AMD Ryzen 9 5980HS Cezanne Review: Ryzen 5000 Mobile Tested
by Dr. Ian Cutress on January 26, 2021 9:00 AM EST- Posted in
- CPUs
- AMD
- Vega
- Ryzen
- Zen 3
- Renoir
- Notebook
- Ryzen 9 5980HS
- Ryzen 5000 Mobile
- Cezanne
CPU Tests: Simulation
Simulation and Science have a lot of overlap in the benchmarking world, however for this distinction we’re separating into two segments mostly based on the utility of the resulting data. The benchmarks that fall under Science have a distinct use for the data they output – in our Simulation section, these act more like synthetics but at some level are still trying to simulate a given environment.
DigiCortex v1.35: link
DigiCortex is a pet project for the visualization of neuron and synapse activity in the brain. The software comes with a variety of benchmark modes, and we take the small benchmark which runs a 32k neuron/1.8B synapse simulation, similar to a small slug.
The results on the output are given as a fraction of whether the system can simulate in real-time, so anything above a value of one is suitable for real-time work. The benchmark offers a 'no firing synapse' mode, which in essence detects DRAM and bus speed, however we take the firing mode which adds CPU work with every firing.
The software originally shipped with a benchmark that recorded the first few cycles and output a result. So while fast multi-threaded processors this made the benchmark last less than a few seconds, slow dual-core processors could be running for almost an hour. There is also the issue of DigiCortex starting with a base neuron/synapse map in ‘off mode’, giving a high result in the first few cycles as none of the nodes are currently active. We found that the performance settles down into a steady state after a while (when the model is actively in use), so we asked the author to allow for a ‘warm-up’ phase and for the benchmark to be the average over a second sample time.
For our test, we give the benchmark 20000 cycles to warm up and then take the data over the next 10000 cycles seconds for the test – on a modern processor this takes 30 seconds and 150 seconds respectively. This is then repeated a minimum of 10 times, with the first three results rejected. Results are shown as a multiple of real-time calculation.

DigiCortex seems to have taken a shine to Zen 3, especially processors with a single chiplet of cores. Intel can't seem to compete here.
Dwarf Fortress 0.44.12: Link
Another long standing request for our benchmark suite has been Dwarf Fortress, a popular management/roguelike indie video game, first launched in 2006 and still being regularly updated today, aiming for a Steam launch sometime in the future.
Emulating the ASCII interfaces of old, this title is a rather complex beast, which can generate environments subject to millennia of rule, famous faces, peasants, and key historical figures and events. The further you get into the game, depending on the size of the world, the slower it becomes as it has to simulate more famous people, more world events, and the natural way that humanoid creatures take over an environment. Like some kind of virus.
For our test we’re using DFMark. DFMark is a benchmark built by vorsgren on the Bay12Forums that gives two different modes built on DFHack: world generation and embark. These tests can be configured, but range anywhere from 3 minutes to several hours. After analyzing the test, we ended up going for three different world generation sizes:
- Small, a 65x65 world with 250 years, 10 civilizations and 4 megabeasts
- Medium, a 127x127 world with 550 years, 10 civilizations and 4 megabeasts
- Large, a 257x257 world with 550 years, 40 civilizations and 10 megabeasts
DFMark outputs the time to run any given test, so this is what we use for the output. We loop the small test for as many times possible in 10 minutes, the medium test for as many times in 30 minutes, and the large test for as many times in an hour.
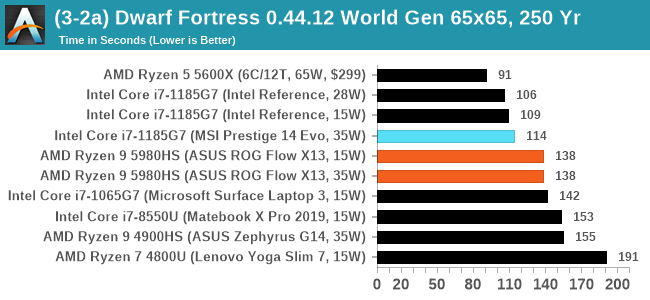


DF has historically been an Intel favorite, and we're not seeing much of a speedup for mobile Zen 3 over mobile Zen 2 here.
Dolphin v5.0 Emulation: Link
Many emulators are often bound by single thread CPU performance, and general reports tended to suggest that Haswell provided a significant boost to emulator performance. This benchmark runs a Wii program that ray traces a complex 3D scene inside the Dolphin Wii emulator. Performance on this benchmark is a good proxy of the speed of Dolphin CPU emulation, which is an intensive single core task using most aspects of a CPU. Results are given in seconds, where the Wii itself scores 1051 seconds.

The 35W variant of Cezanne pushes through here, matching the desktop processor, and a sizeable performance jump over the previous generation Renoir.








218 Comments
View All Comments
Meteor2 - Thursday, February 4, 2021 - link
Web JavaScript benchmarks really don't count for much. They certainly don't reflect the user experience of the web.DigitalFreak - Tuesday, January 26, 2021 - link
It's all about the money, and I'm pretty sure Intel is handing out more marketing funds and rebates than AMD. Most people don't care if they have Intel or AMD in their laptop.msroadkill612 - Tuesday, January 26, 2021 - link
Yes its about money and no Intels strategies dont seem to be hiding reality so well these days - OEMs are deserting their designs in droves.There is a deal breaking cost & power saving at the mainstream mobile sweet spot, where the APU delivers competent modern graphics w/o need of a DGPU.
Intel can only match amd graphics by adding a dgpu.
Deicidium369 - Wednesday, January 27, 2021 - link
"OEMs are deserting their designs in droves." Really? So now only 10:1 vs AMD designs?Deicidium369 - Wednesday, January 27, 2021 - link
Providing designs to OEMs and supplying most of the parts for a laptop - making it super easy for them to come to market with an Intel design... That's called smart business.Spunjji - Thursday, January 28, 2021 - link
That's not the same thing as marketing funds and rebates, which Intel also do - they even do it at the reseller level.So there's "smart business", then there's "buying marketshare", and then there's "outright bribery". Intel got fined for doing the last one, so now they mostly only do the first two - although it's a toss-up as to whether you think their contra-revenue scheme counted as option 2 or 3.
theqnology - Wednesday, January 27, 2021 - link
It's easy to compare them (M1 vs x86) on some metrics, but I think it is more nuanced than that. Do note that M1 is at 5nm, with size at around 120.5mm^2. The AMD parts are at 180mm^2 at 7nm. The M1 has 16 billion transistors versus 10.7 billion transistors for the Zen3 APUs. That is 49.5% more transistors in favor of M1.I think a huge part of the reason M1 performs so well in many benchmarks, are that it can target specific workloads, and offload it to specific hardware cores for specific accelerated performance at lower power consumption. It becomes easy for Apple to achieve such, I think, because this is all transparent from the application developers, as they control the entire hardware AND software stack, much like consoles performing at high-end GPU levels despite having less powerful GPU cores.
This is not a cost-effective approach, although not impossible for AMD and Intel. Also part of the reason why I think if M1 were put into cloud servers, it would not be cost-effective. There will be so much dedicated hardware accelerated cores that will not be put to use when M1 is deployed in the cloud.
That said, Apple M1 is a great feat. Hopefully, AMD can also achieve a similar feat (high efficiency accelerated processing) using their Infinity Fabric and glue, allowing them to continue focusing on their Zen cores while also uplifting ancillary workload performance. The big impediment here, would be the OS support, unless it becomes a standard.
GeoffreyA - Sunday, January 31, 2021 - link
An interesting thought and one I'd like to see reviewers looking into. Also, if it were possible to get Windows ARM running on the M1, that would be an insightful experiment, removing Apple's software layers out of the picture.Deicidium369 - Wednesday, January 27, 2021 - link
Intel is in premium laptops because they make it easy for the OEMs to make good designs - not only the "blueprints" but also high efficiency parts other than just the CPU. So an OEM has little to no R&D expense, and can roll out a great laptop.AMD should do the same - it's good business and would negate the reticence of the OEMs to invest in a smaller segment - not like this would have AMD selling more than Intel - but would improve their market presence in laptops significantly.
Spunjji - Thursday, January 28, 2021 - link
"AMD should do the same"I suspect they will once they have the funds to do so. You can't just bully your way into a market by copying the precise strategies of a company that's several times larger than you.