Original Link: https://www.anandtech.com/show/8457/mips-strikes-back-64bit-warrior-i6400-architecture-arrives
MIPS Strikes Back: 64-bit Warrior I6400 Arrives
by Stephen Barrett on September 2, 2014 10:00 AM ESTIntroduction
One of ARM’s most tangible business advantages is its offer of both CPUs and GPUs to SoC designers. Anyone with experience in business to business relationships knows just how complex forming and maintaining a mutually beneficial collaboration can be. Setting up contracts, forming rapport, defining goals, and even just understanding documentation and technical content formatting all takes time. Unless there is significant benefit to investing in two different relationships and technologies, it is simpler (read: cheaper) to single source contributing components of a design. There are down sides of single sourcing (see Boeing 787 battery fiasco), but depending on a business’ capacity for risk, the savings are undeniable. Especially when ARM undoubtedly offers bundle pricing promotions.
When Imagination Technologies acquired MIPS Technologies in 2012 for $100 million, their goal was very clear – attack ARM. Imagination’s GPU business was already wildly successful, with design wins in a bevy of high end mobile devices including those from Samsung and Apple. Adding the CPU cores from MIPS, with their decades of history designing and licensing IP, strategically positioned Imagination opposite ARM’s licensing business. Imagination’s executives have also stated they are prepared to offer aggressive IP bundling discounts.
Looking at Imagination’s product, press, demos, and interviews, it appears they are not (yet?) positioning MIPS cores to combat ARM cores at the high end of the market. Rather, they appear focused on being a viable alternative to ARM in multi-threaded and low power workloads. In fact, the vast majority of MIPS cores are currently used in network infrastructure where threading and power efficiency are paramount.
Today MIPS is announcing a major launch: the Warrior I6400 core. Based on the 64-bit MIPS64 instruction set (release 6), the Warrior I6400 core is the middle-class CPU core in a family of three, each targeting a different point in the power/performance curve. Imagination is releasing the I6400 core last, which is at the middle of the pack balancing performance with power. Imagination has already released their high-end P56xx series and low-end M51xx series.
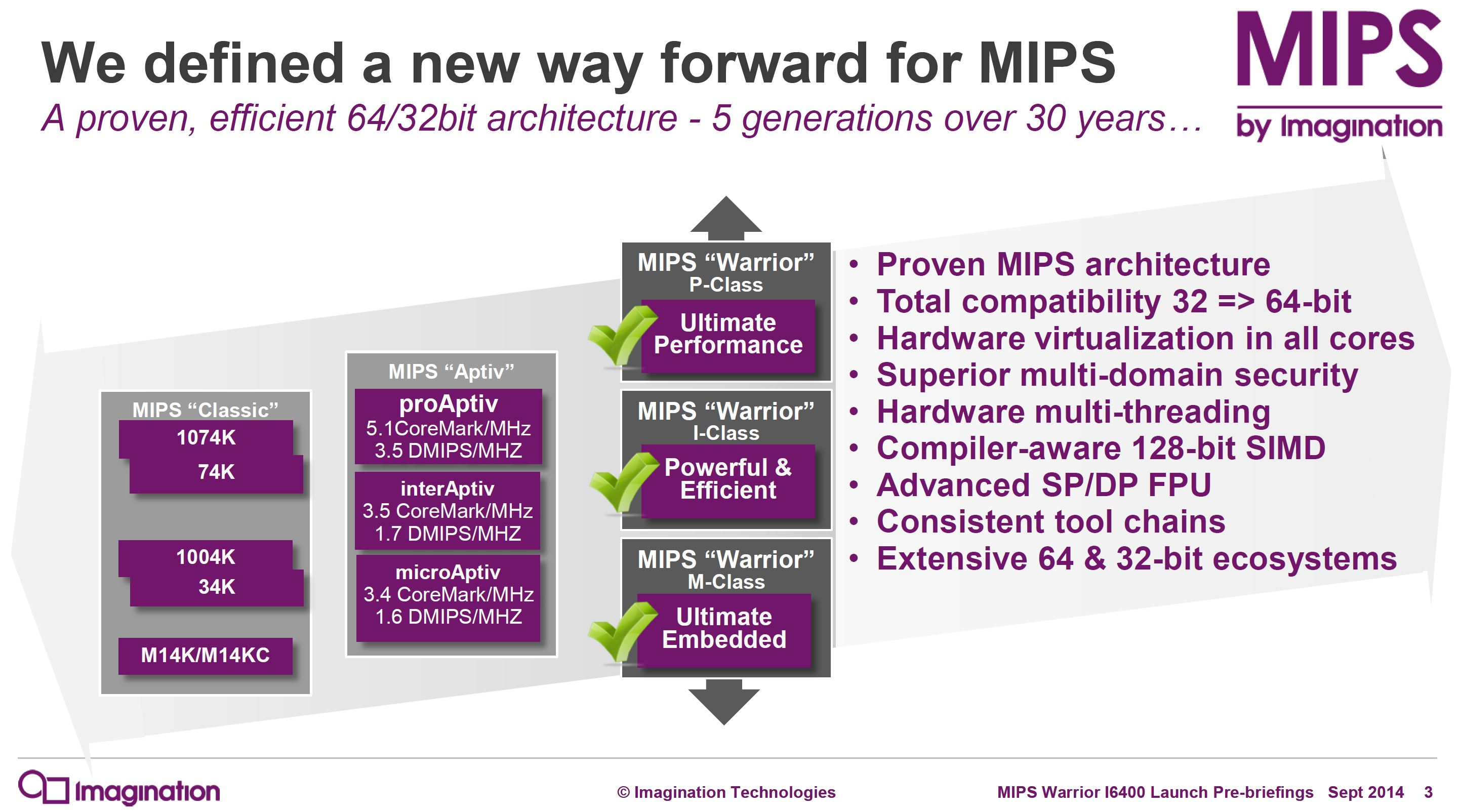
The most analogous ARM core to the I6400 appears to be the ARM Cortex-A53, but I6400 has some interesting features we haven’t seen in this market before and MIPS estimates it will deliver higher performance. I’ve produced a table here to help put performance in context. Note that only A57, A53, P5600, and I6400 are 64-bit processors.
| MIPS and ARM High End IP Cores in Order of Performance | ||
| MIPS |
Manufacturer Estimated DMIPS/MHz/core |
ARM |
| 5.0 | Cortex-A57 | |
| 4.0 |
Cortex-A17 Cortex-A15 |
|
| P5600 | 3.5 | |
| I6400 | 3.0 | |
| 2.5 | Cortex-A9 | |
| 2.3 | Cortex-A53 | |
| 1.9 | Cortex-A7 | |
Keep in mind that these processors use different instruction sets (ISAs) so DMIPS are not directly comparable. However, as they are both RISC processors, the DMIPS should hopefully be roughly comparable. I would like to use directly comparable CoreMark scores but only MIPS provides CoreMark numbers for their processors.
While no one can accurately predict if Imagination will grab additional market share away from ARM, we can educate ourselves on this alternative before it potentially arrives in our hands and homes. And besides, competition is always a good thing.
MIPS Instruction Set: 64-bit Release 6
Computer processors accomplish tasks by following instructions. The processor, however, only understands instructions in a specific "language". The language of a processor is called its Instruction Set Architecture (ISA). The code sent to a processor must be in that ISA to be understood. It's similar to what would happen if someone proceeded to give me instructions in Portuguese: I unfortunately would have no idea how to execute them. When a program or operating system is authored and compiled, the compiler is parameterized to generate the 1s and 0s of binary code using a specific ISA.
In general, there are two types of ISAs. Complex Instruction Set Computing (CISC) and Reduced Instruction Set Computing (RISC). The difference between them being of course their relative complexity. In general, a RISC ISA contains significantly fewer instructions that are far simpler than a CISC ISA.
Despite its increased complexity, CISC actually predates RISC and was only named retroactively. CISC ISAs were a necessity when low level code (assembly) was often authored by hand, and compilation was crippled by dramatically less powerful compilers than those available today. Having higher level instructions in the ISA, such as looping, allowed simple compilers to extract sufficient performance and human assembly authors to write programs. The most popular CISC ISA ever written is the x86 ISA used in Intel, AMD, and VIA processors. Interestingly, these processors now use dedicated decoding hardware to actually translate CISC instructions into RISC instructions that are executed internally.
RISC ISAs push much of the instruction complexity into the code compiler. Instead of using instruction decode circuits inside the CPU core to translate complex instructions into simple ones, RISC processors operate directly on the simple instructions provided by the compiler. This benefit is somewhat offset as often code compiled for RISC ISAs is larger; it may take multiple RISC instructions for the equivalent CISC instruction. This holds true in computer science theory, as one of the first things taught is there is often a tradeoff between storage and efficiency. If there is a desire for increased efficiency, precompute items ahead of time and then store them. If you need to save storage (or reduce the memory footprint), compute items on-the-fly.
The most popular RISC ISA ever written is the ARM ISA. The MIPS ISA, like ARM, is RISC. It has been revised several times since its inception in 1985. The first five releases are named according to roman numerals I through V, and each was a super set of the last. In 1999, MIPS announced a large revision of the ISA which deprecated the old hierarchical I through V scheme and instead focused on two ISAs: MIPS32 and MIPS64.
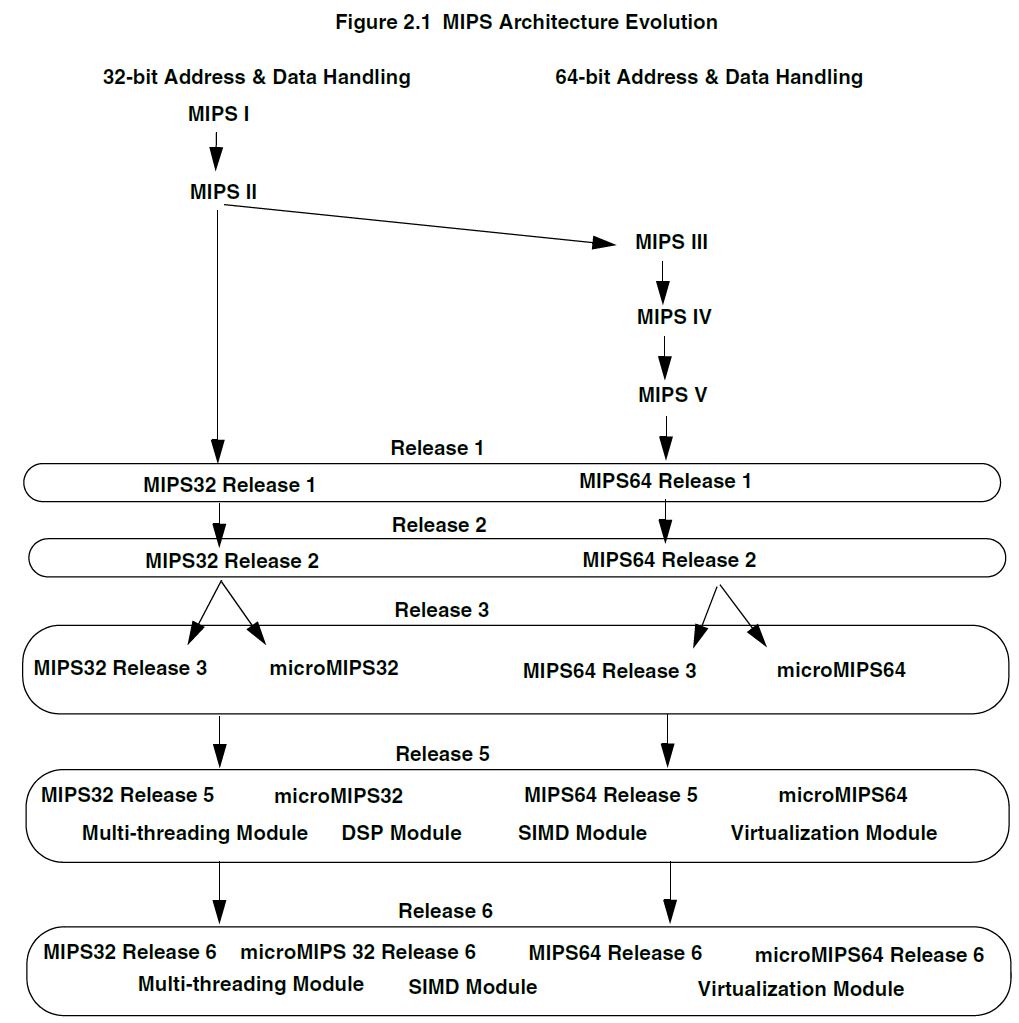
Release 6 occurred in 2014 and the I6400 is the first CPU utilizing the new ISA. I won’t go through all the changes in the ISA, but the most significant is a culling of the instructions. Significant work was done to simplify the ISA by removing infrequently used instructions, in particular those that overlapped with Imagination’s PowerVR GPUs. Additional instructions were also added specifically targeting today’s applications like web browsers. The fruit of these instructions has recently been seen as Google Chrome’s V8 rendering engine added experimental support for MIPS64 release 6 in July.
In the MIPS programmer’s guide the release 6 ISA is actually referred to as MIPS3264 release 6. This naming is not by accident, as MIPS64 ISA is actually a direct superset of the MIPS32 ISA. In contrast to AMD64 (x86-64), there are no "operating modes" that dictate the bitness of instructions executed on the CPU but rather an entirely new set of instructions specifically for 64-bit. Registers inside the CPU are all 64bit, and when a 32-bit instruction executes, results saved in registers are sign-extended to the entire 64-bits of space. This means there is no mode switching, and 32-bit and 64-bit applications can coexist and even be executed using the same hardware resources like registers (more on this later).
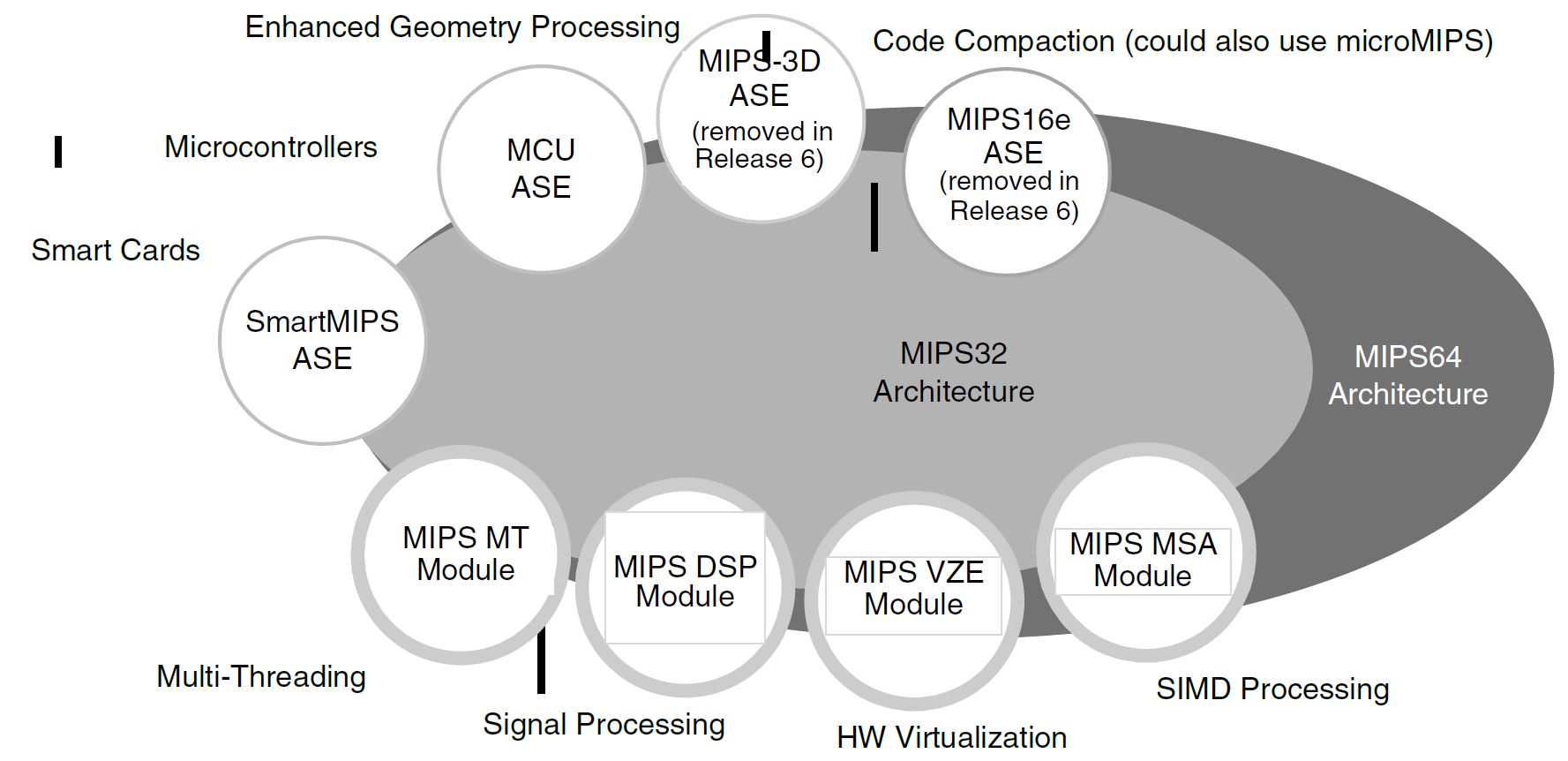
The MIPS ISA contains several optional instructions called Application Specific Extensions. These rely on optional portions of the CPU core that a licensee may or may not implement. Additionally, a MIPS CPU has optional modules that can enhance performance when paired with certain instructions.
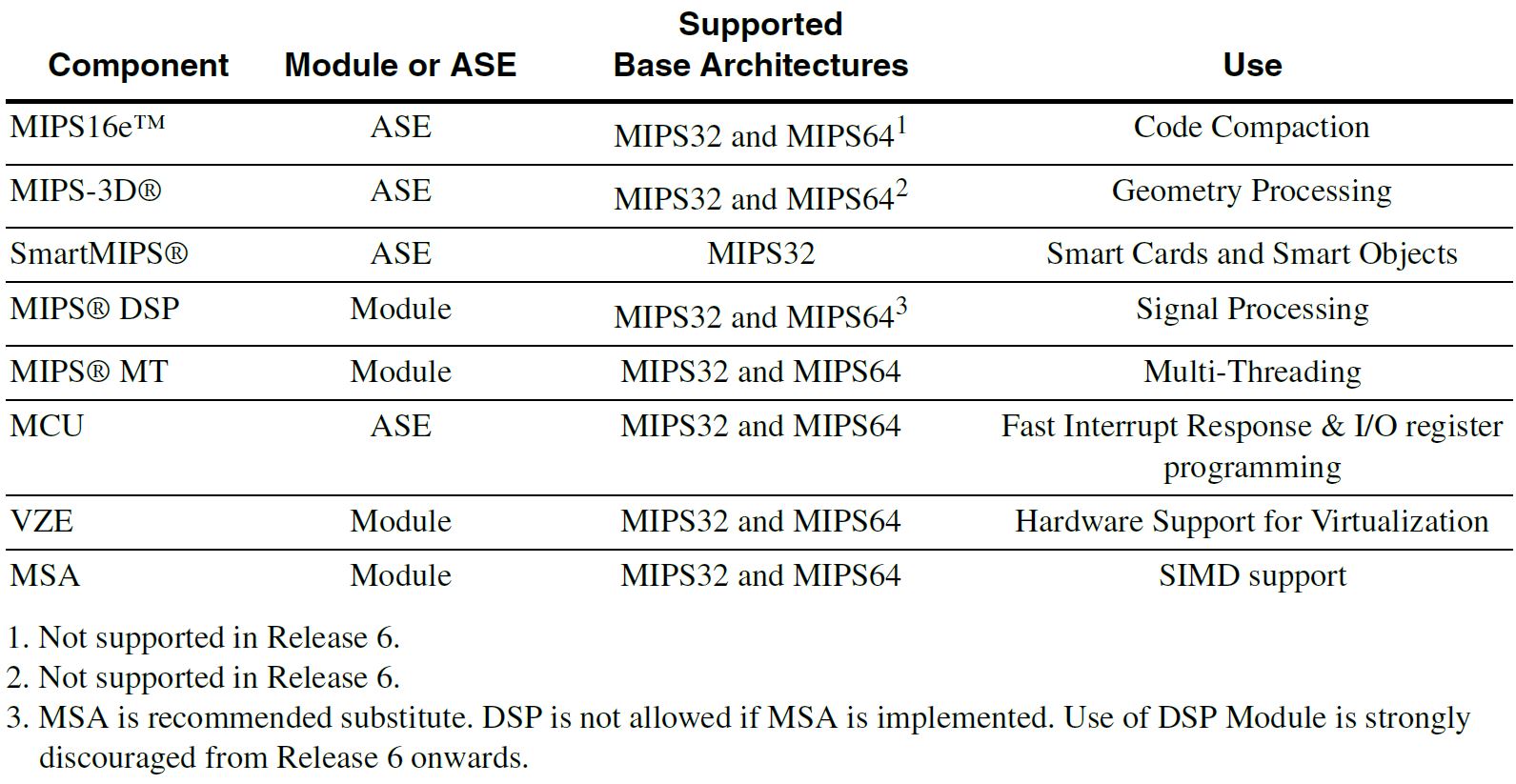
Release 6 drops the legacy MIPS16e ASE as well as the redundant 3D ASE now that Imagination offers GPUs alongside MIPS CPUs.
MIPS CPUs in Mobile Devices
While MIPS CPUs are quite popular in networking equipment and many other embedded industries, consumers will likely only experience one firsthand when it's integrated into an Android handset. Since Android 4.0, Google has supported three ISAs: x86, ARM, and MIPS. Several devices have shipped running MIPS processors, most notably the low-cost Novo 7 tablet. MIPS devices will continue to be low cost alternative devices for now, but low cost devices have the largest volume. The volume should eventually help MIPS push app developers to address their #1 problem: compatibility.
Android applications are either written in Java, then compiled on the device to the specific required ISA before running (a processes called JIT compilation), or written in the Android Native Development Kit (NDK) to target a specific ISA. Apps written in Java can therefore run on any ISA that Android itself supports, including MIPS. Apps written with the NDK (many of which exist, especially games) cannot run on anything but the specific ISA they were written for. The Android NDK does allows packaging multiple ISA specific binaries into a single app, but with the vast majority of Android devices using ARM processors and therefore the ARM ISA, a multiple NDK Android app is simply uncommon.
What does this mean for an end user? There are many Android apps that simply won’t run if you have a MIPS processor in your device. Intel has the same NDK compatibility problem, but with their considerably larger engineering resources, Intel implemented a layer that translates ARM ISA applications to the Intel x86 ISA (albeit at a performance penalty). Until MIPS implements the same or ships enough volume to convince Android app developers to put in some extra work, a MIPS Android device will unfortunately be a second class experience.
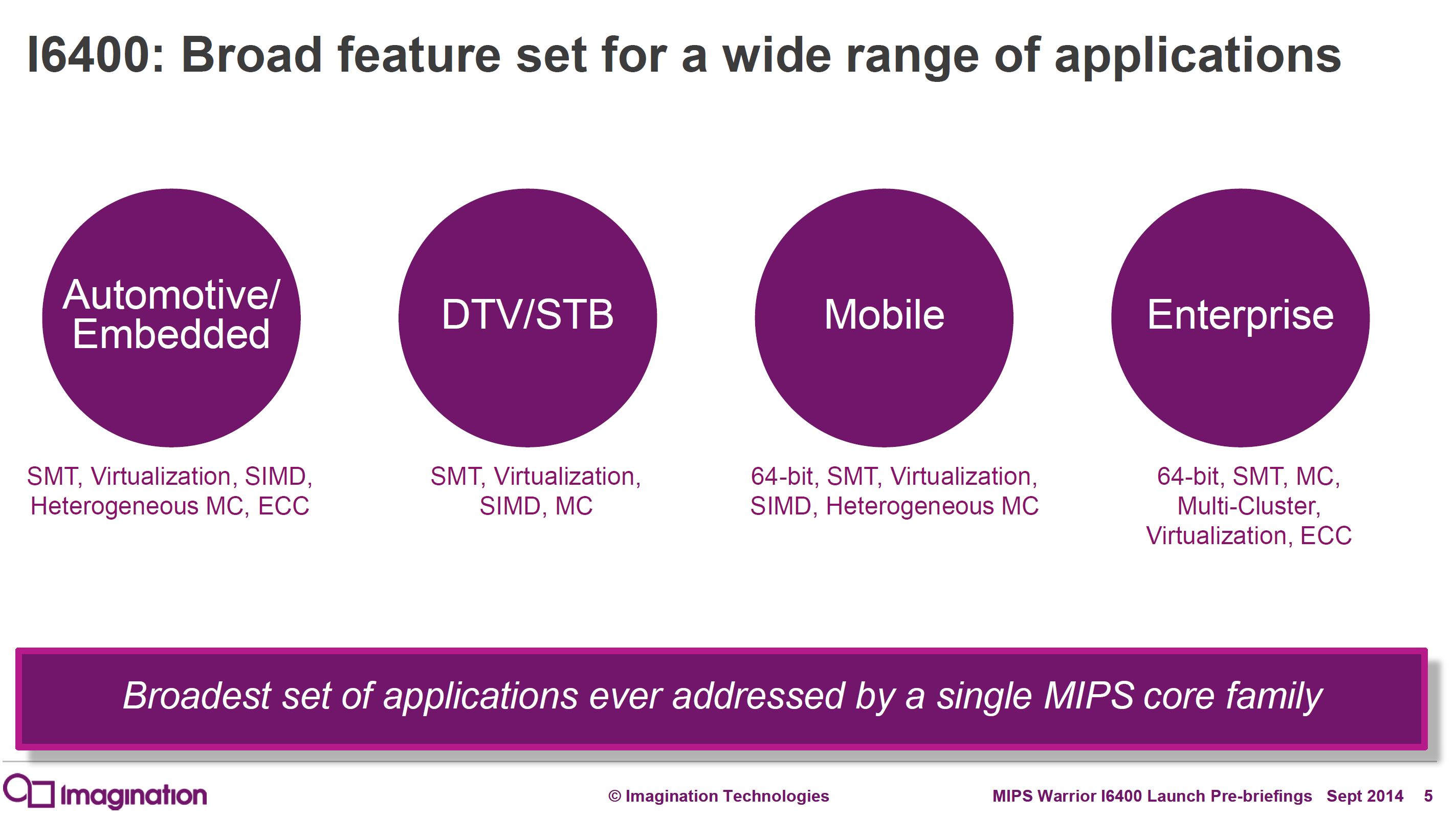

Despite some existing Android app compatibility woes, the MIPS I6400 CPU contains some interesting technology designed to address many more markets than handsets. In fact, Android usage of MIPS processors is really a minor part of the MIPS business. A few slides from the MIPS announcement indicate just how many other markets they are targeting.
The MIPS I6400 CPU
Like the Cortex-A53, the I6400 is an in-order, dual-issue design. Each processor supports IEEE 754-2008 floating point operations, 128-bit SIMD instructions, and hardware virtualization. ARM has previously stated that Cortex-A9 is roughly 2.5 mm2 of area with a 40 nm process, and Cortex-A53 is 40% smaller at the same process, placing it at roughly 1.5 mm2 of area. At 28nm, we can estimate a Cortex-A53 is about 1mm2. Comparatively, MIPS states the I6400 is 1mm2 on the TSMC 28nm HPM process in "worst-case scenarios". Therefore the designs are quite comparable.

Differences between the Cortex-A53 and I6400 start with a 9 stage pipeline in the I6400 vs 8 stages with the A53, theoretically allowing the I6400 to clock higher. However the I6400 is 9 stages for all operations, whereas the A53 is 8 stages for integer but 10 for NEON/Floating Point operations.
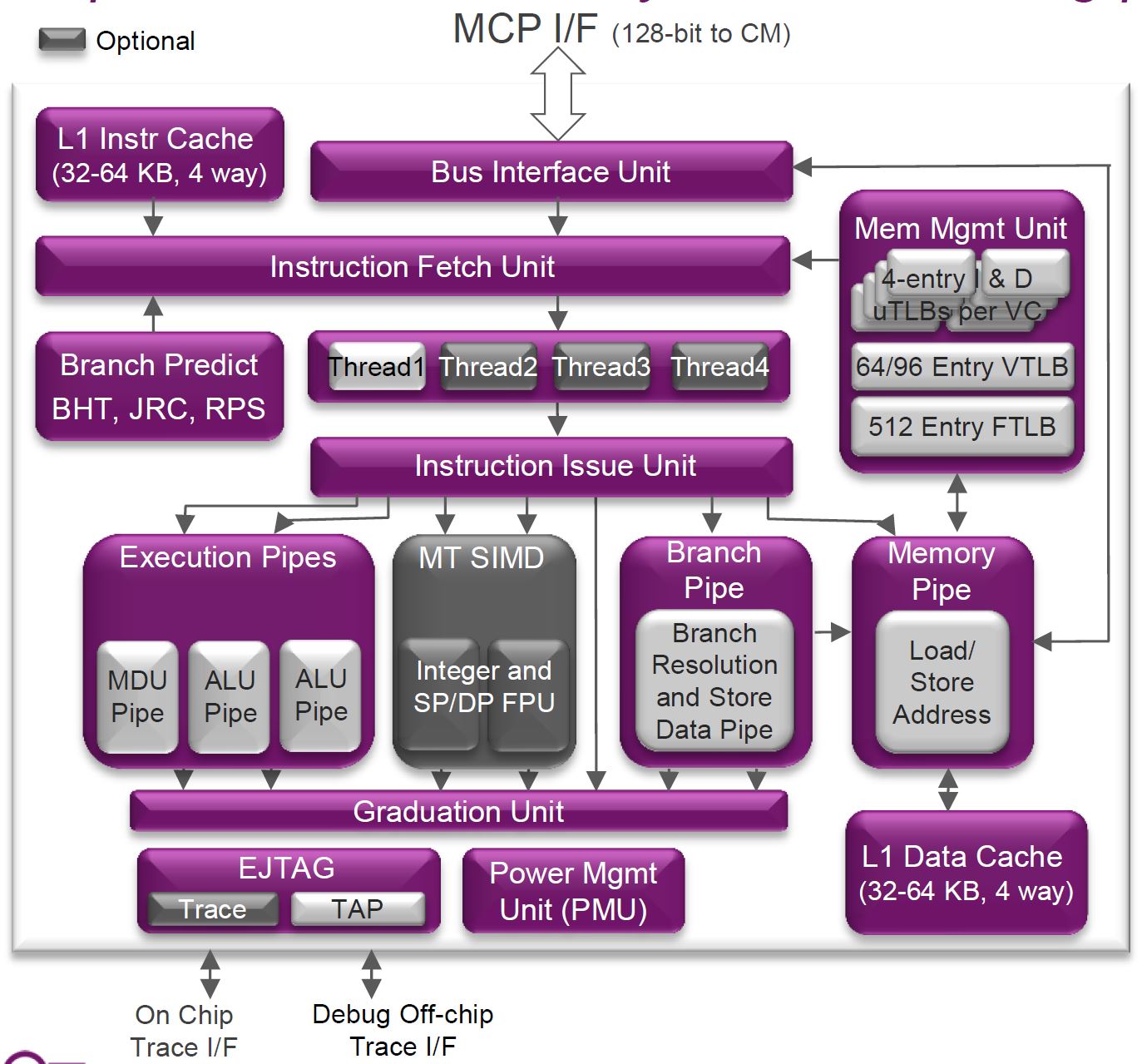
If you look closely at the block diagram you can see one of the I6400’s interesting tricks: Simultaneous Multi-Threading (SMT). Avid readers of AnandTech should recognize this technology immediately. It has been utilized by Intel since the venerable Pentium 4, over a decade ago in 2002, under the trademarked name Hyper-Threading. While the Core Duo and Core 2 lines dropped support for Hyper-Threading, the Nehalem (Core i7) and later processors have continued its use. IBM's POWER cores also support SMT (up to 4-way SMT with POWER7 and 8-way SMT with POWER8).
Strangely, we have not seen anyone else (e.g. ARM or AMD) implement this same technology until now. AMD has a partial implementation in its Bulldozer architecture, with each "module" in their current CPUs/APUs providing two full integer cores with some shared elements. AMD contends that their partial SMT implementation is actually better for some workloads, but that's a different discussion. Regardless, SMT support it is new to the small-core space.
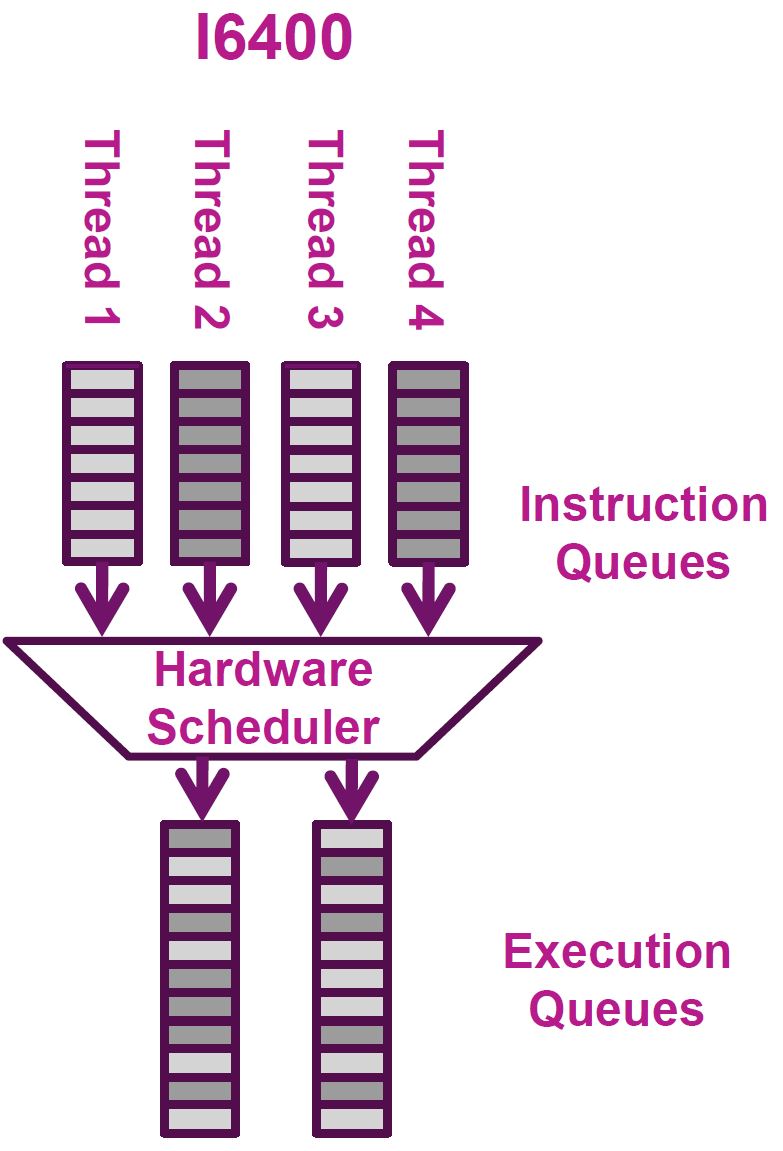
An SoC designer licensing an I6400 core can decide how many threads of SMT they want to implement into the core, from 1 to 4. The physical core then advertises itself to the operating system as 1 to 4 logical cores, thus allowing the OS to send up to four threads of instructions to execute at any given time. The hardware’s execution scheduler can then, per cycle, dynamically switch between threads depending on which hardware resources are available. For example, if the integer ALUs are tied up with threads 1-3 but thread 4 only needs floating point resources, the scheduler can schedule thread 4 to the FP units instead of waiting around.
Imagination claims their MIPS core featuring SMT only increases 10% in size but increases an incredible 30% to 50% in performance. A 3x to 5x size to performance ratio for any given feature is quite hard to come by. If Imagination’s claims are correct, it’s a wonder this feature is optional. Certain applications greatly suffer from SMT, namely real-time applications that depend on determinism, but like Intel Hyper-Threading, I would hope there is a simple software setting to disable this feature when it is not desired. Imagination specifically calls out networking applications (which are very throughput focused) as greatly benefiting from SMT, which is the optional MIPS MT extension.
Even though the core is in-order, the I6400 performs superscalar execution for a given thread. Since it is dual dispatch, two instructions from a single thread can be executed in parallel. I would imagine the superscalar execution is limited to the next two instructions within a thread (as there is no reorder buffer); otherwise the entire core wouldn’t be listed as in-order.
| Mid-Class CPU Core Comparison | ||||||
| MIPS I6400 | ARM Cortex-A53 | |||||
| CPU Codename | Warrior | Apollo | ||||
| ISA | MIPS3264 Release 6 | ARMv8-A (32/64-bit) | ||||
| Cores in an SMP Cluster | 1-6 | 1-4 | ||||
| Thread Width | 1-4 | 1 | ||||
| Issue Width | 2 micro-ops | 2 micro-ops | ||||
| Reorder Buffer Size | None: In-Order | None: In-Order | ||||
| Pipeline Depth (stages) | 9 | 8 (Int) 10 (FP) | ||||
| Integer ALUs | 2 | 2 | ||||
| Load/Store Units | 1 (2 with bonding) | 1 | ||||
| Load Latency | 3 cycles | 3 cycles | ||||
| Branch Units | 1 | 1 | ||||
| FP/NEON ALUs | 2 | 2 | ||||
| Coherency | Directory | Snoop + Filter | ||||
| L1 Cache | 32 or 64KB I$ + 32 or 64KB D$ | 8 to 64KB I$ + 8 to 64KB D$ | ||||
| L2 Cache | 0.5 to 8MB | 0.5 to 2MB | ||||
Another trick the I6400 employs is called instruction bonding or load/store bonding, which probably ties in with the previously mentioned hardware scheduler. If two load or store instructions arrive at the scheduler with adjacent addresses, the I6400 can "bond" them together into a single instruction executed by the load/store unit. Two 32-bit integer accesses will be bonded into a single 64-bit integer access, two 64-bit integer accesses bond into a single 128-bit integer access, and two 64-bit floating point accesses bond into a single 128-bit FP access.
Applications often perform memcopies that move relatively large amounts of memory from point A to point B, resulting in a long list of load/store instructions. This hardware scheduler feature can halve the time required to fulfill a memcopy request and is completely transparent to software. MIPS states this feature is a natural expansion of their load/store unit, as their bus widths are already 128-bits to support their SIMD unit. Doubling the efficiency of the I6400's single load/store unit (in certain cases) helps save area and power compared to duplicating the unit entirely.
Directory Based Coherency
One of the largest problems a multicore processor needs to solve is coherency. Multiple PhDs have been earned on this topic alone. The core of the problem (pun intended) is that multiple execution resources (CPU or GPU cores) exist each with their own L1 data cache. If Core1 writes to address 0xABC0FF, its L1 data cache is immediately updated. However, what if there is another core present that also has the data at address 0xABC0FF cached? Its cached data is now invalid and, if used, results in computational inconsistency and a potentially critical application errors.
There are multiple techniques to deal with this problem. The most common is called snooping. Each core in a multicore system monitors the L1 cache lines of every other core. If a write is observed to an address that is locally cached, that cache line is immediately invalidated. When an invalidated cache line is accessed, the invalid data is not returned but rather a longer trip out to the coherent L2 cache is made. Since all the L1 caches update whenever any L1 cache is written to, this is the most performant coherency implementation. However, it is quite complex. If eight cores are designed with coherent L1 caches, each core must connect to seven other cores, causing an explosion of complexity.
One way modern designs deal with increasing snoop complexity is by using a "snoop bus". Instead of connecting all cores L1 caches to each other, all cores are connected all to a shared bus. When a core writes to an L1 cache location, it broadcasts the address written to all other cores on the snoop bus. Other cores then invalidate that address if it is present in their L1 cache. This helps with wiring inside the chip, but snoop traffic is still increasing with added cores. ARM's A53 goes a step further and has a Snoop Control Unit (SCU) that sits on the bus and filters out snoop traffic based upon which caches have which addresses.
The I6400 uses the other common technique, directory based coherency. The L2 cache in the I6400 maintains a listing of all the data being duplicated in attached CPU cores. When an address is changed, the directory is always notified. The directory can then update the attached CPU cores that have duplicated that data. In the worst-case scenario this is both higher latency (informing the directory of a write takes time) and can result in increased bus traffic because every core could have cached a particular address. However, it’s not likely that every single core would have cached the same data that gets overwritten. Either way, it is significantly simpler to implement as it is a single point to point connection between L1 and L2 per core rather than a web of connections between L1s. This is likely a contributing factor in why the I6400 can be used in SMP clusters of 6, whereas the A53 is limited to SMP clusters of 4.

Finally, the I6400 includes fine grained power consumption optimizations branded as “PowerGearing” by MIPS. The processor can disable clocks (clock gating) to individual CPU cores, caches, and subsystems (such as SIMD blocks). Each CPU core can individually sleep and be controlled by OS Dynamic Voltage and Frequency Scaling (DVFS), which is essential to Android/Linux processor power management.
Final Words
When it comes to processors, enthusiasts and laymen alike can identify the three largest players: Intel, AMD and ARM. Those names are also not mutually exclusive: AMD utilizes ARM designs for consumer security coprocessors and in its Opteron A1100 server processor. There are other processors out there (e.g. IBM's POWER CPUs), but they're generally not as well known. That's also the case with MIPS.
Not everyone knows the name MIPS, but Imagination hopes to change that by offering a viable alternative to the embedded market dominated by ARM. MIPS already has a large presence in networking and embedded devices. Introducing the I6400 keeps MIPS relevant and places additional pressure on ARM. According to the provided numbers (admittedly from MIPS) and feature descriptions, the I6400 appears to compete with and even surpass the highly anticipated ARM Cortex-A53. Imagination projects general availability of the I6400 to SoC designers by December 2014. We can estimate end-user availability at least 6 to 9 months after that.
Consumers will most likely directly experience the MIPS I6400 CPU in low cost Android tablets and handsets. Due to Android's Java heritage, some applications will work out-of-the-box. Other applications using the Android Native Development Kit (NDK) targeting Intel or ARM ISAs will unfortunately be incompatible. Until MIPS achieves enough volume to convince application developers to code to the MIPS3264 ISA or stick with Java, MIPS Android devices will be second class citizens. This is something to keep in mind if you're purchasing a phone for yourself or a tech savvy friend. Of course, basic operating system features like email, phone, text, web browsing, and chatting should all work fine.
Intel has enjoyed dominance of its performance leading processors in non-handset settings for the better part of a decade. ARMs embedded low power heritage has emerged as Intel’s biggest threat as mobile devices have exploded and now dominate the computing landscape. As Intel and ARM continue to battle for the high end embedded market, Imagination and MIPS hope to erode away ARM’s mid-range and low-end core competency. As a consumer, we can lean back and enjoy the competition that will force each company to work harder each and every year.
The I6400’s revised MIPS3264 Release 6 ISA, instruction bonding, and SMT execution pipeline bring a refreshing set of new innovations to the small-core market. In our A53 coverage we noted ARM was pushing in-order CPU performance about as far as it could possibly go. I’m always happy to see we might have been wrong.






