Hot Chips: Intel EMIB and 14nm Stratix 10 FPGA Live Blog (8:45am PT, 3:45pm UTC)
by Ian Cutress on August 22, 2017 11:24 AM EST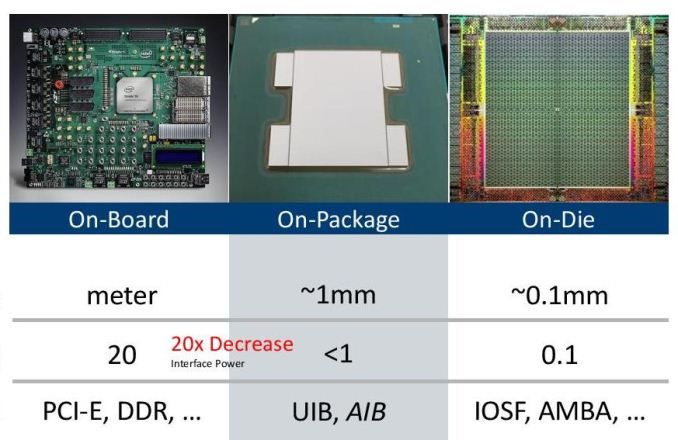
11:28AM EDT - Today at Hot Chips we have a lot of interesting talks going on. First up is a talk on Intel's latest 14nm FPGA solution: Stratix 10 implementing HBM using Intel's latest EMIB (embedded multi-die interconnect bridge) technology that may migrate over to enterprise CPUs over the next few years.
11:30AM EDT - Other talks today include Google's TPU, IBM's z CPU, as well as talks on EPYC, Xeon and Centriq (we've covered these before)
11:30AM EDT - Sorry again today we're fighting the WiFi. With today being the busiest day of the conference, I'm expecting there to be strain on the data. So pictures may come after the talks.

11:33AM EDT - Aside from the Stratix 10 FPGA news, EMIB is particularly exciting
11:34AM EDT - As we move to smaller process nodes, it makes massive monolithic chips harder to create. Yields go down and it gets expensive
11:34AM EDT - The solution to this is to create a multi-die package, using interconnects between the chips. We've seen this for years, and most recently in Xeon Phi and EPYC
11:35AM EDT - So while we've had the frequency wars, we're in the Core wars, to a certain extent the server market is in the midst of the communcation wars: how can data be moved in bulk at low latency
11:35AM EDT - Die to die communication now becomes an area calling out for innocation
11:36AM EDT - Standard chip-to-chip communications can come in two main ways. Either through the package, or via an interposer (such as Fiji, Vega, Volta)
11:36AM EDT - EMIB is a mid-way point in this. Signals still go through the package, but the package is modified to allow for shorter paths and faster connectivity
11:37AM EDT - As shown on the picture at the top, it allows for silicon dies to get super close as well
11:37AM EDT - Intel has announced EMIB before, most noticeably at their manufacturing tech day earlier this year
11:39AM EDT - We'll see it in FPGAs first, that require access to high bandwidth memory (and customers are willing to pay)
11:39AM EDT - Although the future of the technology can mean that we will have multiple dies on package made at different process nodes. The cores at one node, the onboard memory at another node, perhaps integrated accelerators/RF at other nodes etc

11:41AM EDT - This image is what Intel showed back at the Manufacturing Day
11:41AM EDT - This is why the technology comes across as fascinating to the future of Intel's processor lines. Especially as we hit 10nm and below
11:41AM EDT - Obviously the other semiconductor companies will have to implement their own solution, whether it is through the package or using an interposer
11:42AM EDT - I'll be uploading the slides as quick as I can as the talk progresses. Should start in a few minutes
11:48AM EDT - OK here we go
11:50AM EDT - As time goes on, packaging features are more of the platform over than the silicon
11:50AM EDT - Long dev cycles
11:51AM EDT - So high non-recurring engineering cost and longer time to market
11:51AM EDT - So develop a new packaging technology to help this
11:52AM EDT - 'Amortize the engineering over several identical items, or evolve flexible technologies'
11:52AM EDT - 'Build a large system out of smaller parts.
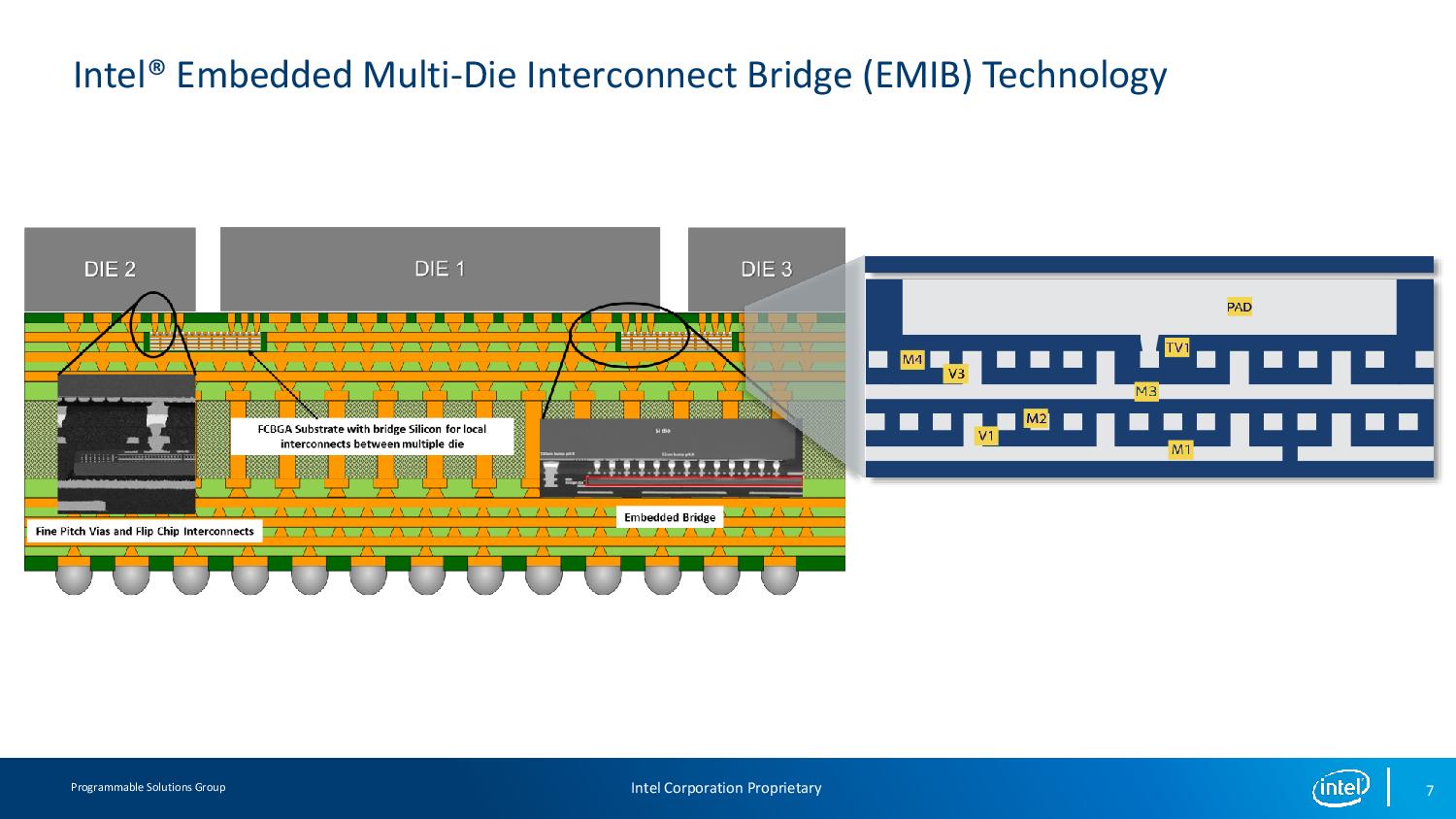
11:54AM EDT - Small sliver of silicon in the package
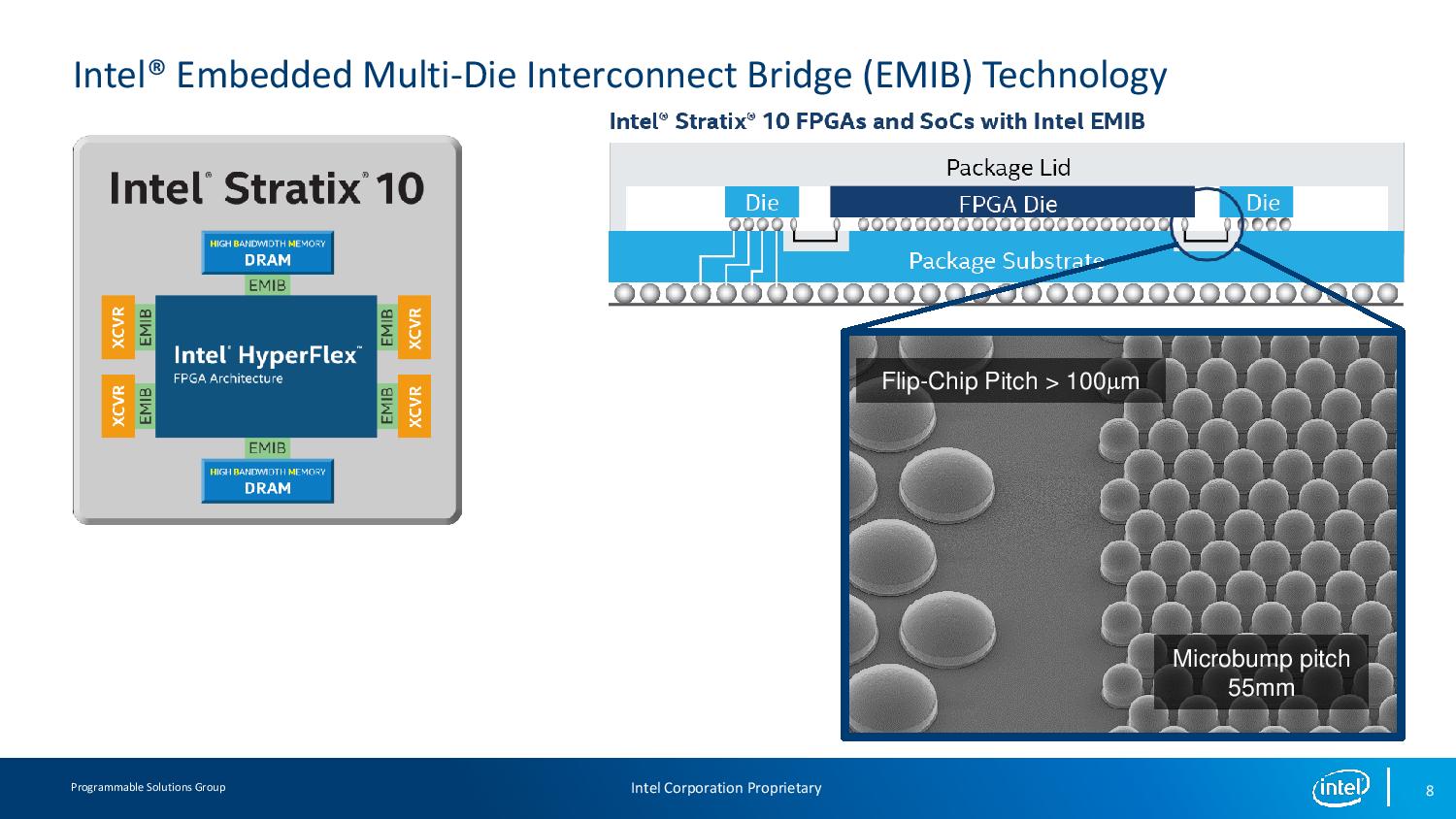
11:54AM EDT - Now Build the system: Intel Stratix 10 with four tranceiver chiplets and two DRAM chiplets
11:56AM EDT - Now Build the system: Intel Stratix 10 with four tranceiver chiplets and two DRAM chiplets
11:57AM EDT - Using multibump pitch on the FPGA die
11:57AM EDT - Interposer is also available, but EMIB is only localised digital connections. Other IOs/RG are unaffected, and can use multiple bridges. In an interposer, you need to have TSVs for non-cross chip communication. All the signals need to go through
11:58AM EDT - So reduced fabrication and assembly, cost effective, high perf solution. Also no reticle size limits now: build a system as large as your package.
11:58AM EDT - So comparison: onboard routing is 20 pJ/b (PCIe, DDR), on-die is 0.1 pJ/b (AMBA, IOSF), But with EMIB, distance is 100 micron, power is under 1pJ/b
11:58AM EDT - So defining the standard. Data rate as a function of brakout density (IO per mm at die edge)
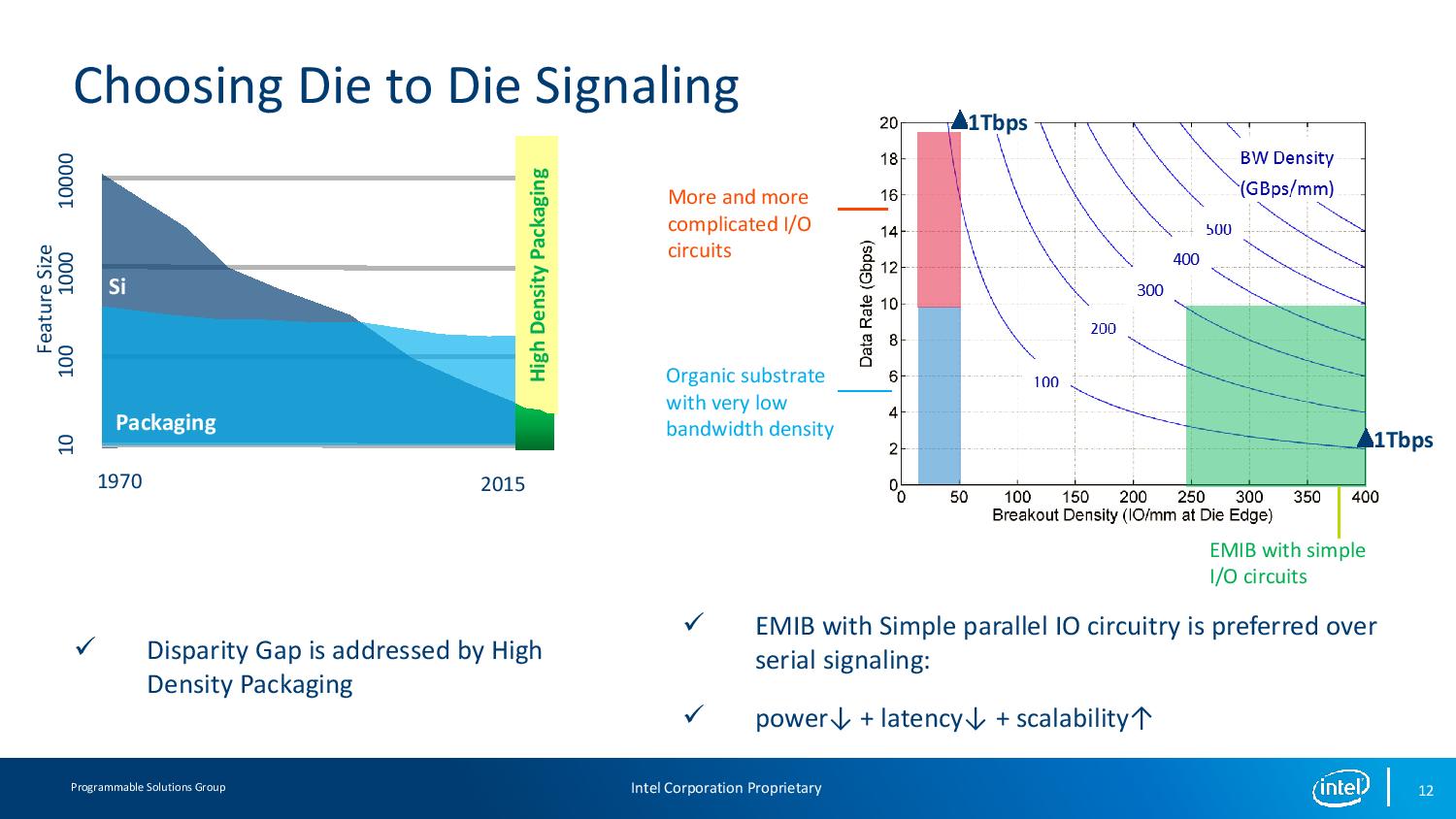
11:59AM EDT - EMIB is a simple parallel IO circuitry for lower power and lower latency and larger scalability
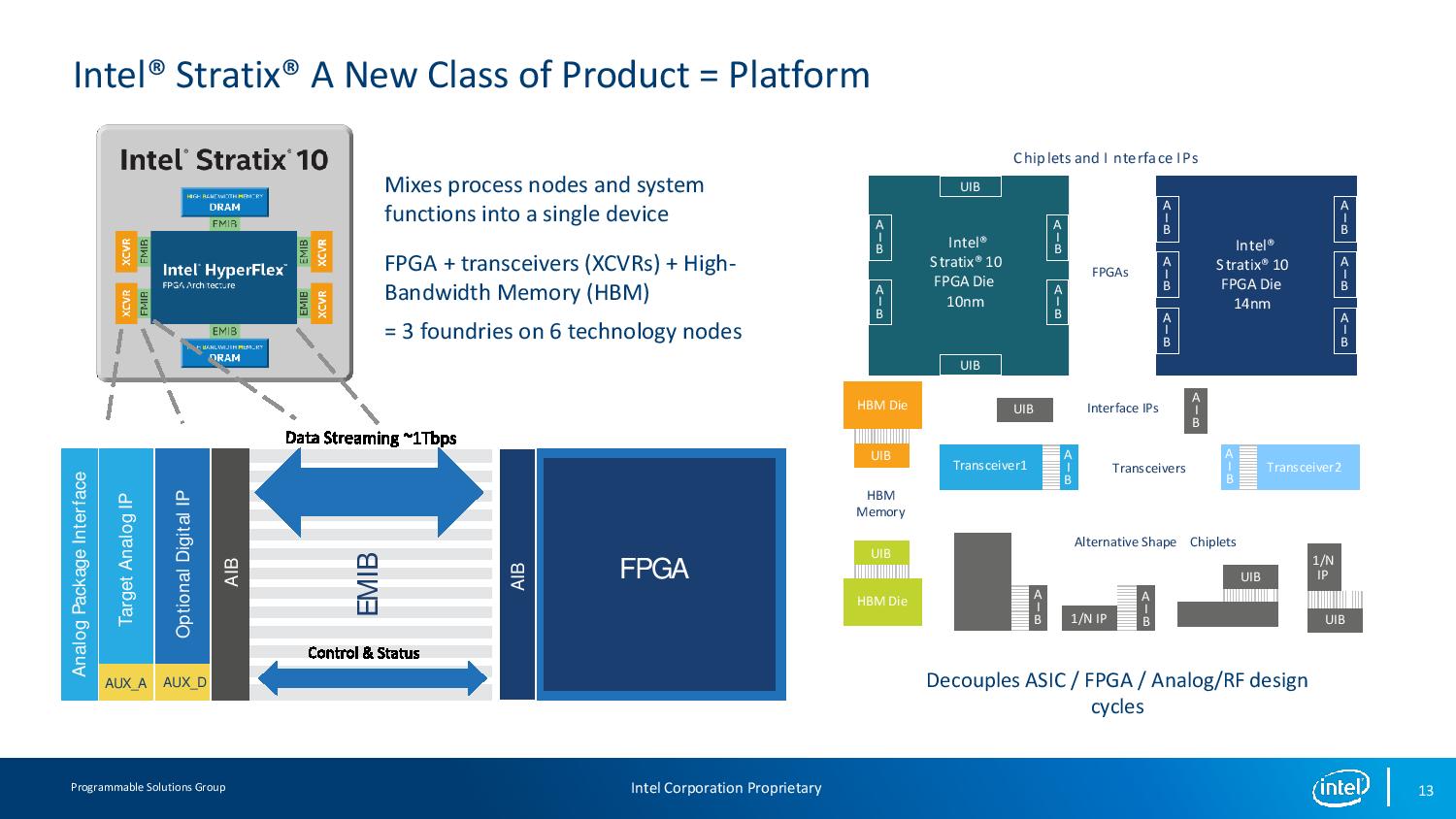
12:01PM EDT - AIB a small sliver for communication and data streaming at 1 Tbps
12:01PM EDT - AIB on chiplet and AIB on FPGA. Now it becomes a Lego system. Stick what you need together when the AIB is standard
12:01PM EDT - Chiplets can be large or small as whatever is needed. Chiplets can have multiple AIBs to connect to other silicon.
12:01PM EDT - Also use multi-foundry and multi-node
12:02PM EDT - for noise isolation, superior for analog vs monolithic
12:02PM EDT - proven on 3 foundries on 6 tech nodes

12:03PM EDT - Chiplets are functional IP blocks in a physical form - in effect a building block
12:03PM EDT - Platform needs simple composition rules
12:03PM EDT - So AIB and UIB

12:03PM EDT - Perhaps there are a couple of different classes of applications
12:04PM EDT - UIB is general purpose SiP for HBM/ASIC
12:04PM EDT - AIB for transciever and analog/RF
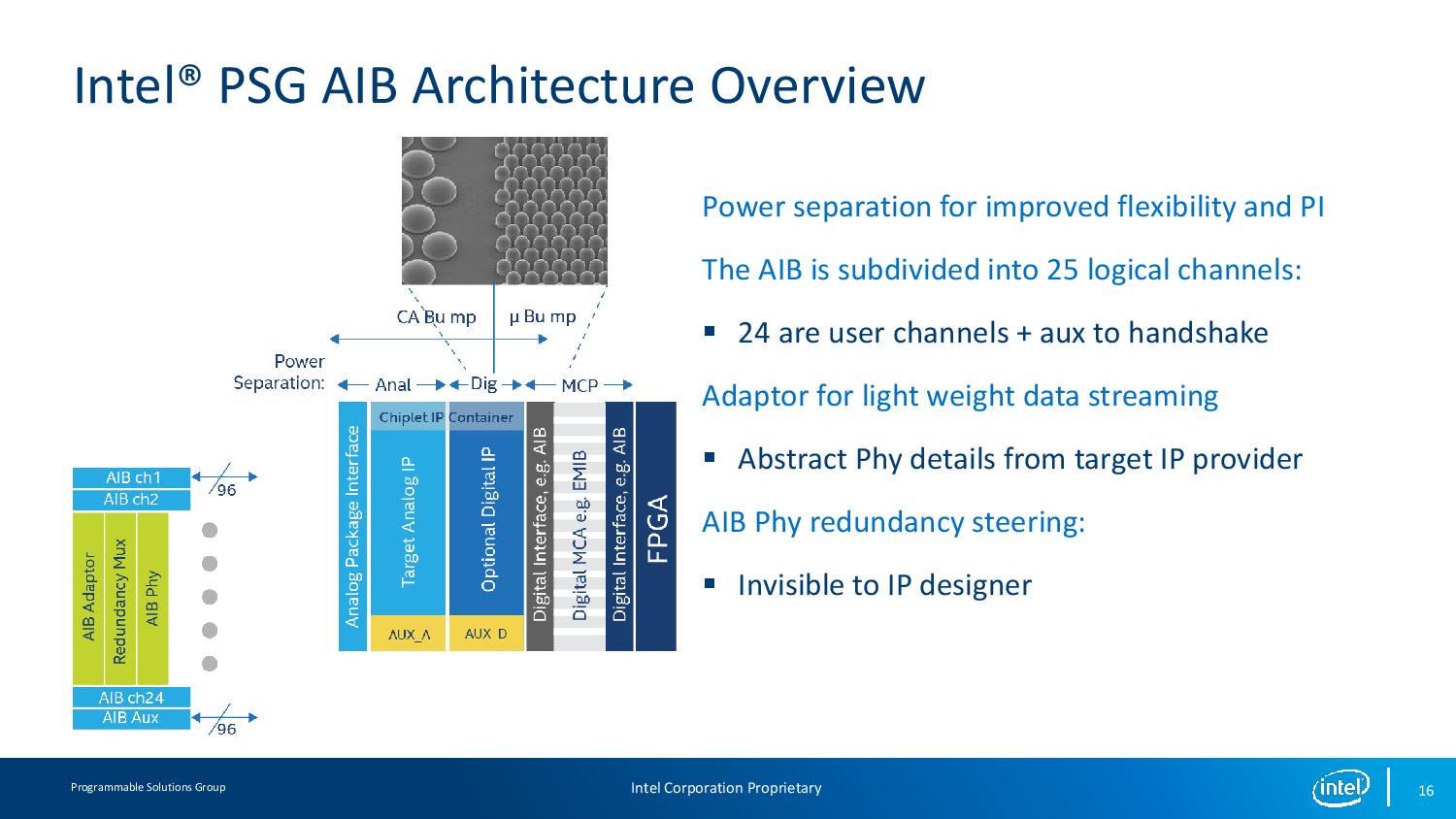
12:05PM EDT - AIB has 25 logical channels - 24 for user, one for handshake
12:05PM EDT - adaptor for light weight data streaming and redundancy steering
12:06PM EDT - IP designer can focus on IP design, rather than connectivity

12:07PM EDT - Create dies with AIB and UIB ports, then play lego to create a family of products
12:07PM EDT - Modular platform enables cost-effective upgrades. No need to respin a die, just replace chiplets with other IP blocks
12:07PM EDT - e.g. new generation transceivers or new HBM. Reduces time to market

12:09PM EDT - Can now converge both process nodes and suitable cost
12:09PM EDT - 20K EMIB connections up to 2 Gbps each
12:09PM EDT - Reduces size, weight and power

12:10PM EDT - EMIB isn't about a particular product, but rolling out on Stratix first
12:10PM EDT - More use of EMIB through DARPA and 'Chips' (?)
12:11PM EDT - 'No company has a monopoly on innovation - we want to innovate with partners'
12:11PM EDT - Time for Q&A
12:12PM EDT - 'Q: How available is EMIB'
12:14PM EDT - 'A: Cost analysis makes yield of EMIB preferable over other technology. High-end and mid-range systems are coming from Intel using EMIB'
12:14PM EDT - 'Q: are there pitch bump limits'
12:15PM EDT - 'A: we're at 55 now, with 35 coming soon. We've seen as low as 10 micron in the lab'
12:17PM EDT - 'Q: Chiplets idea is good, but interposers are for high volume. Can I go to Intel and use their EMIB technology?'
12:18PM EDT - A: Intel has EMIB, but GloFo had interposer. Three foundries here, should drive the cost down. If the business model is right, Intel would build high-volume EMIB but there is no monopoly on high-density packaging technology
12:18PM EDT - 'Q: Is EMIB ready for prime time?'
12:19PM EDT - 'A: Yes, EMIB is in the field, and large volumes are coming and it is ready for prime time'
12:20PM EDT - 'Q: Can you get around bad dies before putting chiplets onto the package?' 'A: Yes'
12:21PM EDT - 'Q: Can you get around bad dies before putting chiplets onto the package?' 'A: Yes'
12:23PM EDT - 'Q: Can you get around bad dies before putting chiplets onto the package?' 'A: Yes'
12:23PM EDT - That's a wrap. Xilinx are now doing a talk on a new 16nm FPGA with HBM and CCIX








51 Comments
View All Comments
Dr. Swag - Tuesday, August 22, 2017 - link
*4Dr. Swag - Tuesday, August 22, 2017 - link
Actually no you're right. I was thinking about epyc instead of the pic they published :pname99 - Tuesday, August 22, 2017 - link
Not to be an Apple fanboy, but what is new here compared to, say, the packaging used by the Apple Watch S1 and S2 packages?https://www.ifixit.com/Teardown/Apple+Watch+X-ray+...
What it looks like to me (I'd be happy to be corrected) is
- the essential idea is not new, not specific to Intel
- the pitches are not especially extreme compared to what Apple has done
BUT
- maybe substantially cheaper than Apple (? but I suspect this is unlikely)
- maybe substantially more pins, or faster than Apple (? this is definitely possible)
More significant seem to me two points that Intel seems to be begrudging in how strongly it is pushing them
- this tech moving to the high end.
Intel wants to portrait this as a great step forward, mix and match technology, blah blah. MY GUESS is that it's making lemonade out of lemons. All the advantages and possibilities of this tech were available at the costs the high end is willing to pay a few years ago. If they weren't adopted, it's because staying on-die was more appealing (?)
Moving off-die in this way looks to me like something Intel has been forced to do (maybe because of upcoming EUV focussable area limitations, maybe yield issues, maybe fear of how they will be forced to be more cost competitive soon in the many-core market).
- Intel's claims to be pushing this as a standard. I think we can all agree that a standard is desirable, and would be appreciated by everyone (including Apple and all the other phone makers, watch makers, wireless headphone makers etc). The question is how honest Intel is about really pushing this as a standard. For every USB they've pushed, there's also been a Thunderbolt -- choices made (deliberately or foolishly) that have caused prices to be way higher than necessary and have prevented mass adoption.
I can see Intel management saying that no way ARM should get to benefit from their design effort and so making choices that mean that, for all their talk of standardization and multiple foundries, the reality is that in a year the ARM eco-system announces their own equivalent of EMIB, perhaps slightly less performant but WAY cheaper, more flexible, and a better match to standard ARM protocols.
Ian Cutress - Tuesday, August 22, 2017 - link
S1 is like mobile and using Package on Package. PoP uses microbumps around an SoC to keep x/y dimensions on a PCB small and minimise distance for data to travel. PoP is used extensively in mobile. PoP works when thermals are suitable, and usually used for DRAM, but you're still limited by copper connections through a package. EMIB is different.name99 - Tuesday, August 22, 2017 - link
How is it different? What I mean is, what does it enable that's different from existing PoP and similar tech?I'm not trying to be bitchy here, I'm trying to get at what's supposedly new here. I've given my analysis (based, I'll admit, on limited knowledge) and I'm trying to get at what aspects of that analysis are and are not correct.
It sounds like what you are saying is that this
- is different from PoP because PoP ALWAYS involves only perimeter micro-bumps and this involves area micro-bumps (so allows for many more connections)
- is different from interposer how? As far as I can tell, the only difference is that it's smaller than traditional interposers.
When Intel first announced this, *I* thought the big deal, the significant difference they had compared to PoP or interposers, was the provision of some level of logic (eg for routing or signal shaping/equalization/translation purposes) within the sliver of silicon. Hence the name Embedded Multi-Die Interconnect BRIDGE.
And that would be cute and likely valuable.
But they've said nothing in this presentation to sustain that interpretation.
extide - Tuesday, August 22, 2017 - link
EMIB is different because it can pack a LOT more connections into the same space. Essentially the bumps are a LOT smaller. It's like using an interposer, except cheaper because you only need those small EMIB dies whee you need the high density interconnects instead of underneath the whole thing.extide - Tuesday, August 22, 2017 - link
To expand on that EMIB gets you the performance advantages of an interposer, but is much cheaper because you only need those little tiny dies, instead of a giant interposer that is as big as the area of all of the dies on top. An interposer is essentially a partially processed die, so THAT is the reticle limit they are talking about. Giant interposer = expensive, yield issues, hard to manufacture, etc.edzieba - Wednesday, August 23, 2017 - link
On top of that, the EMIB bridges all have pads on only one face, so can be built using a normal process. An interposer requires pads on both sides, which means extensive usage of TSVs across a massive die area.melgross - Tuesday, August 22, 2017 - link
Whatever the exact method, it’s just a matter of trying to save money, and lower costs. Chips are just getting too big, which means lower yields. I would add that, as I think you mentioned (without having to go back to verify it), this also helps thermals.ats - Tuesday, August 22, 2017 - link
Besides the fact that it is completely different....S1/S2 are basically PoP designs where interconnect bandwidth isn't an issue and signalling density is extremely low.
The closest thing to EMIB is Si Interposers where you are going for extremely high interconnect bandwidths and densities. Si Interposers though have their limitations, requiring TSVs for external connectivity and having limitations on package size based on reticle limits. EMIB gives all the advantages of Si Interposers with basically none of the down sides.
The EMIB dies just need to bridge between two chips and therefore can be extremely small, and because you can use multiple EMIB, you aren't limited to things like reticle limits allowing rather large scale multi die designs. In addition, external connections work just like is any other basic packaging technology and don't require TSV (which add a lot of process steps and risk).
To put things in perspective, one EMIB connection has an orders of magnitude higher interconnect bandwidth than the entire S1/S2 package has between all its connections. Each EMIB is capable of Tbps bandwidth.