The AMD Ryzen 7 5700G, Ryzen 5 5600G, and Ryzen 3 5300G Review
by Dr. Ian Cutress on August 4, 2021 1:45 PM ESTMicrobenchmarks
Core-to-Core Latency
As the core count of modern CPUs is growing, we are reaching a time when the time to access each core from a different core is no longer a constant. Even before the advent of heterogeneous SoC designs, processors built on large rings or meshes can have different latencies to access the nearest core compared to the furthest core. This rings true, especially in multi-socket server environments.
But modern CPUs, even desktop and consumer CPUs, can have variable access latency to get to another core. For example, in the first-generation Threadripper CPUs, we had four chips on the package, each with 8 threads, and each with a different core-to-core latency depending on if it was on-die or off-die. This gets more complex with products like Lakefield, which has two different communication buses depending on which core is talking to which.
If you are a regular reader of AnandTech’s CPU reviews, you will recognize our Core-to-Core latency test. It’s a great way to show exactly how groups of cores are laid out on the silicon. This is a custom in-house test built by Andrei, and we know there are competing tests out there, but we feel ours is the most accurate to how quick an access between two cores can happen.
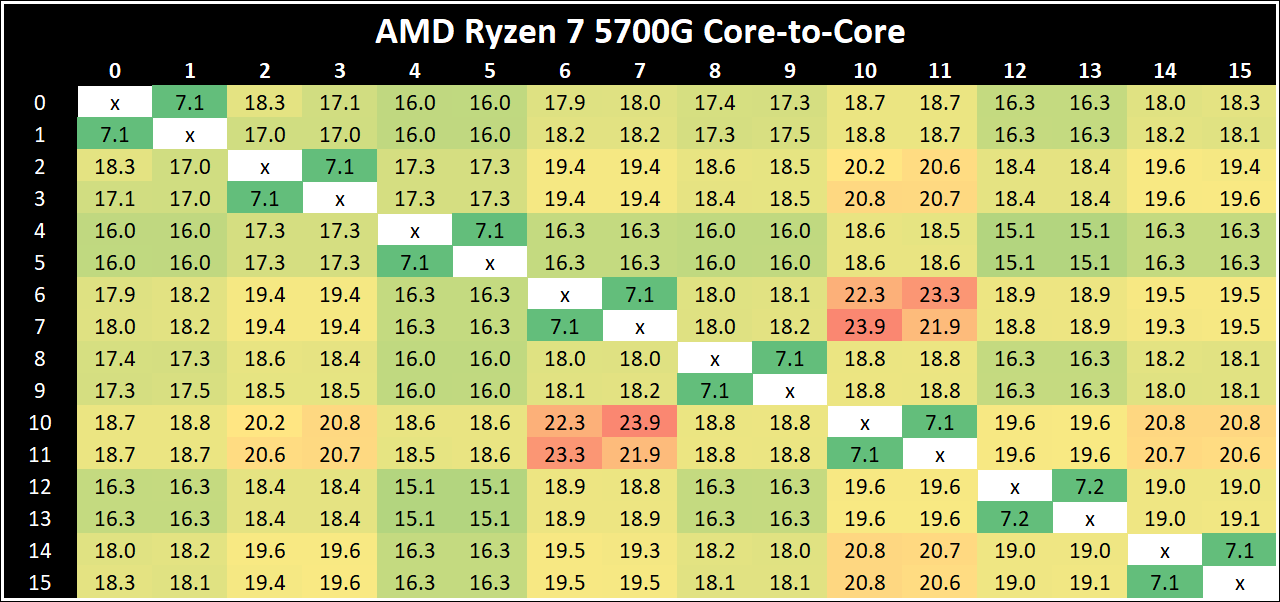
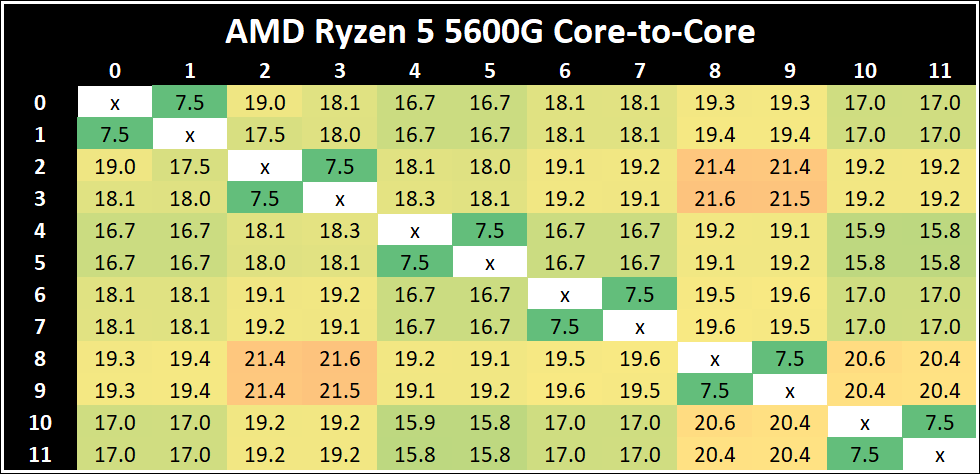
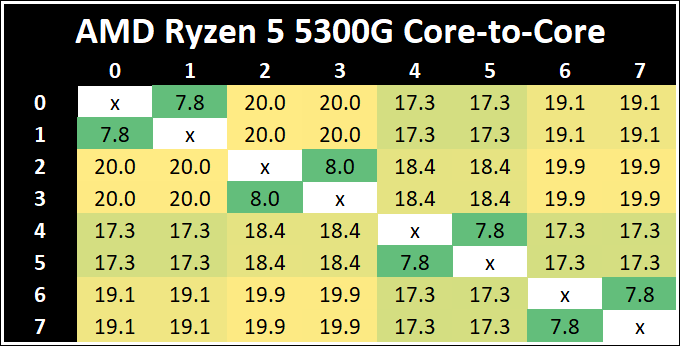
The Ryzen 7 5700G has the quickest thread-to-thread latency, however does offer a single slowest core-to-core latency. But compared to the 4000G series, having a single unified L3 cache reduces to core-to-core latency a good amount. The Ryzen 5 5300G has the slowest intracore latency, but the fastest average core-to-core.
Per-Core Power
One other angle to examine is how much power each core is drawing with respect to the rest of the chip. In this test, we run POV-Ray with a specific thread mask for a minute, and take a power reading 30 seconds into the test. We output the core power values from all cores, and compare them to the reported total package power.
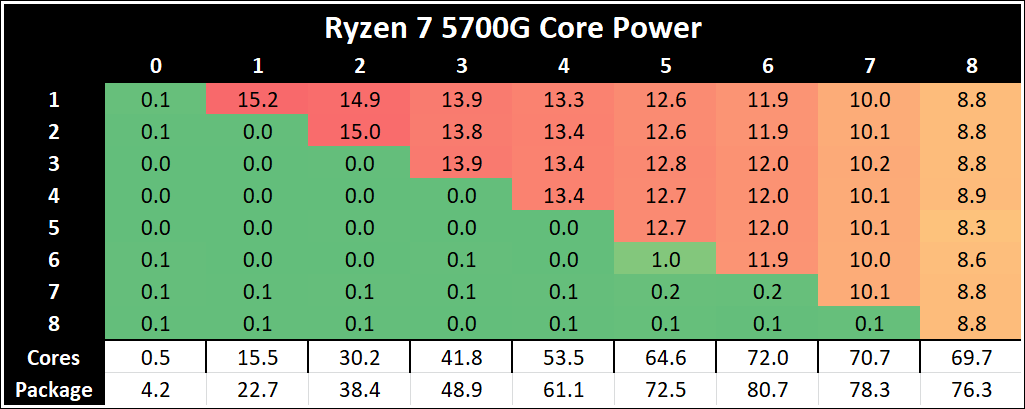

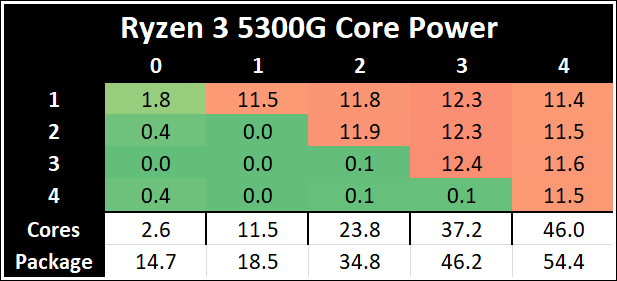
The peak per-core power is shown as 15.2 W when one core is loaded on the Ryzen 7 5700G, and that comes down to ~8.8W when all cores are loaded. Interestingly this processor uses more power when six cores are loaded.
The Ryzen 5 5300G starts at 11.5 W for a single core, but then moves up to 12.3 W when three cores are loaded. It comes back down to 11.5 W when all four cores are loaded, but this ensures a consistent frequency (the 5300G has a 4.2 GHz Base and 4.4 GHz Turbo, explaining the small variation in loading).
Frequency Ramping
Both AMD and Intel over the past few years have introduced features to their processors that speed up the time from when a CPU moves from idle into a high-powered state. The effect of this means that users can get peak performance quicker, but the biggest knock-on effect for this is with battery life in mobile devices, especially if a system can turbo up quick and turbo down quick, ensuring that it stays in the lowest and most efficient power state for as long as possible.
Intel’s technology is called SpeedShift, although SpeedShift was not enabled until Skylake.
One of the issues though with this technology is that sometimes the adjustments in frequency can be so fast, the software cannot detect them. If the frequency is changing on the order of microseconds, but your software is only probing frequency in milliseconds (or seconds), then quick changes will be missed. Not only that, as an observer probing the frequency, you could be affecting the actual turbo performance. When the CPU is changing frequency, it essentially has to pause all compute while it aligns the frequency rate of the whole core.
We wrote an extensive review analysis piece on this, called ‘Reaching for Turbo: Aligning Perception with AMD’s Frequency Metrics’, due to an issue where users were not observing the peak turbo speeds for AMD’s processors.
We got around the issue by making the frequency probing the workload causing the turbo. The software is able to detect frequency adjustments on a microsecond scale, so we can see how well a system can get to those boost frequencies. Our Frequency Ramp tool has already been in use in a number of reviews.
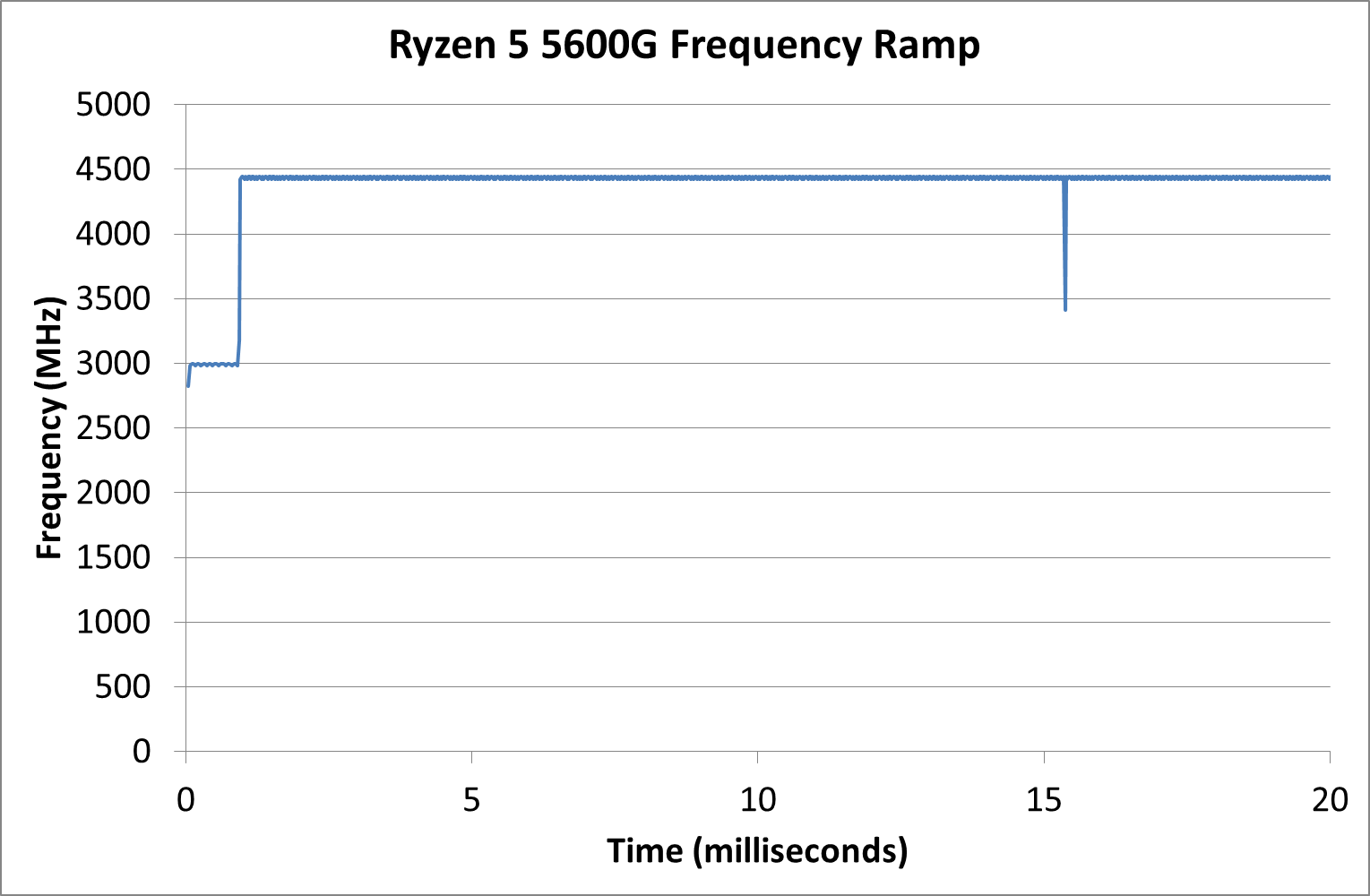
In our test, the Ryzen 5 5600G jumps from 2700 to the turbo frequency in around a millisecond.








135 Comments
View All Comments
Wereweeb - Wednesday, August 4, 2021 - link
The bottleneck is memory bandwidth. DDR5 will raise the iGPU performance roof by a substantial amount, but I hope for something like quad-channel OMI-esque Serial RAM.abufrejoval - Saturday, August 7, 2021 - link
I'd say so, too, but...I have just had a look at a Kaveri A10-7850K with DDR3-2400 (100 Watt desktop), a 5800U based notebook with LPDDR4 (1333MHz clock) and a Tiger Lake NUC with an i7-1165G7 with DDR4-3200.
The memory bandwidth differences between the Kaveri and the 5800U is absolutely minor, 38.4 GB/s for the Kaveri vs. 42.7GB/s for Cezanne (can't get the TigerLake figures right now, because it's running a Linux server, but it will be very similar).
The Kaveri and Cezanne iGPUs are both 512 shaders and apart from architectural improvements very much differ in clocks 720MHz vs. 2000MHz. The graphics performance difference on things like 3DMark scale pretty exactly with that clock difference.
Yet when Kaveri was launched, Anandtech noted that the 512 shader A10 variant had trouble to do better then the 384 shader APUs, because only with the very fastest RAM it could make these extra shaders pump out extra FPS.
When I compared the Cezanne iGPU against the TigerLake X2, both systems at tightly fixed 15 and 28Watts max power settings, TigerLake was around 50% faster on all synthetic GPU benchmarks.
The only explanation I have for these fantastic performance increases is much larger caches being very smartly used by breaking down GPU workloads to just fit within them, while prefetching the next tile of bitmaps into the cache in the background and likewise pushing processed tiles to the framebuffer RAM asynchronously to avoid stalling GPU pipelines.
And yet I'd agree that there really isn't much wiggling room left, you need exponential bandwidth to cover square resolution increases.
abufrejoval - Saturday, August 7, 2021 - link
need edit!Is TigerLake Xe, not X2.
Another data point:
I also have an NUC8 with an 48EU (+128MB eDRAM) Iris 655 i7 and a NUC10 with an 24EU "no Iris" UHD i7. Even with twice the EUs and the extra eDRAM (which I believe can be used in parallel to the external DRAM), the Iris only gets a 50% performance increase.
The the 96EU TigerLake iGPU is doing so much better (better than linear scale over UHD) while it actually has somewhat less bandwidth (and higher latency) than the 50GB/s eDRAM provides for the 48EU Iris.
bwj - Wednesday, August 4, 2021 - link
Why are these parts getting stomped by Intel and their non-graphics Ryzen siblings?bwj - Wednesday, August 4, 2021 - link
Meh, meant to say "in browser benchmarks". Browser is an important workload (for me at least) and the x86 crowd is already fairly weak versus Apple M1, so I'm not ready to throw away another 30% of browser perf.Lezmaka - Wednesday, August 4, 2021 - link
There are only 3 browser tests and for two of them the 5700G is within a few percent of the 11700K. But otherwise, it's because these are laptop chips with higher TDP. The 11700K has a TDP of "125W" but hit 277W where the 5700G has a TDP of 65W and maxed out at 88W.Makaveli - Wednesday, August 4, 2021 - link
There is something up with the browser scores here anyways compared to what you see in the forum. All the post with similar desktop cpu's in that thread post much high scores than what is listed in the graph. I'm not sure its old browser version being used to keep scores inline with older reviews or something.https://forums.anandtech.com/threads/how-fast-is-y...
abufrejoval - Wednesday, August 4, 2021 - link
When you ask: "Why don't they release the four core variant?" you really should be able to answer that yourself!There are simply not enough defective chips to make it viable just yet. Eventually they may accumulate, but as long as they are trying to produce an 8 core chip, 4 and 6 cores should remain the exception not the rule.
I'd really like to see them struggle putting the lesser chips out there, because it means my 8/16(/32/64) core chips are rock solid!
I would have liked to see full transistor counts of the 5800X and the 5700U side by side. My guess would be that the Cezanne dies even at 50% cache have more transistors overall, meaning you are getting many more pricey 7nm transistors per € on these APUs and should really pay a markup not a discount.
Well even the GF IO die fab capacity might have customers lined up these days, but in normal times those transistors should be much more commodity and cheaper and have the APU cost more in pure foundry (less in packaging) than the X-variants, while AMD wants to fit it into a below premium price slot where it really doesn't belong.
nandnandnand - Wednesday, August 4, 2021 - link
If AMD boosted chiplet/monolithic core count to 12, maybe 6 cores could become the new minimum with 10-core being a possibility. But it doesn't look like they plan to do that.Wereweeb - Wednesday, August 4, 2021 - link
These might have been a stockpile of dies that were rejected for laptop use (High power consumption @ idle?) and they're being dumped into the market after AMD satisfied OEM demand for APU's.Plus, considering that one of the main shortages is for substrates, it's possible that the substrate for the APU's is different - cheaper, higher volume, etc... as it doesn't need to interconnect discrete chiplets.