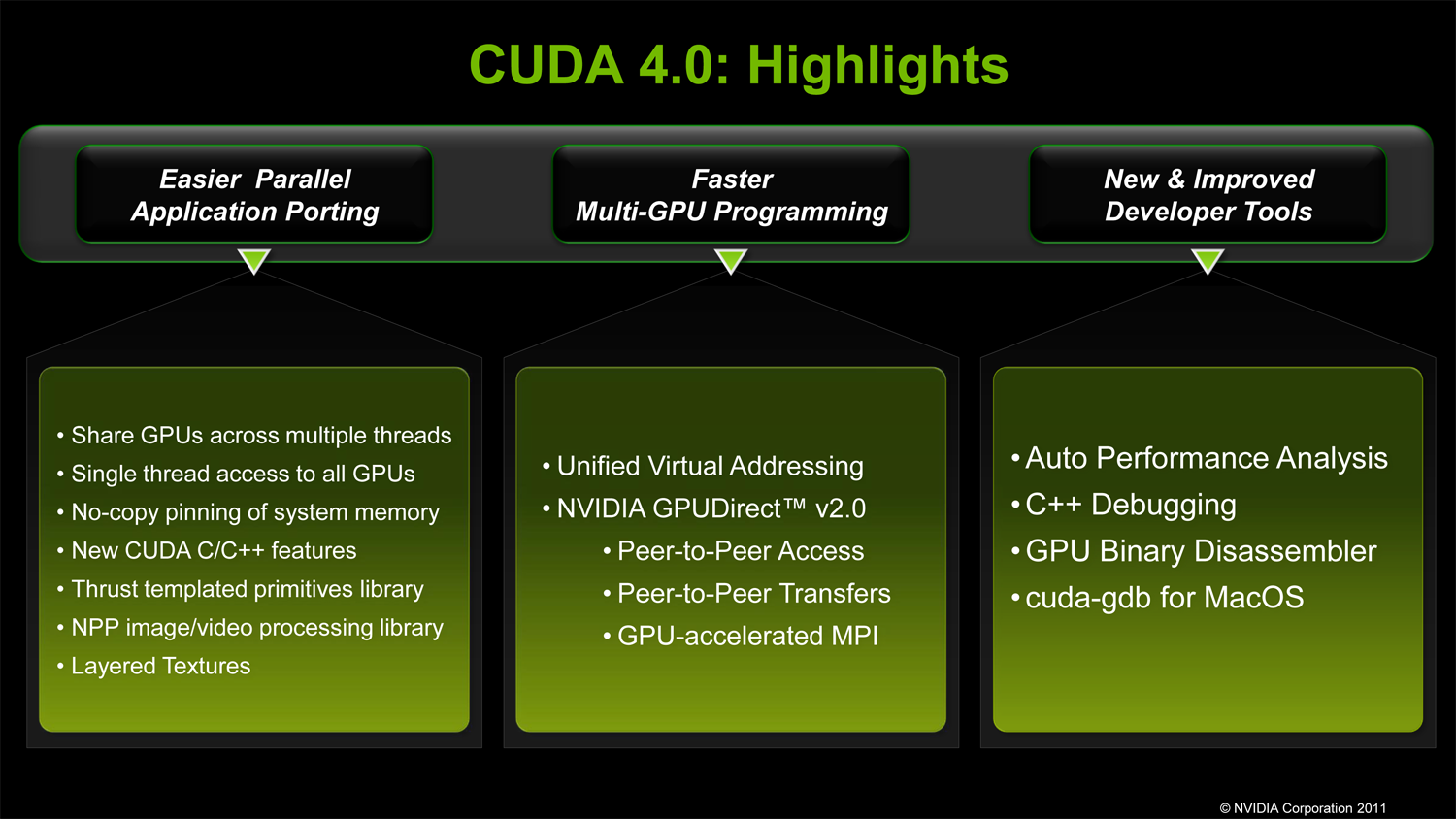
So what’s new in CUDA 4.0? As an independent software release NVIDIA’s biggest focus is on multi-GPU GPGPU performance of existing Fermi products. This is the next logical step for the company, as previous CUDA releases have continuously drilled down, starting with the basic CUDA framework which was suitable for embarrassingly parallel tasks that didn’t require intra-GPU communication, to CUDA 3.x which introduced GPUDirect thereby giving 3rd party devices direct access to CUDA memory. CUDA 4.0 in turn is the next step on that long path, and will be enabling multiple GPUs within the same system/node to more closely work together by making it easier for GPUs to access each other’s memory.
Specifically NVIDIA is doing a few things here. On the software side NVIDIA is introducing a new unified virtual address space mode (aptly named Unified Virtual Addressing), which puts all CUDA execution – CPU and GPU – in the same address space. Prior to this each GPU and the CPU used their own virtual address space, which required a number of additional steps and careful tracking on behalf of CUDA software to copy data structures between address spaces. This would seem to be riskier on the driver side in order to keep GPUs and CPUs from stomping on each other(and hence the long QA cycle), but for CUDA developers the benefit is going to be very straightforward due to the easier memory management.
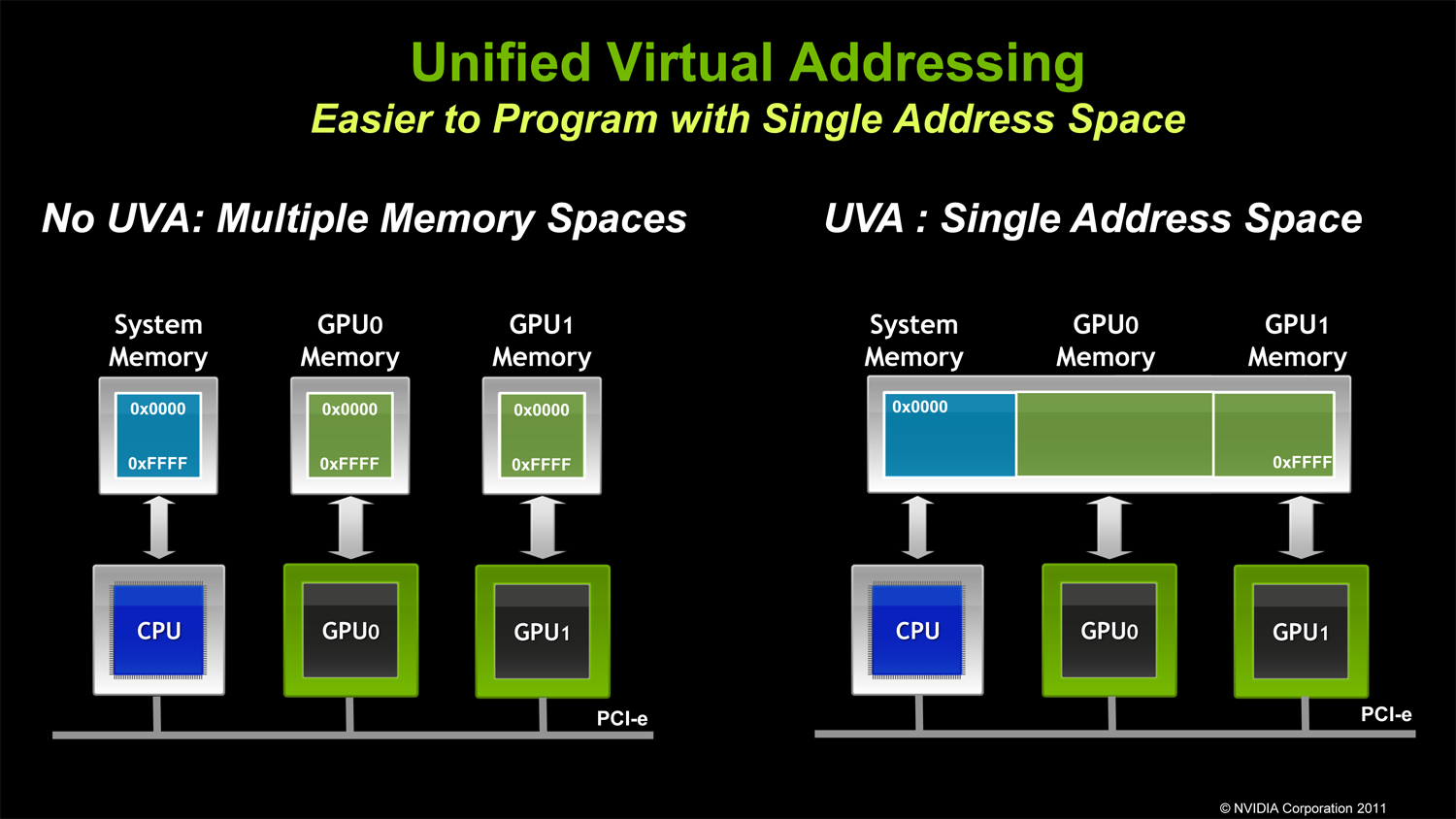
Meanwhile on the hardware side NVIDIA is introducing GPUDirect 2.0. While GPUDirect 1.0 gave 3rd party devices direct memory access, it was primarily for network/infiniband communication purposes; GPUs within a node were still isolated in most cases, requiring data structures to be copied to system RAM first before any additional GPUs could access the data. GPUDirect 2.0 resolves this issue, introducing the ability for GPUs within a node to directly access each other’s memory without requiring a system memory copy first. And while system memory is by no means slow this is still much faster; for fully fed PCIe x16 slots this gives each GPU 8GB/sec of low latency full duplex bandwidth to use between the CPU and other GPUs. From our impressions we’d categorize GPUDirect 2.0 as being very NUMA-like (Non-Uniform Memory Access), however there’s still an important distinction between local and remote memory as PCIe bandwidth is still a fraction the speed of local memory – 8GB/sec versus 148GB/sec for a Tesla card, for example.
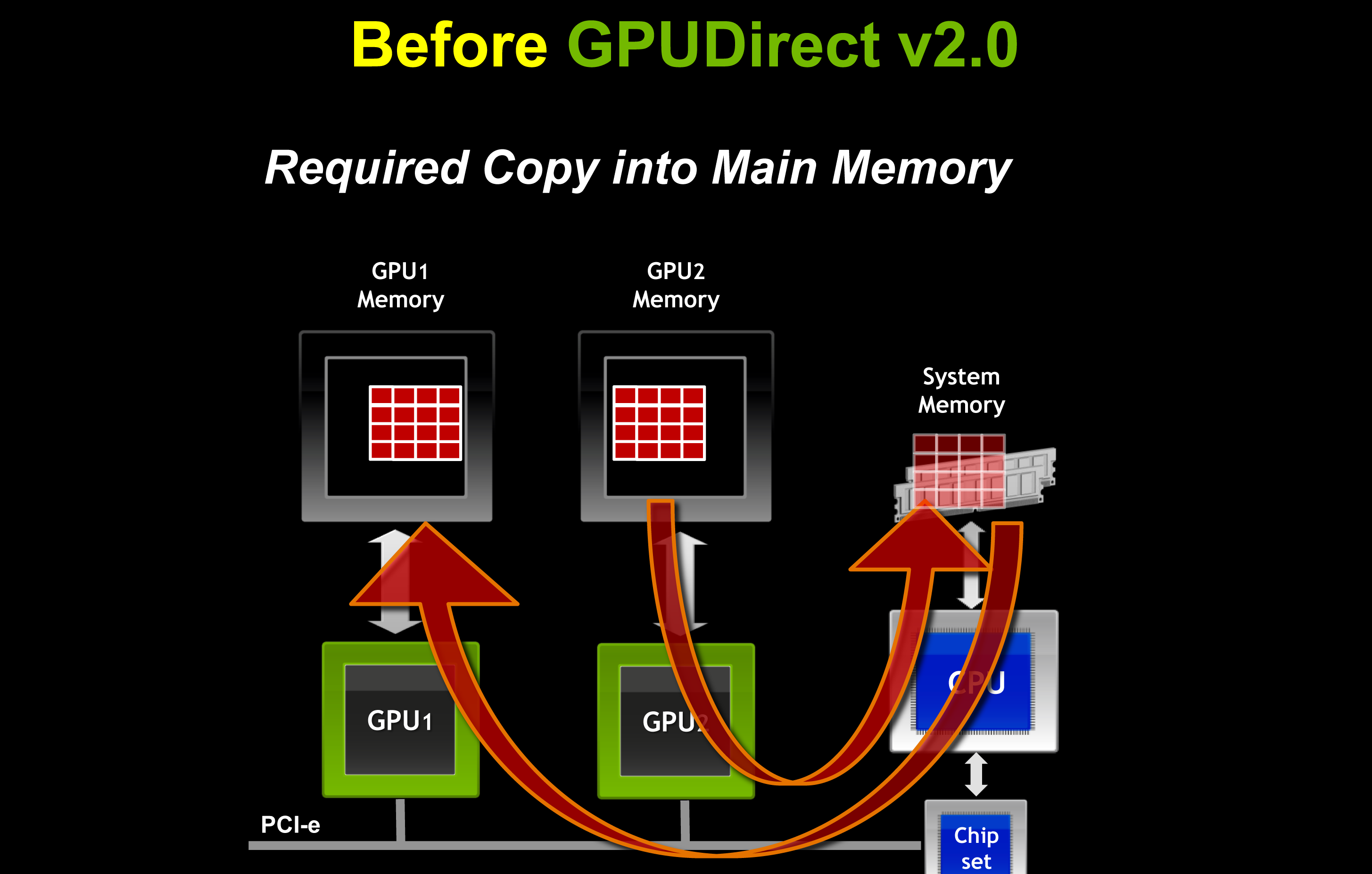
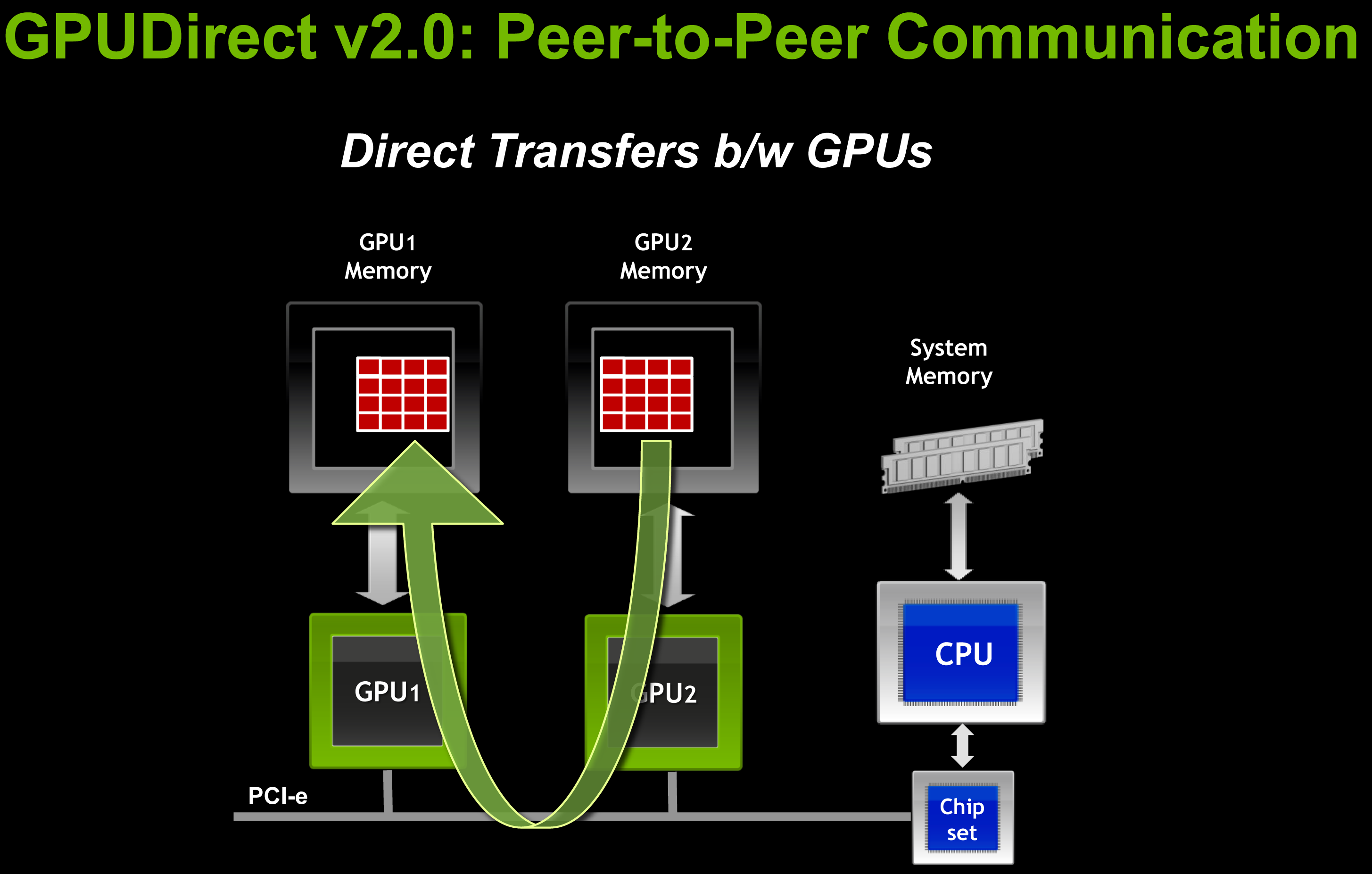
The addition of UVA on the software side and GPUDirect 2.0 on the hardware side are NVIDIA’s primary tactics to improving intra-GPU performance. PCIe’s limited bandwidth means that intra-GPU communication speeds will not be approaching intra-CPU communication speeds in the near future, so SMP-like operation is still some time off, but it should be fast enough to allow developers to work on new classes of problems that were too slow without UVA/GPUDirect.
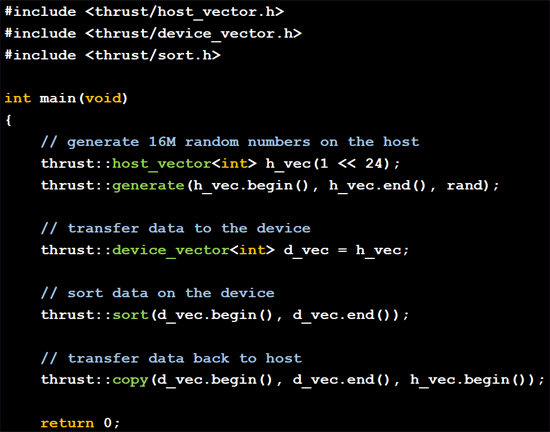
Along with multi-GPU performance, NVIDIA is of course giving considerable focus to single/overall GPU performance. CUDA 4.0 follows up on CUDA 3.2’s additional libraries with yet another set of performance-optimized libraries. Thrust – an open source CUDA template library that mimics the C++ Standard Template Library (STL) – is being integrated into CUDA proper. Thrust has been available for a couple of years now as an external library that NVIDIA developed as a research project, and is now being promoted to a member of the CUDA family. C++ programmers used to the STL stand the most to gain, as Thrust is nearly identical and can automatically handle assigning work to GPUs or CPUs as necessary.
CUDA C++ is also getting some further improvements by introducing some C++ features that were absent under CUDA 3.x. Virtual functions are now supported, along with the New and Delete functions for dynamic memory. NVIDIA noted that with CUDA 4.0 they’re shifting to working on developer requests, with both of these features being highly requested. We had also asked NVIDIA about what C++ adoption by developers had been like – C++ being an important part of the Fermi hardware – but unfortunately NVIDIA doesn’t have the means to precisely track which languages developers are actually using. However it sounds like adding C++ was an appropriate choice for the company.
Finally, the last set of improvements NVIDIA is focusing on is on the developer tools themselves. Coming back again to the Mac/*nix market, NVIDIA had added CUDA debugging support to Mac OS X; *nix CUDA developers doing their development on Macs will now be able to debug their code right on their machines. Meanwhile NVIDIA’s Visual Profiler performance profiling tool is getting an upgrade of its own: previously it could identify bottlenecks in code, now it can offer hints on how to improve performance at those bottlenecks. Finally, the CUDA toolkit will now include a binary disassembler, for use in analyzing the resulting output of the CUDA compiler.
Wrapping things up, as we mentioned before the first release candidate of CUDA 4.0 will be available to registered developers on March 4th. NVIDIA doesn’t have a commitment date for the release version, but expect it to be available a couple of months later based on NVIDIA’s previous CUDA releases.








44 Comments
View All Comments
DaveGirard - Monday, February 28, 2011 - link
I think the Mac CUDA audience is actually video pros, not Unix devs using Mac Pros. There are probably some educational/scientific users coding for CUDA on OS X but it would be dumb to use an expensive desktop to do a dumb Linux cruncher's job. Premiere Pro CS5, some Nuke and AE plug-ins, Da Vinci Resolve, etc are where they see CUDA being used on Macs.Sean Kilbride at NVIDIA told me that their focus appeal is on these video pros.
LTG - Monday, February 28, 2011 - link
CUDA reminds me of the old Prodigy or GEnie online services which were successful until internet standards took them out.GPUs are despately in need of more successful standards so things like OpenCL can flourish.
Yes CUDA has more advanced capabilities but why shouldn't it when NVidia invests so much more heavily in it? In the case of online services there were so many companies who could benefit from investing in Internet standards that it became a tidal wave and thwarted quite a few proprietary techs.
However so far GPUs don't have the open standard building investments to match CUDA so customers suffer. Internet standards steamrolled huge companies, but the same motivations don't exist here.
I don't like CUDA. Not because there is something better but because it diverts resources from something that could be better.
seibert - Monday, February 28, 2011 - link
OpenCL exists because of CUDA. NVIDIA is highly involved in the OpenCL process, and the programming model of OpenCL bears a strong resemblance to CUDA.You are asking for the end before the beginning. Ultimately, all data parallel hardware (GPUs, AMD Fusion, multicore + AVX, etc) will be programmed with something like OpenCL, but first we need to figure out as a development community what mix of hardware and software features we need. The committee process of OpenCL necessarily limits the feature set to the lowest common denominator. (Why would any company want to put out a standard that their hardware cannot support?) That's fine, and if OpenCL meets your needs, you should use it!
But these are still early days, and CUDA is an environment where NVIDIA is free to add new hardware features (or new language features) and immediately expose the API to developers. That's a great practical way to learn what is useful. Features which become critical will be adopted by many vendors and later appear in future OpenCL standards. Innovation seldom happens by committee.
But developers have to be aware that they multivendor hardware compatibility for features when they pick CUDA. That works for some people. (Although there is fascinating research going on at Georgia Tech investigating on-the-fly translation of CUDA to run directly on CPUs and AMD GPUs. This could be very interesting if you want to take advantage of CUDA language features not available in OpenCL yet.)
Basically, we don't have to operate under Highlander Rules. There can be many solutions to a problem without weakening the community. Standardization is important, but only after you know what the solution ought to look like.
raddude9 - Tuesday, March 1, 2011 - link
Wow, CUDA is openly specified.That's about as useful as an "open" microsoft word document, or Adobes Flash player, i.e. it's the kind of "openness" that gives "openness" a bad name.
The fact is that Nvidia is doing its best to use CUDA as a tool to lock people into it's own hardware. That's why I don't trust CUDA, Nvidia are free to make changes in every new version to force you to upgrade, and it will use CUDA as a tool to make money, and supporting users will come second.
C++ may be open, but once you start using microsoft's proprietary C++ libraries, you are letting yourself in for a world of hurt, I know, I've been there. Years ago Microsoft had promised that it would release MFC 5.0 for the Mac. So people started to upgrade the windows version knowing the mac version was on the way. Did they release it... No. Could a 3rd party port it. No.
Shining Arcanine - Tuesday, March 1, 2011 - link
I believe that AMD and Intel are free to implement CUDA support on their own hardware, much like other companies were free to implement FORTRAN. The only thing Nvidia will not do is doing that for them.Whether you like it or not, CUDA is the FORTRAN of the GPGPU world. OpenCL is basically ALGOL, which means that aside from some code examples from organizations that do not write production code, no one will use it.
Shining Arcanine - Tuesday, March 1, 2011 - link
That phrase should have been "much like how other companies were free to implement FORTRAN".samirsshah - Tuesday, March 1, 2011 - link
NVIDIA is very strong in mobile but they need to boost their efforts even more, three times more. Yes, PCs are good but the insights that NVIDIA gets designing for PCs may not always give good results for mobile, 'the law of diminishing returns' come to fore as one goes deep and deep into PC based design. A crude analogy is that the insights Intel gets from Core i7 may not always work for Atom. So sometimes you have to say that 'I am going to invert the pyramid' and care for mobile first.ChuckMilic - Wednesday, March 2, 2011 - link
Dig this: UVM + GPU-Direct 2.0 will allow GTX 590's two processors to share the 3 GB memory though 384-bit busses each.This explains all the delays and brings the software and hardware releases together. This totally redefines both compute and graphics capabilities. Imagine e.g. SLI without the need to store the entire image twice in two separate memories. Well worth all the wait!
IanCutress - Wednesday, March 2, 2011 - link
Best thing is, I've been reading about multi-GPU programming and host-pinned memory this week. Now I can throw it all out the window(s) with UVM.CUDA has been a big boon for my normal work - using an OCed 460, I've got a 4000x speed increase over single thread simulations previously used, and I'm able to probe molecular scales without long, drawn out simulation or scaling. The fact that I don't have to use a driver API also helps quite a bit.
But I'm a Windows developer, and sometimes trying to get it to work in Visual Studio on a fresh OS install is frustrating. I'd like to see some effort towards that of course.
Ian
sallychen - Wednesday, March 2, 2011 - link
Hey there, I find an amazing web,please click the web ,you can find big pleasantly surprised╭⌒╮WELCOME http://www.busymalls.com
----- ~ ¤ ╭⌒╮ ╭⌒╮
╭⌒╭⌒╮╭⌒╮~╭⌒╮ HANDBAG 35$
,)))),'')~~ ,''~)
╱◥█◣ ╱◥█◣ SHOES 35$
|田|田||田|田| CLOTH 15$
╬╬╬╬╬╬╬╬╬╬╬╬╬╬ 2010 NEW
input this URL:
(http://www.busymalls.com)
you can find many cheap and fashion stuff
jordan air max oakland raiders $30--39;
Ed Hardy AF JUICY POLO $20;
Handbags (Coach lv fendi d&g) $30
T shirts (Polo ,edhardy,lacoste) $15
Jean(True Religion,edhardy,coogi) $30
Sunglasses (Oakey,coach,gucci,Armaini) $15
New era cap $15
Bikini (Ed hardy,polo) $20
(http://www.busymalls.com)
WE ACCEPT PYAPAL PAYMENT
DELIVERY TO YOU DOOR TO DOOR
Free Shipping