The Intel Core i9-9990XE Review: All 14 Cores at 5.0 GHz
by Dr. Ian Cutress on October 28, 2019 10:00 AM ESTCPU Performance: Web and Legacy Tests
While more the focus of low-end and small form factor systems, web-based benchmarks are notoriously difficult to standardize. Modern web browsers are frequently updated, with no recourse to disable those updates, and as such there is difficulty in keeping a common platform. The fast paced nature of browser development means that version numbers (and performance) can change from week to week. Despite this, web tests are often a good measure of user experience: a lot of what most office work is today revolves around web applications, particularly email and office apps, but also interfaces and development environments. Our web tests include some of the industry standard tests, as well as a few popular but older tests.
We have also included our legacy benchmarks in this section, representing a stack of older code for popular benchmarks.
All of our benchmark results can also be found in our benchmark engine, Bench.
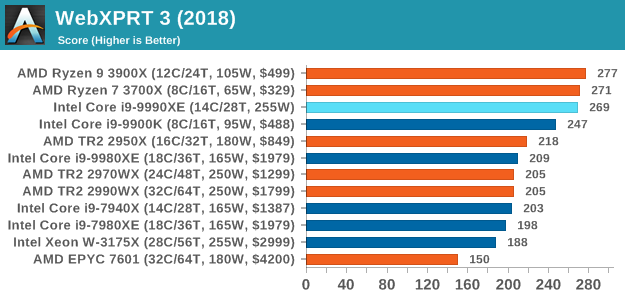
WebXPRT 3: Modern Real-World Web Tasks, including AI
The company behind the XPRT test suites, Principled Technologies, has recently released the latest web-test, and rather than attach a year to the name have just called it ‘3’. This latest test (as we started the suite) has built upon and developed the ethos of previous tests: user interaction, office compute, graph generation, list sorting, HTML5, image manipulation, and even goes as far as some AI testing.
For our benchmark, we run the standard test which goes through the benchmark list seven times and provides a final result. We run this standard test four times, and take an average.
Users can access the WebXPRT test at http://principledtechnologies.com/benchmarkxprt/webxprt/
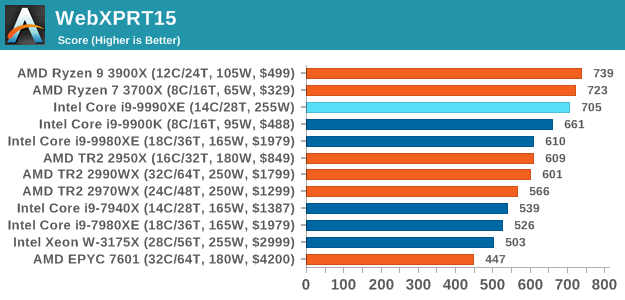
WebXPRT 2015: HTML5 and Javascript Web UX Testing
The older version of WebXPRT is the 2015 edition, which focuses on a slightly different set of web technologies and frameworks that are in use today. This is still a relevant test, especially for users interacting with not-the-latest web applications in the market, of which there are a lot. Web framework development is often very quick but with high turnover, meaning that frameworks are quickly developed, built-upon, used, and then developers move on to the next, and adjusting an application to a new framework is a difficult arduous task, especially with rapid development cycles. This leaves a lot of applications as ‘fixed-in-time’, and relevant to user experience for many years.
Similar to WebXPRT3, the main benchmark is a sectional run repeated seven times, with a final score. We repeat the whole thing four times, and average those final scores.
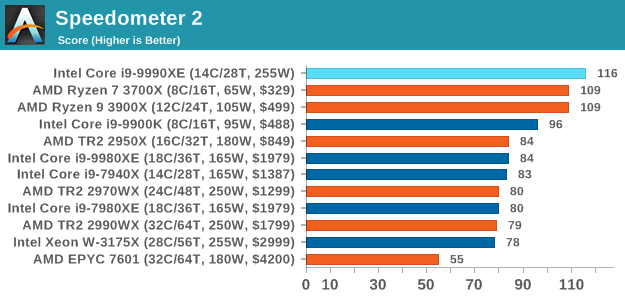
Speedometer 2: JavaScript Frameworks
Our newest web test is Speedometer 2, which is a accrued test over a series of javascript frameworks to do three simple things: built a list, enable each item in the list, and remove the list. All the frameworks implement the same visual cues, but obviously apply them from different coding angles.
Our test goes through the list of frameworks, and produces a final score indicative of ‘rpm’, one of the benchmarks internal metrics. We report this final score.
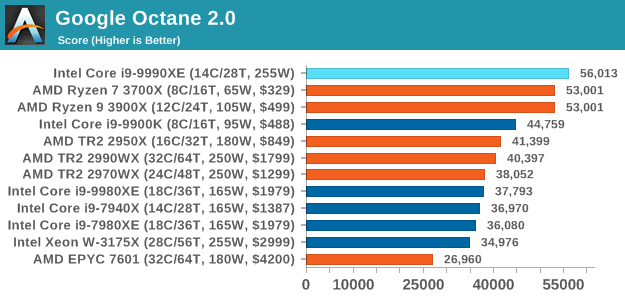
Google Octane 2.0: Core Web Compute
A popular web test for several years, but now no longer being updated, is Octane, developed by Google. Version 2.0 of the test performs the best part of two-dozen compute related tasks, such as regular expressions, cryptography, ray tracing, emulation, and Navier-Stokes physics calculations.
The test gives each sub-test a score and produces a geometric mean of the set as a final result. We run the full benchmark four times, and average the final results.
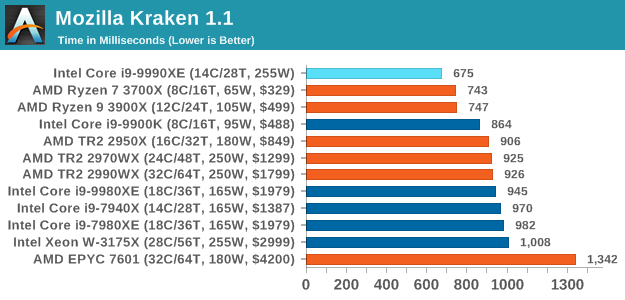
Mozilla Kraken 1.1: Core Web Compute
Even older than Octane is Kraken, this time developed by Mozilla. This is an older test that does similar computational mechanics, such as audio processing or image filtering. Kraken seems to produce a highly variable result depending on the browser version, as it is a test that is keenly optimized for.
The main benchmark runs through each of the sub-tests ten times and produces an average time to completion for each loop, given in milliseconds. We run the full benchmark four times and take an average of the time taken.
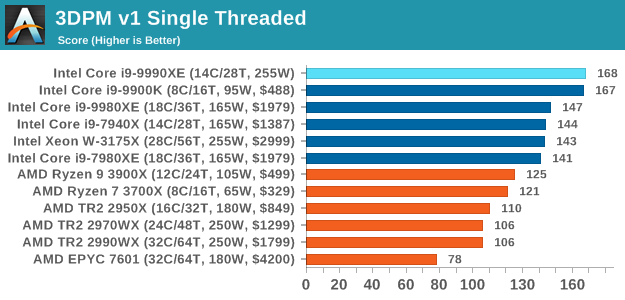
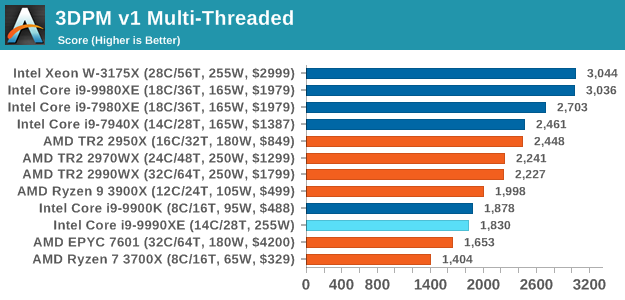
3DPM v1: Naïve Code Variant of 3DPM v2.1
The first legacy test in the suite is the first version of our 3DPM benchmark. This is the ultimate naïve version of the code, as if it was written by scientist with no knowledge of how computer hardware, compilers, or optimization works (which in fact, it was at the start). This represents a large body of scientific simulation out in the wild, where getting the answer is more important than it being fast (getting a result in 4 days is acceptable if it’s correct, rather than sending someone away for a year to learn to code and getting the result in 5 minutes).
In this version, the only real optimization was in the compiler flags (-O2, -fp:fast), compiling it in release mode, and enabling OpenMP in the main compute loops. The loops were not configured for function size, and one of the key slowdowns is false sharing in the cache. It also has long dependency chains based on the random number generation, which leads to relatively poor performance on specific compute microarchitectures.
3DPM v1 can be downloaded with our 3DPM v2 code here: 3DPMv2.1.rar (13.0 MB)
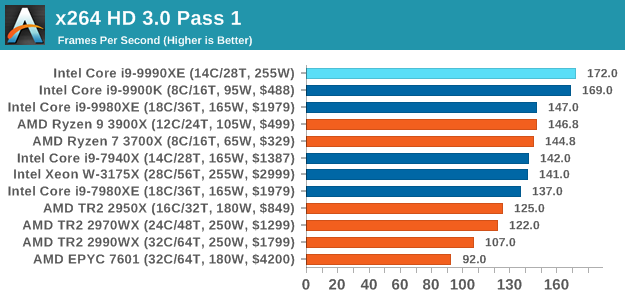
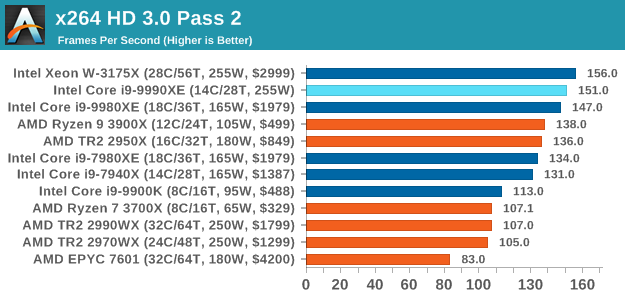
x264 HD 3.0: Older Transcode Test
This transcoding test is super old, and was used by Anand back in the day of Pentium 4 and Athlon II processors. Here a standardized 720p video is transcoded with a two-pass conversion, with the benchmark showing the frames-per-second of each pass. This benchmark is single-threaded, and between some micro-architectures we seem to actually hit an instructions-per-clock wall.








145 Comments
View All Comments
Batmeat - Monday, October 28, 2019 - link
Agreed.This chip is auction only. Expect to pay HUGE DOLLARS for this assuming you even have access to the auctions.
mrvco - Monday, October 28, 2019 - link
But the chip isn't selling for all that much at auction apparently... I was expecting much more than 2849 euros if this thing really is the golden ticket for HFT. From a financial perspective, this isn't worth Intel's time or effort relative to letting top-tier partners and resellers buy up the whole supply of 9990XE's to do the binning on their own. Regardless, it's less expensive than a Super Bowl ad I suppose and probably more effective considering their target audience.Cygni - Monday, October 28, 2019 - link
It is a niche product for a niche market... one that the article talked about at length. "Bragging rights" doesn't come into play when it is a tool for making money.willis936 - Monday, October 28, 2019 - link
It just doesn't make sense. If single threaded performance is king then why do you need 14 cores running at 5 GHz? If multithreaded performance is king then why not go wider? The low latency case doesn't make sense. You could assemble multiple systems focused on single threaded performance for less money than this 14 core auction-only chip costs. When people say it's only for bragging rights, they are not wrong.edzieba - Monday, October 28, 2019 - link
To GREATLY oversimplify HFT loads:you want as many cores as you can get, but those cores must respond as quickly as possible. You're effectively packet-watching: as soon as you see a packet you need to read it, determine if it is to be acted upon, determine how it is to be acted upon, and then respond, and you need to do it faster than everyone else. Everyone else has as close as is possible to the same network latency (e.g. stock exchanges employ huge fibre loops to ensure every endpoint has the same light-speed lag), so if you can run at 5GHz vs. 4GHz of your competitors you can respond to any given packet before they can. It's only a hair faster, but if you're jsut barely first you're still first so your transaction request is the one the stock exchange acts upon and not everyone else's.
You want more cores because each core can run its own worker with its own algorithm (or more workers on the same algorithm to offset by packet arrival). You never want to be operating at a lower frequency than everyone else because it means NOTHING that you have 64 cores if every one of your cores is consistently too slow to beat out everyone else.
You want all those cores on one die because you need to remain consistent in response (i.e. not have one worker working at cross-purposes against another) and inter-socket or worse inter-machine latency will kill you dead in the race to respond.
Processwindow - Monday, October 28, 2019 - link
If high frequency is the ultimate goal and money is not an issue, why staying water.cooling.and not going straight to LN2. LN2 is cheap by wall street standards and it would allow to go higher than 6 GHz for sure. Btw in the great explanation you give regarding the need of high frequency CPU in HFT , I see nowhere optimization of the network card whatever it is and of its firmware.JoeyJoJo123 - Monday, October 28, 2019 - link
>If high frequency is the ultimate goal and money is not an issue, why staying water.cooling.and not going straight to LN2. LN2 is cheap by wall street standards...These kinds of machines are used by automated systems doing stock trading thousands of times per second. (It's why being a day-trader is absolutely worthless because automated software can do your task thousands of times faster and more accurately given historical trends.) LN2 isn't "expensive" but this is a machine that needs to have the highest single-threaded performance possible, with as many cores as possible, yet still run 24/7 to keep up with the market. The system can never sleep, as we're talking potentially hundreds of thousands of dollars lost per few seconds of downtime. And that's why LN2 isn't used--It evaporates and while LN2 cooled systems can overclock higher than non-LN2 systems, it's at such a bleeding edge of instability that it in-and-of-itself will cost the stock-trader money whenever it inevitably gets a cold-bug and needs to reboot or if the thermal transfer between the pot and the IHS cracked at ultra-low temperatures and the temps are starting to rise, or if there's condensation around ICs, or if the power delivery system is starting to fail because it's been ran over-spec for the last 50 days, etc.
Processwindow - Monday, October 28, 2019 - link
What are you talking about? MRI tools in every big hospital in the world is working 24/7 with LN2 . Every semiconductor fab in the world use LN2 in manufacturing environnement. LN2 is not an exotic material.So you tell me you can spend 10s millions of dollar to gain a few ns in HFT but you don't want to go beyond water cooling to gain a few GHz on your CPU Something is wrong here.
Opencg - Monday, October 28, 2019 - link
You clearly don't understand the difference between those machines and these. You just don't have a mind for it. Do not try to argue. Don't even try to think about it man. You are useless.The difference is that those machines were designed with LN2 cooling in mind for sustained operation. Computers were not. Having a skilled overclocker precisely control a benchmark for a (relatively) short time is nothing like having a machine designed to automatically consistently do it over long periods. Developing a computer that could do his would not only be VERY expensive but there is also a risk of it simply not working consistently enough in the end anyway and you are back to square one.
Processwindow - Monday, October 28, 2019 - link
You are the one clearly not understanding the situation. It seems financial companies involved in HFT can spend 10s millions us$ to gain a few ns . But they wouldn't want to spend those same dollars to get 1 or 2 more GHz with special custom LN2 or whatever other ultra low temp cooling system? Something doesn't add up here.