64 Cores of Rendering Madness: The AMD Threadripper Pro 3995WX Review
by Dr. Ian Cutress on February 9, 2021 9:00 AM EST- Posted in
- CPUs
- AMD
- Lenovo
- ThinkStation
- Threadripper Pro
- WRX80
- 3995WX
CPU Tests: Microbenchmarks
A y-Cruncher Sprint
The y-cruncher website has a large amount of benchmark data showing how different CPUs perform when calculating pi up to a given number of digits. Not only are the pi world records present, but below these there are a few CPUs showing the scaling of the hardware, where it shows the time to compute moving from 25 million digits to 50 million, 100 million, 250 million, and all the way up to 10 billion, to showcase how the performance scales with digits (assuming everything is in memory). This range of results, from 25 million to 250 billion, is something I’ve dubbed a ‘sprint’.
I have written some code in order to perform a sprint on every CPU we test. It detects the DRAM, works out the biggest value that can be calculated with that amount of memory, and works up starting from 25 million digits. For the tests that go up to the ~25 billion digits, it only adds an extra 15 minutes to the suite for an 8-core Ryzen CPU. With this test, we can see the effect of increasing memory requirements on the workload and the scaling factor for a workload such as this.
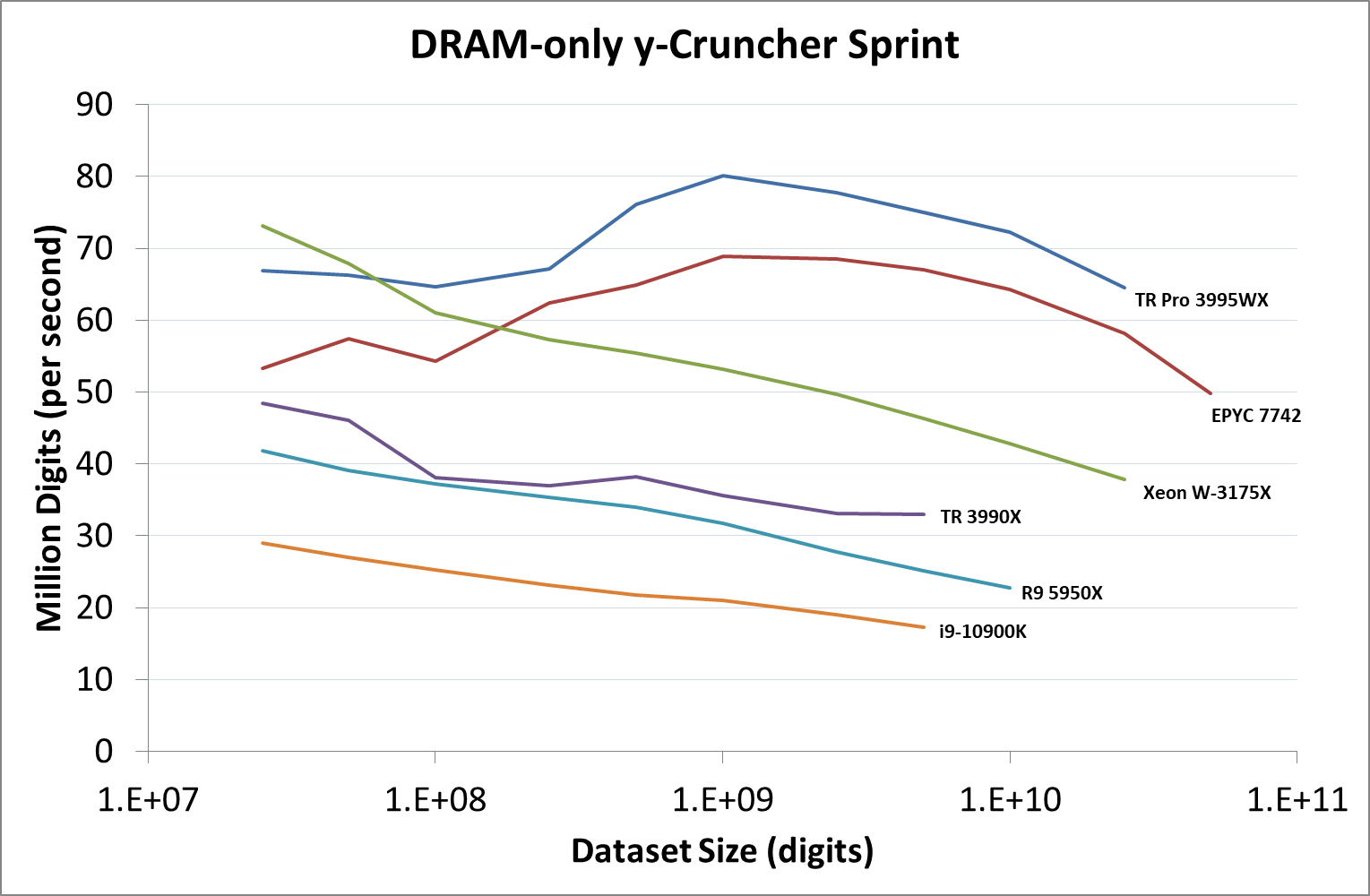
Longer lines indicate more memory installed in the system at the time
For this sprint, we’ve covered each result into how many million digits are calculated per second at each of the dataset sizes. The more cores a system has, the better the compute, and Intel gets an AVX-512 bonus here as well because the software can use AVX-512. But as the dataset gets larger, there is more shuffling of values back and forth between memory and cache, so being able to keep a high bandwidth while also a low latency to all cores is crucial in this test, especially as the test increases.
The 8-channel 64-core TR Pro 3995WX here does very well, peaking at around 80 million per second, and at the end of the test still being very fast. It sits above the EPYC 7742 here due to the fact that it has a higher TDP and frequency. They are both well above the Threadripper 3990X, which only has quad-channel memory, which is the reason for the decrease as the dataset increases.
The W-3175X from Intel has the AVX-512 advantage, which is why the 28 cores can compete with the 64 cores from AMD, however the six-channel memory bandwidth and probably the mesh quickly becomes a bottleneck as each core needs to feed those AVX-512 units. This is the sort of situation where in-package HBM is likely to make a big difference. But at the smaller dataset sizes at least the W-3175X can feed enough data across the mesh to the AVX-512 units for the peak throughput.
Core-to-Core Latency
As the core count of modern CPUs is growing, we are reaching a time when the time to access each core from a different core is no longer a constant. Even before the advent of heterogeneous SoC designs, processors built on large rings or meshes can have different latencies to access the nearest core compared to the furthest core. This rings true especially in multi-socket server environments.
But modern CPUs, even desktop and consumer CPUs, can have variable access latency to get to another core. For example, in the first generation Threadripper CPUs, we had four chips on the package, each with 8 threads, and each with a different core-to-core latency depending on if it was on-die or off-die. This gets more complex with products like Lakefield, which has two different communication buses depending on which core is talking to which.
If you are a regular reader of AnandTech’s CPU reviews, you will recognize our Core-to-Core latency test. It’s a great way to show exactly how groups of cores are laid out on the silicon. This is a custom in-house test built by Andrei, and we know there are competing tests out there, but we feel ours is the most accurate to how quick an access between two cores can happen.

Due to a test limitation, we’re only probing the first 64 threads of the system, but the scale out to 128 threads would be identical. This generation of Threadripper Pro is built on Zen 2, similar to Threadripper 3990X and the EPYC 7742, and so we only have quad-core CCXes in play here. A thread speaking to itself has a latency of around 7 nanoseconds, inside a quad-core CCX is around 18-19 nanoseconds, and then accessing any other core varies from 77-89 nanoseconds. Even accessing the CCX on the same chiplet has the same latency, as the communication is designed to ping out to the central IO die first. If Threadripper Pro gets boosted to Zen 3 for the next generation, this will be a big uplift as we’ve already seen with Zen 3. But TR Pro with Zen 3 might only be launched only when Zen 4 comes out, and we’ll be talking about that difference when that happens.
Frequency Ramping
Both AMD and Intel over the past few years have introduced features to their processors that speed up the time from when a CPU moves from idle into a high powered state. The effect of this means that users can get peak performance quicker, but the biggest knock-on effect for this is with battery life in mobile devices, especially if a system can turbo up quick and turbo down quick, ensuring that it stays in the lowest and most efficient power state for as long as possible.
Intel’s technology is called SpeedShift, although SpeedShift was not enabled until Skylake.
One of the issues though with this technology is that sometimes the adjustments in frequency can be so fast, software cannot detect them. If the frequency is changing on the order of microseconds, but your software is only probing frequency in milliseconds (or seconds), then quick changes will be missed. Not only that, as an observer probing the frequency, you could be affecting the actual turbo performance. When the CPU is changing frequency, it essentially has to pause all compute while it aligns the frequency rate of the whole core.
We wrote an extensive review analysis piece on this, called ‘Reaching for Turbo: Aligning Perception with AMD’s Frequency Metrics’, due to an issue where users were not observing the peak turbo speeds for AMD’s processors.
We got around the issue by making the frequency probing the workload causing the turbo. The software is able to detect frequency adjustments on a microsecond scale, so we can see how well a system can get to those boost frequencies. Our Frequency Ramp tool has already been in use in a number of reviews.
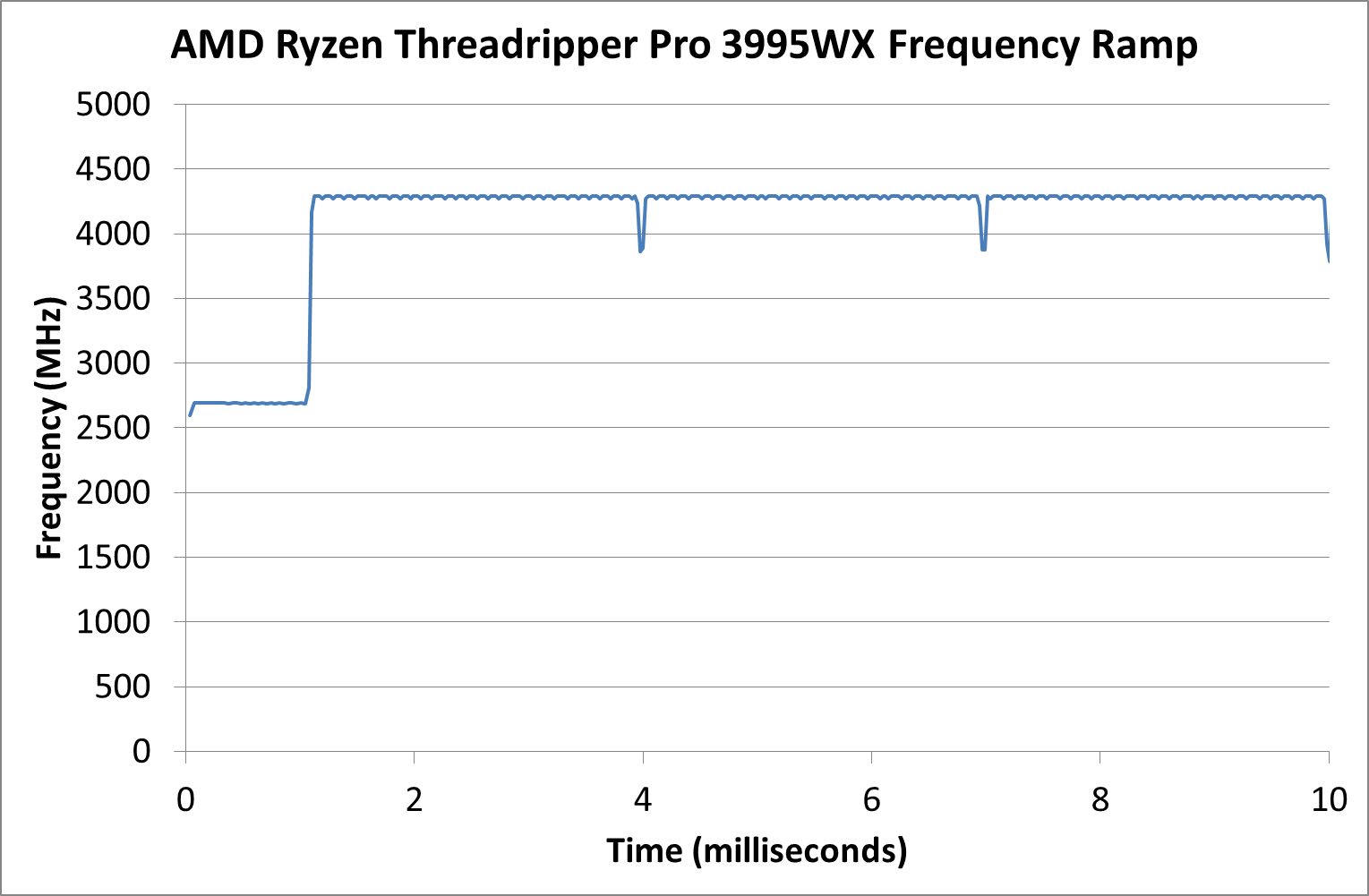
The frequency ramp here is around one millisecond, indicative of AMD implementing its CPPC2 management design.








118 Comments
View All Comments
kwinz - Wednesday, February 10, 2021 - link
Really? CPUs are in high demand because GPU programming is hard? That's what you're going with?Gomez Addams - Wednesday, February 10, 2021 - link
Good heavens that was painful to read. Some of the worst writing have had to suffer through in a while. One tip : compute is a verb and not a noun, just as simulation is a noun and simulate is a verb. Just because marketing droids use a term does not mean it is correct.Spunjji - Thursday, February 11, 2021 - link
Sorry pal, language doesn't work that way. You may not *like* it, but that's the way it is!croc - Wednesday, February 10, 2021 - link
Are we now ignoring the elephant? EPYC was to launch in 2020. Actually, AMD said that Zen 3 would launch in 2020, but there's a weasel in them words... SOME of the Zen 3 cpu's DID launch, mostly looking like paper though. EPYC is sort-of launching as we speak, and Zen 3 Threadripper is a no-show.I have said this elsewhere, and I will say it here. It would appear that AMD's lack of fab experience is showing, as they seem to be having issues getting their designs to fab properly at 7nm. Low to no yields? And TSMC is having issues of their own with China buying up as much talent as it can, while threatening to just grab it all in a military takeover. TSMC should have already built an advanced fab somewhere in the west, out of China's reach. Europe? Canada? After Trump, I would say to avoid the US as much as it needs to avoid China.
Spunjji - Thursday, February 11, 2021 - link
AMD were hoping to get Milan into production in Q3 2020 and have it shipping to some customers by Q4, which they did. It's not available to OEMs yet, so hardly a fanfare moment, but not the "elephant" you're trying to paint it as either.Same goes for Zen 3, too - it absolutely wasn't a "paper launch" - but I see you're just here to push FUD rather than discuss *the article*.
Like, what's this "they seem to be having issues getting their designs to fab properly at 7nm" crap? Whose backside are you pulling that out of?
Amazing how many people seem to think these comment sections are the ideal place to grind their own personal political axes.
Oxford Guy - Thursday, February 11, 2021 - link
‘Amazing how many people seem to think these comment sections are the ideal place to grind their own personal political axes’You seem to think this is your personal website.
Qasar - Thursday, February 11, 2021 - link
as do you, point is ?Oxford Guy - Wednesday, March 10, 2021 - link
It’s not the tu quoque fallacy.tygrus - Thursday, February 11, 2021 - link
If total desktop sales were 20Million in 2020Q4 and if AMD sold 5M with about 0.95M being Zen3 so AMD could have been 19% of desktop CPU sales being Zen3. That's a good start and a lot better than <5% you may think happens for a paper launch. Notebook market adds another 50M/qtr (20% AMD?) and tablets (probably not AMD) on top of that so Zen3 sales would look like ~7% of AMD consumer CPU's sold that qtr.Not all sales & deliveries are publicised so server sales may have happened already for Zen3. The FAB capacity & yield were more than enough because it was the substrate & final assembly which limited supply.
ipkh - Sunday, February 28, 2021 - link
Really, they have Global Foundries to thank for this. Global Foundries miseead the market and decided to drop highend node production. This left TSMC as the only highend node company left standing (that does 3rd party fab). Global Foundries and Samsung could have had a much better roadmap working together with IBMs researchers. But they didn't and now we see how much it is costing the entire industry. AMD may be forced to use Samsung Foundries if TSMC production gets tied up.