The Apple A15 SoC Performance Review: Faster & More Efficient
by Andrei Frumusanu on October 4, 2021 9:30 AM EST- Posted in
- Mobile
- Apple
- Smartphones
- Apple A15

A few weeks ago, we’ve seen Apple announce their newest iPhone 13 series devices, a set of phones being powered by the newest Apple A15 SoC. Today, in advance of the full device review which we’ll cover in the near future, we’re taking a closer look at the new generation chipset, looking at what exactly Apple has changed in the new silicon, and whether it lives up to the hype.
This year’s announcement of the A15 was a bit odder on Apple’s PR side of things, notably because the company generally avoided making any generational comparisons between the new design to Apple’s own A14. Particularly notable was the fact that Apple preferred to describe the SoC in context of the competition; while that’s not unusual on the Mac side of things, it was something that this year stood out more than usual for the iPhone announcement.

The few concrete factoids about the A15 were that Apple is using new designs for their CPUs, a faster Neural engine, a new 4- or 5-core GPU depending on the iPhone variant, and a whole new display pipeline and media hardware block for video encoding and decoding, alongside new ISP improvements for camera quality advancements.
On the CPU side of things, improvements were very vague in that Apple quoted to be 50% faster than the competition, and the GPU performance metrics were also made in such a manner, describing the 4-core GPU A15 being +30% faster than the competition, and the 5-core variant being +50% faster. We’ve put the SoC through its initial paces, and in today’s article we’ll be focusing on the exact performance and efficiency metrics of the new chip.
Frequency Boosts; 3.24GHz Performance & 2.0GHz Efficiency Cores
Starting off with the CPU side of things, the new A15 is said to feature two new CPU microarchitectures, both for the performance cores as well as the efficiency cores. The first few reports about the performance of the new cores were focused around the frequencies, which we can now confirm in our measurements:
| Maximum Frequency vs Loaded Threads Per-Core Maximum MHz |
||||||
| Apple A15 | 1 | 2 | 3 | 4 | ||
| Performance 1 | 3240 | 3180 | ||||
| Performance 2 | 3180 | |||||
| Efficiency 1 | 2016 | 2016 | 2016 | 2016 | ||
| Efficiency 2 | 2016 | 2016 | 2016 | |||
| Efficiency 3 | 2016 | 2016 | ||||
| Efficiency 4 | 2016 | |||||
| Maximum Frequency vs Loaded Threads Per-Core Maximum MHz |
||||||
| Apple A14 | 1 | 2 | 3 | 4 | ||
| Performance 1 | 2998 | 2890 | ||||
| Performance 2 | 2890 | |||||
| Efficiency 1 | 1823 | 1823 | 1823 | 1823 | ||
| Efficiency 2 | 1823 | 1823 | 1823 | |||
| Efficiency 3 | 1823 | 1823 | ||||
| Efficiency 4 | 1823 | |||||
Compared to the A14, the new A15 increases the peak single-core frequency of the two-performance core cluster by 8%, now reaching up to 3240MHz compared to the 2998MHz of the previous generation. When both performance cores are active, their operating frequency actually goes up by 10%, both now running at an aggressive 3180MHz compared to the previous generation’s 2890MHz.
In general, Apple’s frequency increases here are quite aggressive given the fact that it’s quite hard to push this performance aspect of a design, especially when we’re not expecting major performance gains on the part of the new process node. The A15 should be made on an N5P node variant from TSMC, although neither company really discloses the exact details of the design. TSMC claims a +5% frequency increase over N5, so for Apple to have gone further beyond this would have indicated an increase in power consumption, something to keep in mind of when we dive deeper into the power characteristics of the CPUs.
The E-cores of the A15 are now able to clock up to 2016MHz, a 10.5% increase over the A14’s cores. The frequency here is independent of the performance cores, as in the number of threads in the cluster doesn’t affect the other cluster, or vice-versa. Apple has done some more interesting changes to the little cores this generation, which we’ll come to in a bit.
Giant Caches: Performance CPU L2 to 12MB, SLC to Massive 32MB
One more straightforward technical detail Apple revealed during its launch was that the A15 now features double the system cache compared to the A14. Two years ago we had detailed the A13’s new SLC which had grown from 8MB in the A12 to 16MB, a size that was also kept constant in the A14 generation. Apple claiming they’ve doubled this would consequently mean it’s 32MB now in the A15.
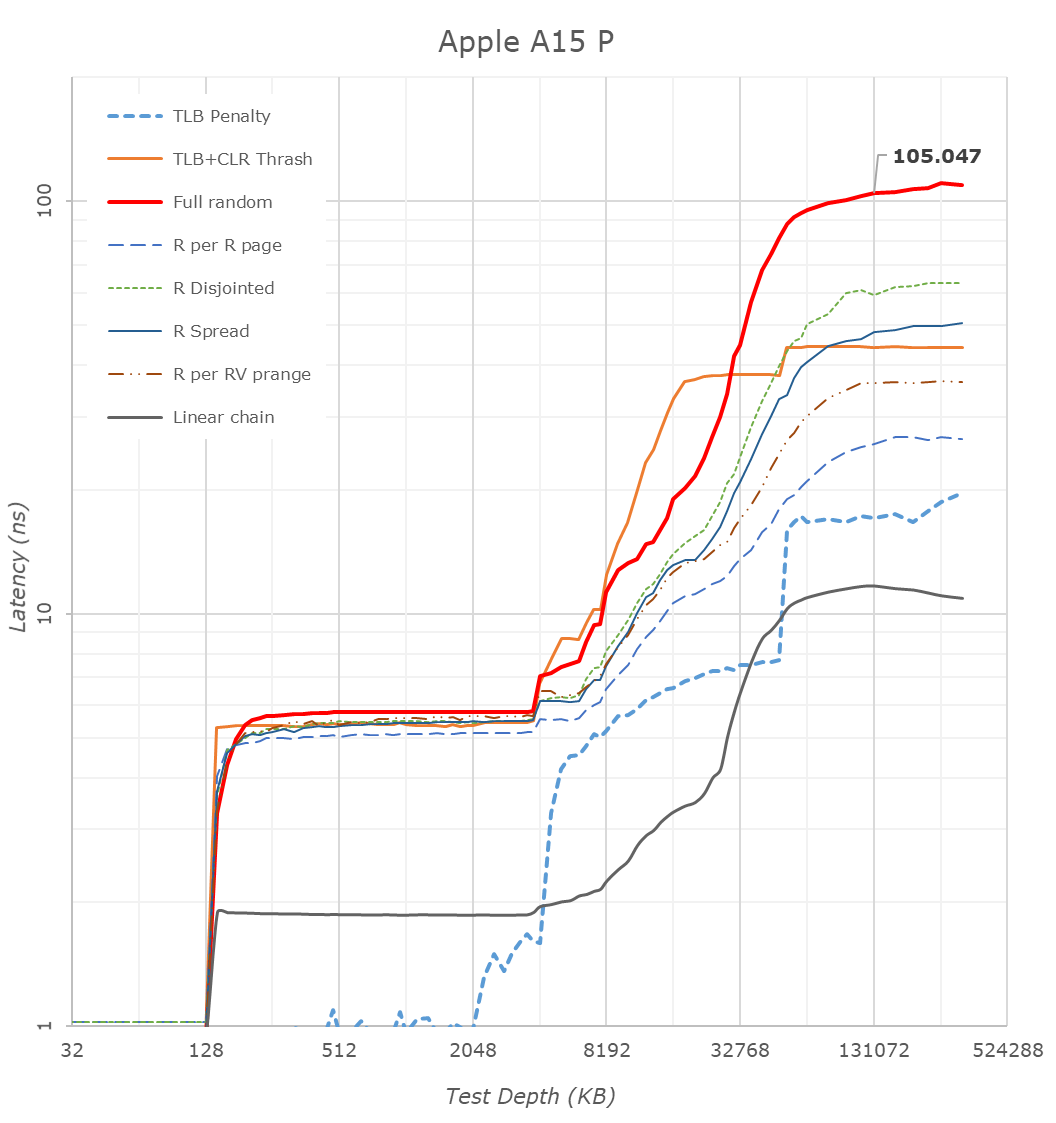
Looking at our latency tests on the new A15, we can indeed now confirm that the SLC has now doubled up to 32MB, further pushing the memory depth to reach DRAM. Apple’s SLC is likely to be a key factor in the power efficiency of the chip, being able to keep memory accesses on the same silicon rather than going out to slower, and more power inefficient DRAM. We’ve seen these types of last-level caches being employed by more SoC vendors, but at 32MB, the new A15 dwarfs the competition’s implementations, such as the 3MB SLC on the Snapdragon 888 or the estimated 6-8MB SLC on the Exynos 2100.
What Apple didn’t divulge, is also changes to the L2 cache of the performance cores, which has now grown by 50% from 8MB to 12MB. This was actually the same L2 size as on the Apple M1, only this time around it’s serving only two performance cores rather than four. The access latency appears to have risen from 16 cycles on the A14 to 18 cycles on the A15.
A 12MB L2 is again humongous, over double compared to the combined L3+L2 (4+1+3x0.5 = 6.5MB) of other designs such as the Snapdragon 888. It very much appears Apple has invested a lot of SRAM into this year’s SoC generation.
The efficiency cores this year don’t seem to have changed their cache sizes, remaining at 64KB L1D’s and 4MB shared L2’s, however we see Apple has increased the L2 TLB to 2048 entries, now covering up to 32MB, likely to facilitate better SLC access latencies. Interestingly, Apple this year now allows the efficiency cores to have faster DRAM access, with latencies now at around 130ns versus the +215ns on the A14, again something to keep in mind of in the next performance section of the article.
CPU Microarchitecture Changes: A Slow(er) Year?
This year’s CPU microarchitectures were a bit of a wildcard. Earlier this year, Arm had announced the new Armv9 ISA, predominantly defined by the new SVE2 SIMD instruction set, as well as the company’s new Cortex series CPU IP which employs the new architecture. Back in 2013, Apple was notorious for being the first on the market with an Armv8 CPU, the first 64-bit capable mobile design. Given that context, I had generally expected this year’s generation to introduce v9 as well, but however that doesn’t seem to be the case for the A15.
Microarchitecturally, the new performance cores on the A15 doesn’t seem to differ much from last year’s designs. I haven’t invested the time yet to look at every nook and cranny of the design, but at least the back-end of the processor is identical in throughput and latencies compared to the A14 performance cores.
The efficiency cores have had more changes, alongside some of the memory subsystem TLB changes, the new E-core now gains an extra integer ALU, bringing the total up to 4, up from the previous 3. The core for some time no longer could be called “little” by any means, and it seems to have grown even more this year, again, something we’ll showcase in the performance section.
The possible reason for Apple’s more moderate micro-architectural changes this year might be a storm of a few factors – Apple had notably lost their lead architect on the big performance cores, as well as parts of the design teams, to Nuvia back in 2019 (later acquired by Qualcomm earlier this year). The shift towards Armv9 might also imply some more work done on the design, and the pandemic situation might also have contributed to some non-ideal execution. We’ll have to examine next year’s A16 to really determine if Apple’s design cadence has slowed down, or whether this was merely just a slippage, or simply a lull before a much larger change in the next microarchitecture.
Of course, the tone here paints rather conservative improvement of the A15’s CPUs, which when looking at performance and efficiency, are anything but that.








204 Comments
View All Comments
michael2k - Monday, October 4, 2021 - link
There's been work to document and improve on out of order vs in order energy efficiency (roughly a 150% energy consumption with a CG-OoO, and 270% with normal OoO) :https://dl.acm.org/doi/pdf/10.1145/3151034
So there really is an energy efficiency benefit to 'in order'; out of order gives you a 73% performance boost but a 270% increase in energy consumption:
Performance:
https://zilles.cs.illinois.edu/papers/mcfarlin_asp...
Power:
https://stacks.stanford.edu/file/druid:bp863pb8596...
In other words, if Apple had an in-order design it would use even less power, but as I understand it they have never had an in-order design. Make lemonade out of lemons as it were.
eastcoast_pete - Monday, October 4, 2021 - link
I will take a look at the links you posted, but this is the first time I read about out-of-order execution being referred to as "lemon" vs. in-order. The out-of-order efficiency cores that Apple's SoC have had for a while now are generally a lot better on perf/W than in-order designs like the A55. And yes, a (much slower) in-order small core might consume less energy in absolute terms, but the performance per Watt is still significantly worse. Lastly, why would ARM design its big performance cores (A76/77/78, X2) as out-of-order, if in-order would make them so much more efficient?jospoortvliet - Tuesday, October 5, 2021 - link
Because they would be slower in absolute terms. In theory, all other things being equal, an in-order core should be more efficient than an out of order core. In practice, not everything is ever equal so just because apples small cores are so extremely efficient doesn't mean the theory is wrong.michael2k - Wednesday, October 6, 2021 - link
ARM can't hit the same performance using in-order, so if you need the performance you need to use an out-of-order design. In theory you could clock the in-order design faster, but the bottleneck isn't CPU performance but stalls when waiting on memory; with the out-of-order design the CPU can start working on a different chunk of instructions while still waiting on memory for the first chunk.It's essentially like having a left turn, forward, and right turn lane available, so that drivers can join different queues, vs all drivers forced to use a single lane for left, forward, and right. If the car turning left cannot move because of oncoming traffic, cars moving forward or right are blocked.
As for your question regarding perf/W, you can see four different A55s all have the same perf but different W:
https://www.anandtech.com/show/16983/the-apple-a15...
This tells us that there is more to CPU energy use than the CPU, if you also have to include memory, memory controllers, storage controllers, and storage into the equation since the CPU needs to access/power all those things just to operate. The D1200 has better p/W across all it's cores despite being otherwise similar to the E2100 at the low and mid end (both have A55 and A78 but the E2100 uses far more power for those two cores)
Ppietra - Tuesday, October 5, 2021 - link
the thing is Apple’s efficiency cores are clearly far more efficient than ARM’s efficiency cores in most workloads...Just because someone is not able to make an OoO design more efficient is not proof that any OoO will inevitably be less efficient
Andrei Frumusanu - Tuesday, October 5, 2021 - link
Discussions and papers like these about energy just on a core basis are basically irrelevant because you don't have a core in isolation, you have it within a SoC with power delivery and DRAM. The efficiency of the core here can be mostly overshadowed by the rest of the system; the Apple cores results here are extremely efficient not only because of the cores but because the whole system is incredibly efficient.Look at how Samsung massacres their A55 results, that's not because their implementation of the A55 is bad, it's because everything surrounding it is bad, and they're driving memory controllers and what not uselessly at higher power even though the active cores can't make use of any of it. It creates a gigantic overhead that massively overshadows the A55 cores.
name99 - Thursday, October 7, 2021 - link
You are correct but as always the devil is in the details.(a) What EXACTLY is the goal? In-order works if the goal is minimal energy at some MINIMAL level of performance. But if you require performance above a certain level, in-order simple can't deliver (or, more precisely, the contortions required plus the frequency needed make this a silly exercise).
For microcontroller levels of performance, in-order is fine. You can boost it to two-wide and still do well; you can augment it with some degree of speculation and still do OK, but that's about it. ARM imagined small cores as doing a certain minimal level of work; Apple imagined them doing a lot more, and Apple appears to (once again) have skated closer to where the puck was heading, not where it was.
(b) Now microcontrollers are not nothing. Apple has their own controller core, Chinook, that's used all over the place (their are dozens of them on an M1) controlling things like GPU, NPU, ISP, ... Chinook is AArch64, at least v8.3 (maybe updated). It may be an in-order core, two or even one-wide, no-one knows much about [what we do know is mainly what we can get from looking at the binary blobs of the firmware that runs on it].
Would it make sense for Apple to have a programmer visible core that was between Chinook and Blizzard? For example give Apple Watch two small cores (like today) and two "tiny" cores to handle everything but the UI? Maybe? Maybe not if the core power is simply not very much compared to everything else (always-on stuff, radios, display, sensors, ...)?
Or maybe give something like Airpods a tiny core?
(c) Take numbers for energy and performance for IO vs OoO with a massive grain of salt. There have been various traditional ways of doing things for years; but Apple has up-ended so much of that tradition, figuring out ways to get the performance value of OoO without paying nearly as much of the energy cost as people assumed.
It's not that Apple invented all this stuff from scratch, more that there was a pool of, say, 200 good ideas out there, but every paper assumed "baseline+my one good idea", only Apple saw the tremendous *synergy* available in combining them all in a single design.
We can see this payoff in the way that Apple's small cores get so much performance at such low energy cost compared to ARM's in-order orthodoxy cores. Apple just isn't paying much of an energy price for all its smarts.
And yes, the cost of all this is more transistors and more area. To which the only logical response is "so what? area and transistors are cheap!"
Nicon0s - Tuesday, October 5, 2021 - link
>I don't see how they can get even close to the efficiency cores in Apple's SoC.Very simple actually. By optimized/modifying a Cortex A76.
The latest A510 is very very small and this limit's the potential of such a core.
techconc - Monday, October 18, 2021 - link
>Very simple actually. By optimized/modifying a Cortex A76.LOL... That would take a hell of a lot of "optimization" and a bit of magic maybe. The A15 efficiency cores match the A76 in performance at about 1/4 the power.
Raqia - Monday, October 4, 2021 - link
Interesting that the extra core on the 13 Pro GPU doesn't seem to do add much performance much over the 13's 4 cores even when unthrottled, certainly not 20%. Perhaps the bottleneck has to do with memory bandwidth.